다음 데이터 애셋을 검색할 수 있습니다.
- Analytics Hub 연결된 데이터 세트
- BigQuery 데이터 세트, 테이블, 뷰, 모델
- Bigtable 인스턴스, 클러스터, 테이블 (column family 세부정보 포함)
- Data Catalog 태그 템플릿, 항목 그룹, 커스텀 항목
- Dataplex 레이크, 영역, 테이블, 파일 세트
- Dataproc Metastore 서비스, 데이터베이스, 테이블
- Pub/Sub 데이터 스트림
- Spanner 인스턴스, 데이터베이스, 테이블, 뷰
- Vertex AI 모델, 데이터 세트, Vertex AI Feature Store 리소스
- Data Catalog에 연결된 엔터프라이즈 데이터 사일로 애셋
검색 범위
사용자 권한에 따라 검색결과가 다르게 표시될 수 있습니다. Data Catalog 검색결과는 역할에 따라 범위가 지정됩니다.
Data Catalog에 사용할 수 있는 여러 유형의 IAM 역할 및 권한을 검토할 수 있습니다. 예를 들어 객체에 대해 BigQuery 메타데이터 읽기 액세스 권한이 있으면 해당 객체가 Data Catalog 검색 결과에 표시됩니다.
다음 목록에서는 검색을 실행하는 데 필요한 최소 권한을 설명합니다.
테이블을 검색하려면 해당 테이블에 대한
bigquery.tables.get권한이 필요합니다.데이터 세트를 검색하려면 해당 데이터 세트에 대한
bigquery.datasets.get권한이 필요합니다.데이터 세트 또는 테이블의 메타데이터를 검색하려면
roles/bigquery.metadataViewerIAM 역할이 필요합니다.프로젝트 또는 조직 내의 모든 리소스를 검색하려면
datacatalog.catalogs.searchAll권한이 필요합니다. 소스 시스템과 관계없이 모든 리소스에 작동합니다.
BigQuery 테이블에 대해 액세스 권한이 있지만 이 테이블을 포함하는 데이터 세트에 대해서는 액세스 권한이 없는 경우에도 예상한 대로 테이블이 Data Catalog 검색에 표시됩니다. 동일한 액세스 로직이 Pub/Sub 및 Data Catalog 자체와 같이 지원되는 모든 시스템에 적용됩니다.
검색의 재현율 문제
Data Catalog 검색어는 전체 재현율을 보장하지 않습니다. 후속 결과 페이지에서도 검색어와 일치하는 결과가 반환되지 않을 수 있습니다. 또한 검색어를 반복하면 반환된 (및 반환되지 않는) 결과가 달라질 수 있습니다.
재현율 문제가 발생하여 특정 순서로 결과를 가져올 필요가 없으면 catalog.search 메서드를 호출할 때 orderBy 매개변수를 default를 설정하는 것이 좋습니다.
admin_search 플래그 사용
검색 요청에 admin_search 플래그를 사용하면 전체 재현율이 보장됩니다.
관리자 검색에는 검색 범위의 모든 프로젝트 및 조직에 datacatalog.catalogs.searchAll 권한을 설정해야 합니다. admin_search를 사용하면 default orderBy만 허용됩니다.
날짜로 샤딩된 테이블
Data Catalog는 날짜로 샤딩된 테이블을 단일 논리 항목으로 집계합니다. 이 항목에는 가장 최근 날짜의 테이블 샤드와 동일한 스키마가 있으며 총 샤드 수에 대한 집계 정보가 포함됩니다. 이 항목은 항목이 속한 데이터 세트에서 액세스 수준을 가져옵니다. Data Catalog 검색에는 사용자에게 해당 항목이 포함된 데이터 세트에 대한 액세스 권한이 있는 경우에만 이러한 논리적 항목이 표시됩니다. 날짜로 샤딩된 개별 테이블은 데이터 카탈로그에 있고 태그를 지정할 수 있더라도 Data Catalog 검색에 표시되지 않습니다.
필터
필터를 사용하면 검색결과 범위를 좁힐 수 있습니다. 모든 필터는 다음과 같은 섹션별로 그룹화됩니다.
- 범위에서는 별표표시된 항목으로만 검색을 제한합니다.
- 시스템은 BigQuery, Pub/Sub, Dataplex, Dataproc Metastore, 커스텀 시스템, Vertex AI, Data Catalog 자체입니다. Data Catalog 시스템에는 파일 세트 및 커스텀 항목이 포함됩니다.
