Cette page explique pourquoi et comment utiliser la fonctionnalité MLTransform pour préparer vos données à l'entraînement de modèles de machine learning (ML). Plus précisément, cette page vous montre comment traiter des données en générant des embeddings à l'aide de MLTransform.
En combinant plusieurs transformations de traitement de données dans une même classe, MLTransform simplifie le processus d'application des opérations de traitement de données Apache Beam à votre workflow.
MLTransform dans l'étape de prétraitement du workflow.
Présentation des embeddings
Les embeddings sont essentiels pour les applications modernes de recherche sémantique et de génération augmentée par récupération (RAG). Les embeddings permettent aux systèmes de comprendre les informations et d'interagir avec elles à un niveau plus profond et plus conceptuel. Dans la recherche sémantique, les embeddings transforment les requêtes et les documents en représentations vectorielles. Ces représentations capturent leur signification et leurs relations sous-jacentes. Vous pouvez ainsi trouver des résultats pertinents même lorsque les mots clés ne correspondent pas directement. Il s'agit d'une avancée considérable par rapport à la recherche standard basée sur les mots clés. Vous pouvez également utiliser des embeddings pour les recommandations de produits. Cela inclut les recherches multimodales qui utilisent des images et du texte, l'analyse des journaux et les tâches telles que la déduplication.
Dans la génération augmentée par récupération (RAG), les embeddings jouent un rôle crucial dans la récupération du contexte le plus pertinent à partir d'une base de connaissances pour ancrer les réponses des grands modèles de langage (LLM). En intégrant à la fois la requête de l'utilisateur et les blocs d'informations de la base de connaissances, les systèmes RAG peuvent identifier et récupérer efficacement les éléments les plus proches sémantiquement. Cette correspondance sémantique garantit que le LLM a accès aux informations nécessaires pour générer des réponses précises et informatives.
Ingérer et traiter des données pour les embeddings
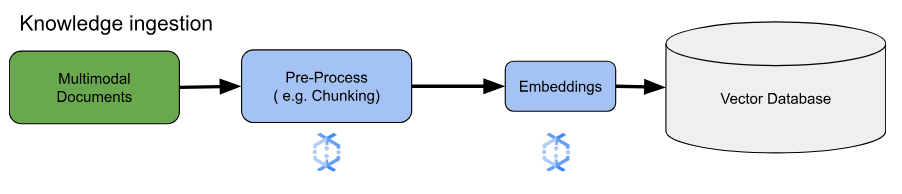
Pour les principaux cas d'utilisation de l'intégration, la principale considération est la façon d'ingérer et de traiter les connaissances. Cette ingestion peut se faire par lots ou par flux. La source de ces connaissances peut varier considérablement. Par exemple, ces informations peuvent provenir de fichiers stockés dans Cloud Storage ou de sources de flux de données comme Pub/Sub ou Google Cloud Managed Service pour Apache Kafka.
Pour les sources de flux, les données elles-mêmes peuvent être le contenu brut (par exemple, du texte brut) ou des URI pointant vers des documents. Quelle que soit la source, la première étape consiste généralement à prétraiter les informations. Pour le texte brut, cela peut être minimal, comme un nettoyage de base des données. Toutefois, pour les documents plus volumineux ou les contenus plus complexes, une étape cruciale est le chunking. Le chunking consiste à diviser le contenu source en unités plus petites et plus faciles à gérer. La stratégie de segmentation optimale n'est pas standardisée et dépend des données et de l'application spécifiques. Les plates-formes comme Dataflow offrent des fonctionnalités intégrées pour répondre à divers besoins de segmentation, ce qui simplifie cette étape de prétraitement essentielle.
Avantages
La classe MLTransform offre les avantages suivants :
- Génère des embeddings que vous pouvez utiliser pour transférer des données vers des bases de données vectorielles ou pour exécuter des inférences.
- Transformez vos données sans écrire de code complexe ni gérer de bibliothèques sous-jacentes.
