이 페이지에서는 MLTransform 특성을 사용하여 머신러닝(ML) 모델을 학습시킬 수 있는 데이터를 준비하는 이유와 방법을 설명합니다. 특히 이 페이지에서는 MLTransform을 사용해 임베딩을 생성하여 데이터를 처리하는 방법을 보여줍니다.
한 클래스에 여러 데이터 처리 변환을 결합하면 MLTransform에서 Apache Beam ML 데이터 처리 작업을 워크플로에 적용하는 프로세스를 간소화합니다.
MLTransform을 사용합니다.
임베딩 개요
임베딩은 최신 시맨틱 검색 및 검색 증강 생성(RAG) 애플리케이션에서 핵심적인 역할을 합니다. 임베딩을 사용하면 시스템이 더 깊고 개념적인 수준에서 정보를 이해하고 상호작용할 수 있습니다. 시맨틱 검색에서 임베딩은 쿼리와 문서를 벡터 표현으로 변환합니다. 이러한 표현은 기본 의미와 관계를 포착할 수 있도록 합니다. 이를 통해 키워드가 정확하게 일치하지 않아도 관련성 높은 결과를 찾을 수 있습니다. 이는 표준 키워드 기반 검색을 뛰어넘는 큰 발전입니다. 또한 임베딩은 제품 추천에도 사용할 수도 있습니다. 여기에는 이미지와 텍스트를 함께 사용하는 멀티모달 검색, 로그 분석, 중복 제거와 같은 작업이 포함됩니다.
RAG에서는 임베딩이 기술 자료에서 가장 관련성 높은 컨텍스트를 검색하여 대규모 언어 모델(LLM)의 응답 생성에 핵심적인 역할을 합니다. RAG 시스템은 사용자 질문과 기술 자료의 정보 조각을 모두 임베딩하여, 의미적으로 가장 유사한 항목을 효율적으로 식별하고 검색합니다. 이렇게 시맨틱 매칭된 정보를 기반으로 LLM은 보다 정확하고 유익한 답변을 생성할 수 있습니다.
임베딩을 위한 데이터 수집 및 처리
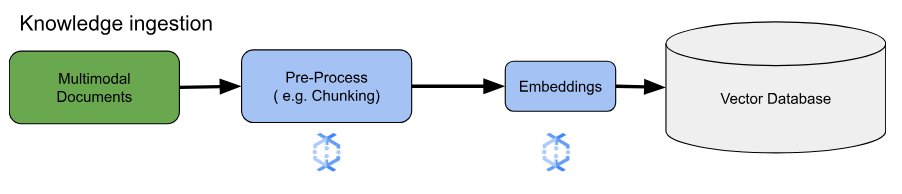
임베딩의 핵심 사용 사례에서는 지식을 어떻게 수집하고 처리할지가 가장 중요한 고려 사항입니다. 이 수집은 배치 방식일 수도 있고, 스트리밍 방식일 수도 있습니다. 지식의 소스 또한 매우 다양할 수 있습니다. 예를 들어 Cloud Storage에 저장된 파일이 될 수도 있고, Pub/Sub 또는 Google Cloud의 Apache Kafka 관리형 서비스와 같은 스트리밍 소스에서 시작될 수도 있습니다.
스트리밍 소스의 경우 데이터 자체는 일반 텍스트와 같은 원시 콘텐츠일 수도 있고, 문서를 가리키는 URI일 수도 있습니다. 소스와 관계없이, 첫 번째 단계는 일반적으로 정보를 전처리하는 것입니다. 원시 텍스트의 경우에는 간단한 데이터 정리 작업만으로 충분할 수 있습니다. 하지만 문서가 크거나 콘텐츠가 복잡한 경우에는 청킹이 중요한 단계입니다. 청킹이란 소스 자료를 더 작고 다루기 수윈 단위로 나누는 작업입니다. 어떤 방식으로 청킹할지는 표준화된 방법이 없으며, 사용하는 데이터와 적용 사례에 따라 달라집니다. Dataflow 같은 플랫폼은 다양한 청킹 요구를 처리할 수 있는 내장 기능을 제공하여, 이 필수적인 전처리 단계를 보다 쉽게 수행할 수 있도록 도와줍니다.
이점
MLTransform 클래스는 다음과 같은 이점을 제공합니다.
- 데이터를 벡터 데이터베이스로 푸시하거나 추론을 실행하는 데 사용할 수 있는 임베딩을 생성합니다.