- 레이크 및 영역은 Dataplex에서 가져옵니다.
- 데이터 스트림, 데이터 세트, 레이크, 영역, 파일 세트, 모델, 테이블, 뷰, 서비스, 데이터베이스, 커스텀 유형과 같은 데이터 유형입니다.
- 프로젝트에는 사용할 수 있는 모든 프로젝트가 나열됩니다.
- 태그에는 사용할 수 있는 모든 태그 템플릿 (및 개별 필드)이 나열됩니다.
- 데이터 세트는 BigQuery 및 Vertex AI에서 가져옵니다.
- 공개 데이터 세트는 BigQuery에서 공개적으로 사용할 수 있는 데이터입니다.
여러 섹션의 필터를 조합하여 선택한 모든 섹션에서 하나 이상의 조건과 일치하는 자산을 찾을 수 있습니다. 단일 섹션 내에서 선택한 여러 필터는 OR 논리 연산자를 사용하여 평가됩니다. 예를 들어 다음과 같은 필터 조합을 살펴보겠습니다.
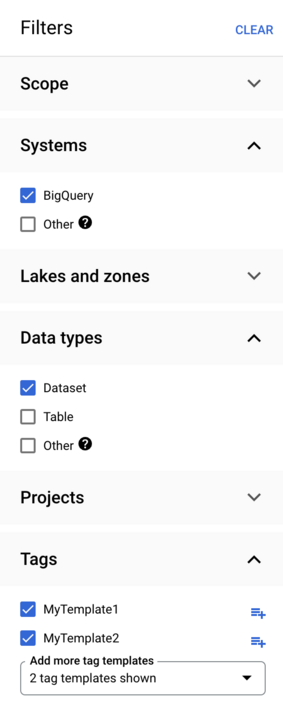
Data Catalog는 다음을 찾습니다.
MyTemplate1템플릿으로 태그된 BigQuery 데이터 세트MyTemplate2템플릿으로 태그된 BigQuery 데이터 세트MyTemplate1템플릿으로 태그된 BigQuery 테이블MyTemplate2템플릿으로 태그된 BigQuery 테이블
태그 값별로 필터링
태그 필터를 사용하면 특정 템플릿을 사용하여 태그된 애셋을 쿼리할 수 있습니다. 맞춤설정 메뉴를 사용하여 결과를 미세 조정하고 특정 태그 값으로 필터링할 수 있습니다. 태그 값 필터 조건은 해당 태그 필드의 데이터 유형에 따라 달라집니다. 예를 들어 날짜 및 시간 필드와 숫자 필드의 경우 특정 날짜 또는 범위를 지정할 수 있습니다.
필터 표시
모든 섹션에 표시되는 필터는 검색창에 있는 현재 검색어에 따라 다릅니다. 전체 검색 결과 집합에는 현재 검색어와 일치하는 항목이 포함될 수 있지만 이러한 항목에 해당하는 필터는 필터 창에 표시되지 않을 수 있습니다.
데이터 애셋 검색
콘솔
콘솔
Google Cloud 콘솔에서 Dataplex 검색 페이지로 이동합니다.
검색 플랫폼 선택에서 검색 모드로 Data Catalog를 선택합니다.
검색창에 검색어를 입력하거나 필터 창을 사용하여 검색 매개변수를 상세검색합니다.
다음 필터를 수동으로 추가할 수 있습니다.
- 프로젝트에서 프로젝트 필터를 추가합니다. 프로젝트 추가를 클릭하고 특정 프로젝트를 검색하여 선택한 다음 열기를 클릭합니다.
- 태그에서 태그 템플릿 필터를 추가합니다. 태그 템플릿 추가 메뉴를 클릭하고 특정 템플릿을 검색하여 선택한 다음 확인을 클릭합니다.
사용 가능한 애셋 외에도 Google Cloud 에서 공개적으로 사용할 수 있는 데이터 애셋을 검색하려면 공개 데이터 세트 포함을 선택합니다.
또한 다음을 수행할 수 있습니다.
검색창에서 검색어에 keyword:value를 추가하여 검색을 필터링합니다.
