Puoi utilizzare l'API Data Catalog per creare e cercare voci dei set di file di Cloud Storage (chiamati set di file in questo documento).
Set di file
Un set di file Cloud Storage è una voce all'interno di un gruppo di voci creato dall'utente. Per ulteriori informazioni, consulta Voce e gruppi di voci.
È definito da uno o più pattern di file che specificano un insieme di uno o più file Cloud Storage.
Requisiti per il pattern dei file:
- Un pattern di file deve iniziare con
gs://bucket_name/. - Il nome del bucket deve rispettare i requisiti per i nomi dei bucket Cloud Storage.
- I caratteri jolly sono consentiti nelle parti di cartelle e file dei pattern di file, ma
non sono consentiti nei nomi dei bucket. Per esempi, consulta:
- Nomi con caratteri jolly
- Documentazione di riferimento dell'API GcsFilesetSpec.filePatterns
- Un set di file deve avere un pattern di set di file e non può averne più di 5.
Puoi eseguire query sui set di file di Data Catalog con Dataflow SQL, ma solo se hanno uno schema definito e contengono solo file CSV senza righe di intestazione.
Crea gruppi di voci e set di file
I set di file devono essere inseriti in un gruppo di voci creato dall'utente. Se non hai creato un gruppo di voci, crealo prima, quindi crea il set di file al suo interno. Puoi impostare i criteri IAM sul gruppo di voci per definire chi ha accesso ai set di file e ad altre voci all'interno del gruppo di voci.
Console