- 복잡한 코드를 작성하거나 기본 라이브러리를 관리하지 않고도 데이터를 변환할 수 있습니다.
- 인터페이스 하나에서 여러 유형의 처리 작업을 효율적으로 연결할 수 있습니다.
지원 및 제한 사항
MLTransform 클래스에는 다음과 같은 제한사항이 있습니다.
- Apache Beam Python SDK 버전 2.53.0 이상을 사용하는 파이프라인에서 사용 가능합니다.
- 파이프라인에서 기본 기간을 사용해야 합니다.
텍스트 임베딩 변환:
- Python 3.8, 3.9, 3.10, 3.11, 3.12를 지원합니다.
- 일괄 및 스트리밍 파이프라인을 모두 지원합니다.
- Vertex AI 텍스트 임베딩 API 및 Hugging Face Sentence Transformers 모듈을 지원합니다.
사용 사례
예시 메모장에서는 특정 사용 사례에 MLTransform를 사용하는 방법을 보여줍니다.
- Vertex AI를 사용하여 LLM의 텍스트 임베딩 생성
- Vertex AI 텍스트 임베딩 API와 함께 Apache Beam
MLTransform클래스를 사용하여 텍스트 임베딩을 생성합니다. 텍스트 임베딩은 텍스트를 숫자 벡터로 표현하기 위한 방법으로, 많은 자연어 처리(NLP) 작업에 필요합니다. - Hugging Face를 사용하여 LLM의 텍스트 임베딩 생성
- Hugging Face Hub 모델과 함께 Apache Beam
MLTransform클래스를 사용하여 텍스트 임베딩을 생성합니다. Hugging FaceSentenceTransformers프레임워크는 Python을 사용하여 문장, 텍스트, 이미지 임베딩을 생성합니다. - 텍스트 임베딩을 생성하여 PostgreSQL용 AlloyDB에 수집
- Hugging Face Hub 모델과 함께 Apache Beam, 특히
MLTransform클래스를 사용하여 텍스트 임베딩을 생성합니다. 이후,VectorDatabaseWriteTransform를 사용해 생성된 임베딩과 관련 메타데이터를 PostgreSQL용 AlloyDB에 로드합니다. 이 노트북에서는 Beam을 활용해 PostgreSQL용 AlloyDB 벡터 데이터베이스에 데이터를 채우는 확장 가능한 일괄 및 스트리밍 파이프라인을 빌드하는 방법을 보여줍니다. 여기에는 Pub/Sub나 기존 데이터베이스 테이블과 같은 다양한 소스로부터 데이터를 처리하고, 커스텀 스키마를 만들고, 데이터를 업데이트하는 작업이 포함됩니다. - 텍스트 임베딩을 생성하여 BigQuery에 수집
- Hugging Face Hub 모델과 함께 Apache Beam
MLTransform클래스를 사용하여 제품 카탈로그와 같은 애플리케이션 데이터로부터 텍스트 임베딩을 생성합니다. 이를 위해 Apache BeamHuggingfaceTextEmbeddings변환이 사용됩니다. 이 변환은 문장 및 텍스트 임베딩 생성을 위한 모델을 제공하는 Hugging Face SentenceTransformers 프레임워크를 사용합니다. 이렇게 생성된 임베딩과 관련 메타데이터는 Apache BeamVectorDatabaseWriteTransform을 사용하여 BigQuery에 수집됩니다. 이 노트북에서는 보강 변환을 사용해 BigQuery에서 벡터 유사도 검색을 수행하는 방법도 함께 설명합니다.
사용 가능한 변환의 전체 목록은 Apache Beam 문서에서 변환을 참조하세요.
임베딩 생성을 위한 MLTransform 사용
MLTransform 클래스를 사용하여 정보를 청킹하고 임베딩을 생성하려면 파이프라인에 다음 코드를 포함합니다.
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
앞선 예시에서는 각 요소를 하나의 청크로 만들었지만, 대신 LangChain을 사용하여 여러 개의 청크로 나눌 수도 있습니다.
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
다음 단계
- "Dataflow ML로 실시간 시맨틱 검색 및 RAG 애플리케이션을 사용 설정하는 방법" 블로그 게시물을 읽어보세요.
MLTransform에 대한 자세한 내용은 Apache Beam 문서의 데이터 전처리를 참조하세요.- 더 많은 예시는 Apache Beam 변환 카탈로그의 데이터 처리를 위한
MLTransform을 참조하세요. - Colab에서 대화형 노트북 실행하기