키워드 설명 name:일치하는 데이터 애셋 이름을 찾습니다. column:일치하는 열 이름 또는 중첩된 열 이름을 찾습니다. description:일치하는 테이블 설명을 찾습니다. 검색창에서 검색어에 다음 태그 키워드 프리픽스 중 하나를 추가하여 태그 검색을 수행합니다.
태그 설명 tag:project-name.tag_template_name일치하는 태그 이름을 찾습니다. tag:project-name.tag_template_name.key일치하는 태그 키를 찾습니다. tag:project-name.tag_template_name.key:value일치하는 태그 key:string value쌍을 찾습니다.
검색 표현식 팁
공백이 포함된 경우 검색 표현식을 인용부호('
search terms')로 묶습니다.키워드 앞에 'NOT'(모두 대문자 필요)을 붙이면
keyword:term필터의 논리적 부정과 일치하는 항목을 찾습니다. 또한 'AND' 및 'OR'(모두 대문자 필요) 불리언 연산자를 사용해서 검색 표현식을 조합할 수 있습니다.예를 들어
NOT column:term는 지정된 용어와 일치하는 열을 제외한 모든 열을 나열합니다. Data Catalog 검색 표현식에 사용할 수 있는 키워드와 기타 용어 목록은 Data Catalog 검색 문법을 참조하세요.
검색 예시
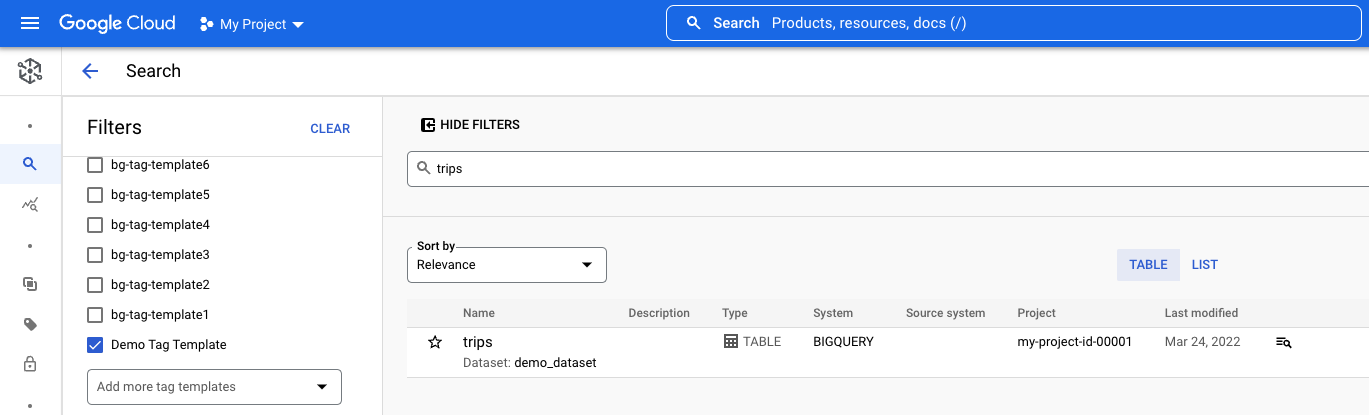
Data Catalog를 사용하여 BigQuery 테이블에 태그 지정에서 설정한 trips 테이블을 검색하려는 예를 살펴보겠습니다.
- 검색창에
trips를 입력하고 검색을 클릭합니다. 필터 창에서 다음을 선택합니다.
- 시스템 섹션에서 BigQuery를 선택하여 다른 시스템에 속한 이름이 같은 데이터 애셋을 제외합니다.
- 다른 프로젝트의 데이터 애셋을 제외하려면 프로젝트 섹션에서 프로젝트 ID를 선택합니다. 프로젝트가 표시되지 않으면 프로젝트 추가를 클릭하고 프로젝트를 선택합니다.
- 태그 섹션에서 데모 태그 템플릿을 선택하여 이 템플릿을 사용하는 태그가
trips테이블에 연결되었는지 확인합니다. 이 템플릿이 표시되지 않으면 태그 템플릿 추가를 클릭하고 태그 템플릿을 검색하여 선택한 다음 확인을 클릭합니다.
선택한 모든 필터를 사용하면 검색 결과에 Demo Tag Template 템플릿을 사용하는 태그가 연결된 프로젝트의 BigQuery trips 테이블 하나만 포함됩니다.
자바
이 샘플을 사용해 보기 전에 Data Catalog 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 Data Catalog Java API 참고 문서를 참조하세요.