Console
Vai alla pagina Dataplex > Gruppi di voci.
Fai clic su Crea gruppo di voci.
Compila il modulo Crea gruppo di voci, quindi fai clic su CREA.
Viene visualizzata la pagina Dettagli gruppo di voci. Con la scheda ENTRATE selezionata, fai clic su CREA.
Compila il modulo Crea set di file.
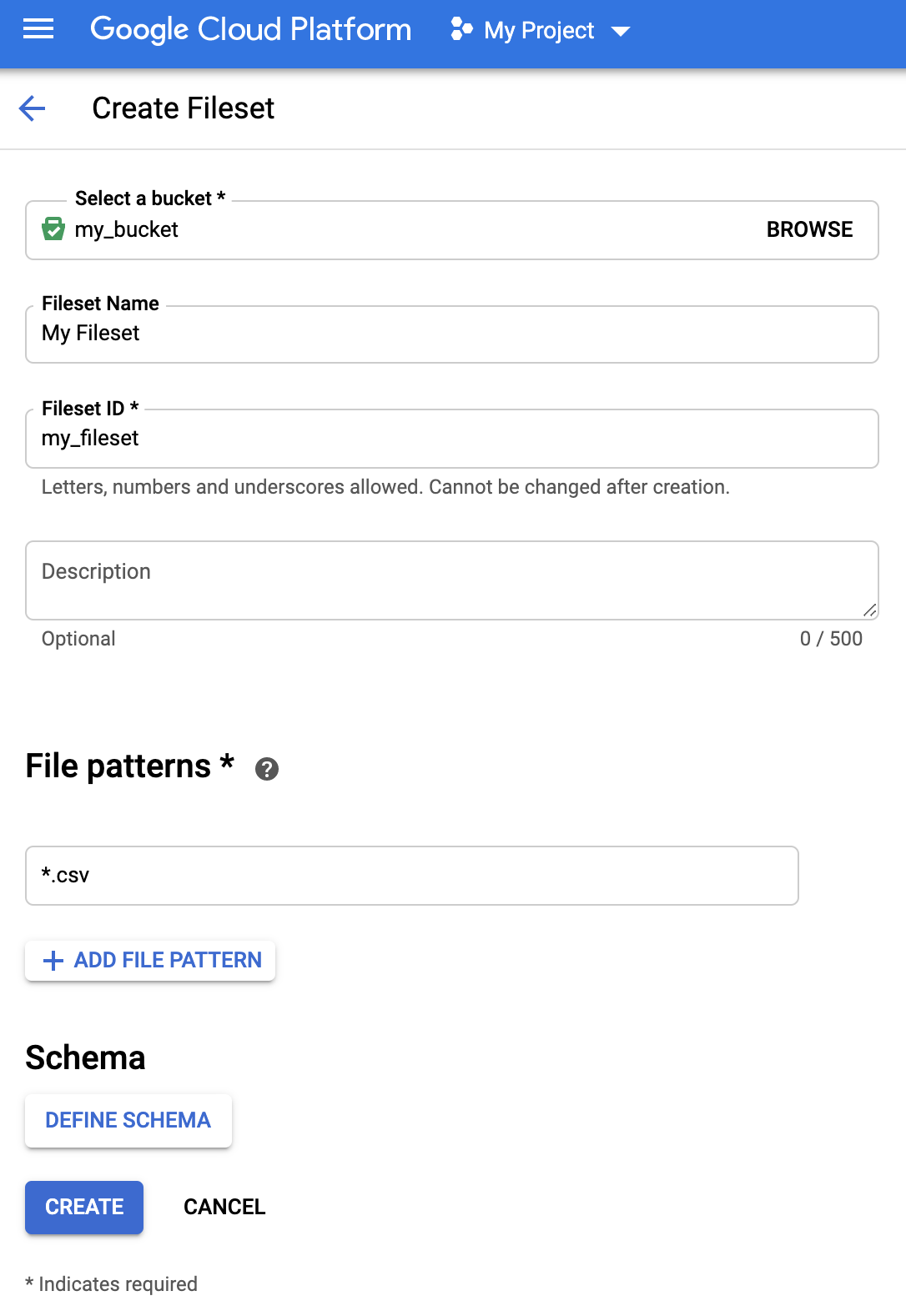
- Per allegare uno schema, fai clic su Definisci schema per aprire il modulo Schema.
Fai clic su + AGGIUNGI CAMPI per aggiungere i campi singolarmente o attiva/disattiva Modifica come testo in alto a destra nel modulo per specificare i campi in formato JSON.
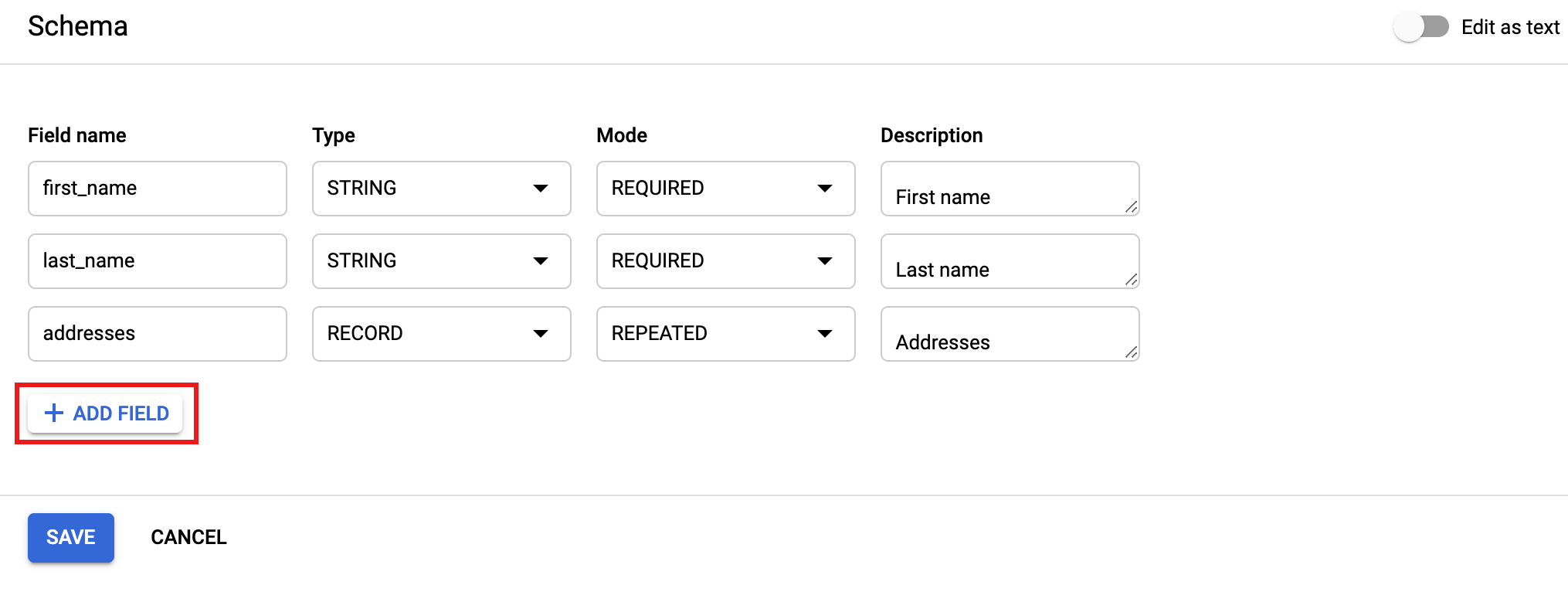
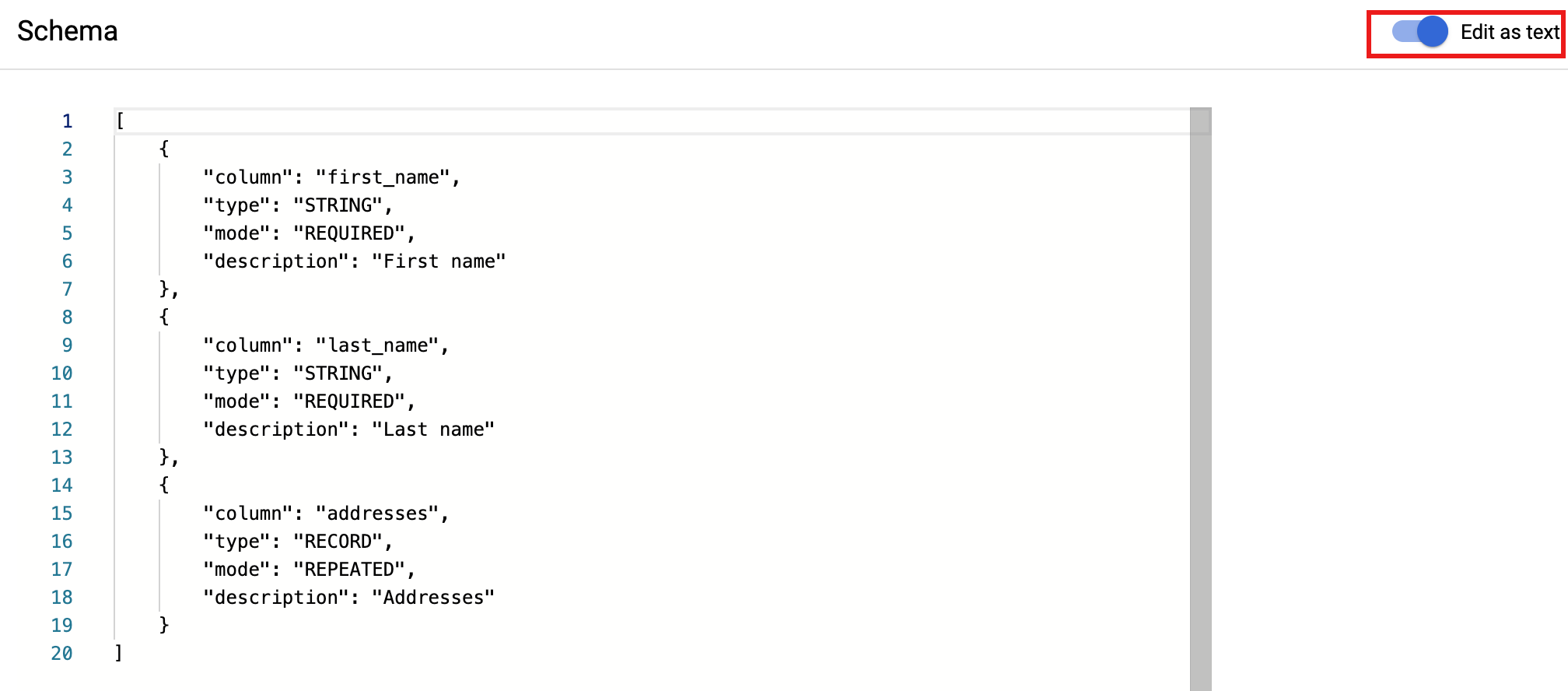
- Fai clic su Salva per salvare lo schema.
