Puedes usar la API de RunInference para crear canalizaciones que contengan varios modelos. Las canalizaciones de varios modelos son útiles para tareas como las pruebas A/B y la compilación de ensambles a fin de resolver problemas empresariales que requieren más de un modelo de AA.
Usa varios modelos
En los siguientes ejemplos de código, se muestra cómo usar la transformación RunInference para agregar varios modelos a tu canalización.
Cuando compilas canalizaciones con varios modelos, puedes usar uno de dos patrones:
- Patrón de rama A/B: Una parte de los datos de entrada va a un modelo y el resto de datos se dirige a un segundo modelo.
- Patrón de secuencia: Los datos de entrada recorren dos modelos, uno después del otro.
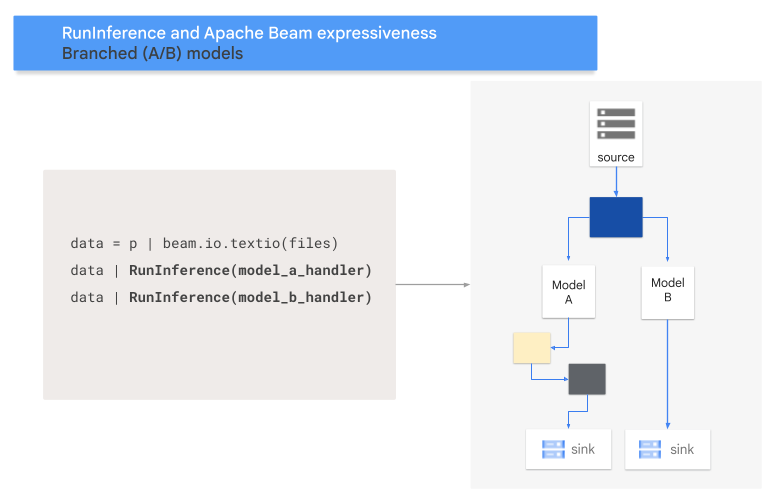
Patrón A/B
En el siguiente código, se muestra cómo agregar un patrón A/B a la canalización con la transformación RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A y MODEL_HANDLER_B son el código de configuración del controlador de modelos.
En el siguiente diagrama, se proporciona una presentación visual de este proceso.
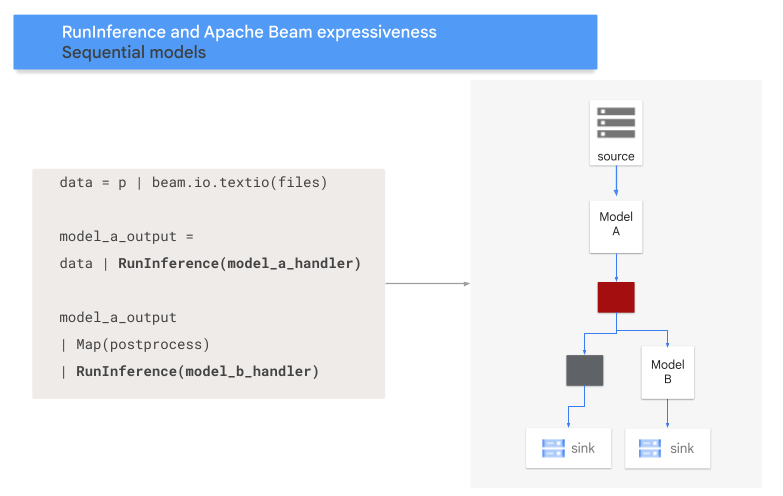
Patrón de secuencia
En el siguiente código, se muestra cómo agregar un patrón de secuencia a tu canalización con la transformación RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A y MODEL_HANDLER_B son el código de configuración del controlador de modelos.
En el siguiente diagrama, se proporciona una presentación visual de este proceso.
Asigna modelos a claves
Puedes cargar varios modelos y asignarlos a claves mediante un controlador de modelos con clave.
La asignación de modelos a claves permite usar modelos diferentes en la misma transformación RunInference.
En el siguiente ejemplo, se usa un controlador de modelos con clave que carga un modelo mediante CONFIG_1 y un segundo modelo mediante CONFIG_2.
La canalización usa el modelo asociado con CONFIG_1 para ejecutar la inferencia en ejemplos asociados con KEY_1.
El modelo asociado con CONFIG_2 ejecuta la inferencia en los ejemplos asociados con KEY_2 y KEY_3.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
Para ver un ejemplo más detallado, consulta Ejecuta la inferencia de AA con varios modelos entrenados de forma diferente.
Cómo administrar la memoria
Cuando cargas varios modelos al mismo tiempo, es posible que se produzcan errores de memoria insuficiente (OOM). Cuando usas un controlador de modelos con clave, Apache Beam no limita de forma automática la cantidad de modelos que se cargan en la memoria. Cuando no todos los modelos caben en la memoria, se produce un error de memoria insuficiente y la canalización falla.
Para evitar este problema, usa el parámetro max_models_per_worker_hint para limitar la cantidad de modelos que se cargan en la memoria al mismo tiempo. En el siguiente ejemplo, se usa un controlador de modelo con clave con el parámetro max_models_per_worker_hint.
Debido a que el valor del parámetro max_models_per_worker_hint se configuró como 2, la canalización carga un máximo de dos modelos en cada proceso de trabajador del SDK al mismo tiempo.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
Cuando diseñes tu canalización, asegúrate de que los trabajadores tengan suficiente memoria para los modelos y las transformaciones de canalización. Debido a que es posible que la memoria que usan los modelos no se libere de inmediato, para evitar OOM, incluye un búfer de memoria adicional.
Si tienes muchos modelos y usas un valor bajo con el parámetro max_models_per_worker_hint, es posible que experimentes una hiperpaginación de memoria. La hiperpaginación de memoria ocurre cuando se usa un tiempo de ejecución excesivo para intercambiar modelos dentro y fuera de la memoria. Para evitar este problema, incluye una transformación GroupByKey en la canalización antes del paso de inferencia. La transformación GroupByKey garantiza que los elementos con la misma clave y el mismo modelo se encuentren en el mismo trabajador.
Más información
- Lee sobre las canalizaciones de varios modelos en la documentación de Apache Beam
- Ejecuta la inferencia de AA con varios modelos entrenados de forma diferente.
- Ejecuta un notebook interactivo en Colab.