Data Catalog에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 Data Catalog 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 Data Catalog Node.js API 참고 문서를 참조하세요.
Data Catalog에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
Python
이 샘플을 사용해 보기 전에 Data Catalog 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 Data Catalog Python API 참고 문서를 참조하세요.
Data Catalog에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 로컬 개발 환경의 인증 설정을 참조하세요.
REST 및 명령줄
REST
해당 언어의 Cloud 클라이언트 라이브러리에 액세스할 수 없거나 REST 요청을 사용하여 API를 테스트하려는 경우 다음 예시를 참고하고 Data Catalog REST API 문서를 참고하세요.
1. 카탈로그 검색
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- organization-id: GCP 조직 ID
- project-id: GCP 프로젝트 ID
HTTP 메서드 및 URL:
POST https://datacatalog.googleapis.com/v1/catalog:search
JSON 요청 본문:
{
"query":"trips",
"scope":{
"includeOrgIds":[
"organization-id"
]
}
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"results":[
{
"searchResultType":"ENTRY",
"searchResultSubtype":"entry.table",
"relativeResourceName":"projects/project-id/locations/US/entryGroups/@bigquery/entries/entry1-id",
"linkedResource":"//bigquery.googleapis.com/projects/project-id/datasets/demo_dataset/tables/taxi_trips"
},
{
"searchResultType":"ENTRY",
"searchResultSubtype":"entry.table",
"relativeResourceName":"projects/project-id/locations/US/entryGroups/@bigquery/entries/entry2-id",
"linkedResource":"//bigquery.googleapis.com/projects/project-id/datasets/demo_dataset/tables/tlc_yellow_trips_2018"
}
]
}
테이블 세부정보 보기
Data Catalog를 사용하여 테이블 세부정보를 확인합니다.
Google Cloud 콘솔에서 Dataplex 검색 페이지로 이동합니다.
검색 플랫폼 선택에서 검색 모드로 Data Catalog를 선택합니다.
검색창에 테이블이 있는 데이터 세트의 이름을 입력합니다.
예를 들어 Data Catalog를 사용하여 BigQuery 테이블에 태그 지정 빠른 시작을 완료한 경우
demo-dataset를 검색하고trips테이블을 선택할 수 있습니다.테이블을 클릭합니다.
BigQuery 테이블 세부정보 페이지가 열립니다.
테이블 세부정보에는 다음 섹션이 포함됩니다.
BigQuery 테이블 세부정보. 생성 시간, 마지막 수정 시간, 만료 시간, 리소스 URL, 라벨 등의 정보가 포함됩니다.
태그. 적용된 태그를 나열합니다. 이 페이지에서 태그를 수정하고 태그 템플릿을 볼 수 있습니다. 작업 아이콘을 클릭합니다.
스키마 및 열 태그. 적용된 스키마와 해당 값이 나열됩니다.
즐겨찾는 항목 별표표시 및 검색
동일한 데이터 애셋을 자주 탐색하는 경우 해당 항목을 별표표시하여 맞춤설정 목록에 포함할 수 있습니다.
Google Cloud 콘솔에서 Dataplex 검색 페이지로 이동합니다.
검색 플랫폼 선택에서 검색 모드로 Data Catalog를 선택합니다.
애셋을 찾은 다음 다음 두 가지 방법 중 하나로 항목에 별표표시합니다.
- 검색 결과에서 항목 옆에 있는 를 클릭합니다.
- 항목 이름을 클릭하여 세부정보 페이지를 열고 상단에 있는 작업 모음에서 별표를 클릭합니다.
최대 200개의 항목에 별표표시할 수 있습니다.
별표표시된 항목은 검색창에 검색어를 입력하기 전에 검색 페이지의 별표표시된 항목 목록에 나타납니다. 이 목록은 본인만 볼 수 있습니다.
별표표시된 항목만 검색하려면 필터 창의 범위 섹션에서 별표표시를 선택합니다.
Data Catalog API의 해당 메서드를 사용하여 항목 별표표시 및 별표 삭제를 수행할 수도 있습니다. 애셋을 검색할 때 scope 객체의 starredOnly 매개변수를 사용합니다. 자세한 내용은 catalog.search 메서드를 참고하세요.
다음 단계
Data Catalog 검색 문법 이해하기
Dataplex 카탈로그에서 리소스를 검색하는 방법 알아보기