- Associez efficacement plusieurs types d'opérations de traitement à une seule interface.
Compatibilité et limites
La classe MLTransform présente les limites suivantes :
- Disponible pour les pipelines qui utilisent le SDK Apache Beam pour Python version 2.53.0 et ultérieure.
- Les pipelines doivent utiliser des fenêtres par défaut.
Transformations d'embeddings textuels :
- Compatibilité avec Python 3.8, 3.9, 3.10, 3.11 et 3.12.
- Ils sont compatibles avec les pipelines de traitement par lot et par flux.
- Elles sont compatibles avec l'API Vertex AI d'embeddings de texte et le module Sentence Transformers de Hugging Face.
Cas d'utilisation
Les exemples de notebooks montrent comment utiliser MLTransform pour des cas d'utilisation spécifiques.
- Je souhaite générer des embeddings de texte pour mon LLM à l'aide de Vertex AI
- Utilisez la classe
MLTransformApache Beam avec l'API Vertex AI d'embeddings de texte pour générer des embeddings de texte. Les embeddings de texte permettent de représenter du texte sous forme de vecteurs numériques, ce qui est nécessaire pour de nombreuses tâches de traitement du langage naturel (TLN). - Je souhaite générer des embeddings de texte pour mon LLM à l'aide de Huging Face
- Utilisez la classe
MLTransformd'Apache Beam avec les modèles du hub Hugging Face pour générer des embeddings de texte. Le frameworkSentenceTransformersde Huging Face permet de générer des phrases, du texte et des embeddings d'images à l'aide de Python. - Je souhaite générer des embeddings de texte et les ingérer dans AlloyDB pour PostgreSQL
- Utilisez Apache Beam, en particulier sa classe
MLTransformavec les modèles du Hub Hugging Face, pour générer des embeddings de texte. Ensuite, utilisezVectorDatabaseWriteTransformpour charger ces embeddings et les métadonnées associées dans AlloyDB pour PostgreSQL. Ce notebook montre comment créer des pipelines de données Beam évolutifs par lot et en flux continu pour remplir une base de données vectorielle AlloyDB pour PostgreSQL. Cela inclut la gestion des données provenant de diverses sources, telles que Pub/Sub ou des tables de base de données existantes, la création de schémas personnalisés et la mise à jour des données. - Je souhaite générer des embeddings de texte et les ingérer dans BigQuery.
- Utilisez la classe
MLTransformd'Apache Beam avec les modèles du Hub Hugging Face pour générer des embeddings de texte à partir de données d'application, comme un catalogue de produits. Pour cela, nous utilisons la transformationHuggingfaceTextEmbeddingsApache Beam. Cette transformation utilise le framework SentenceTransformers de Hugging Face, qui fournit des modèles pour générer des embeddings de phrases et de texte. Ces embeddings générés et leurs métadonnées sont ensuite ingérés dans BigQuery à l'aide d'Apache BeamVectorDatabaseWriteTransform. Le notebook montre également comment effectuer des recherches de similarité vectorielle dans BigQuery à l'aide de la transformation "Enrichissement".
Pour obtenir la liste complète des transformations disponibles, consultez la section Transformations de la documentation Apache Beam.
Utiliser MLTransform pour générer des embeddings
Pour utiliser la classe MLTransform afin de segmenter les informations et de générer des embeddings, incluez le code suivant dans votre pipeline :
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
L'exemple précédent crée un seul bloc par élément, mais vous pouvez également utiliser LangChain pour créer des blocs :
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
Étapes suivantes
- Consultez l'article de blog "How to enable real time semantic search and RAG applications with Dataflow ML" (Comment activer la recherche sémantique et les applications RAG en temps réel avec Dataflow ML).
- Pour en savoir plus sur
MLTransform, consultez Prétraiter des données dans la documentation Apache Beam. - Pour plus d'exemples, consultez la section
MLTransformpour le traitement des données dans le catalogue de transformations Apache Beam. - Exécutez un notebook interactif dans Colab.