- Per allegare uno schema, fai clic su Definisci schema per aprire il modulo Schema.
Fai clic su + AGGIUNGI CAMPI per aggiungere i campi singolarmente o attiva/disattiva Modifica come testo in alto a destra nel modulo per specificare i campi in formato JSON.
Fai clic su Crea per creare il set di file.
gcloud
gcloud
1. Creare un gruppo di voci
Utilizza il comando gcloud data-catalog entry-groups create per creare un gruppo di voci con uno schema e una descrizione allegati.
Esempio:
gcloud data-catalog entry-groups create my_entrygroup \
--location=us-central1
2. Crea un set di file all'interno del gruppo di voci
Utilizza il comando gcloud data-catalog entries create per creare un set di file all'interno di un gruppo di voci. Questo esempio di comando Google Cloud CLI riportato di seguito crea una voce del set di file che include lo schema dei dati del set di file.
gcloud data-catalog entries create my_fileset_entry \
--location=us-central1 \
--entry-group=my_entrygroup \
--type=FILESET \
--gcs-file-patterns=gs://my-bucket/*.csv \
--schema-from-file=path_to_schema_file \
--description="Fileset description ..."
Note relative ai flag:
--gcs-file-patterns: consulta Requisiti dei pattern dei file.--schema-from-file: il seguente esempio mostra il formato JSON del file di testo dello schema accettato dal flag--schema-from-file.[ { "column": "first_name", "description": "First name", "mode": "REQUIRED", "type": "STRING" }, { "column": "last_name", "description": "Last name", "mode": "REQUIRED", "type": "STRING" }, { "column": "address", "description": "Address", "mode": "REPEATED", "type": "STRING" } ]
Java
Prima di provare questo esempio, segui le istruzioni di configurazione di Java riportate nella guida rapida all'utilizzo di Data Catalog con le librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Data Catalog Java.
Per autenticarti in Data Catalog, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js riportate nella guida rapida all'utilizzo di Data Catalog con le librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Data Catalog Node.js.
Per autenticarti in Data Catalog, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python riportate nella guida rapida all'utilizzo di Data Catalog con le librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Data Catalog Python.
Per autenticarti in Data Catalog, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configurare l'autenticazione per un ambiente di sviluppo locale.
REST e riga di comando
REST
Se non hai accesso alle librerie client di Cloud per la tua lingua o se vuoi testare l'API utilizzando le richieste REST, consulta i seguenti esempi e la documentazione dell'API REST di Data Catalog per entryGroups.create e entryGroups.entries.create.
- Creare un gruppo di voci
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- project-id: il tuo Google Cloud ID progetto
- entryGroupId: l'ID deve iniziare con una lettera o un trattino basso, contenere solo lettere, numeri e trattini bassi in inglese e avere al massimo 64 caratteri.
- displayName: Il nome del gruppo di voci.
Metodo HTTP e URL:
POST https://datacatalog.googleapis.com/v1/projects/project-id/locations/region/entryGroups?entryGroupId=entryGroupId
Corpo JSON della richiesta:
{
"displayName": "Entry Group display name"
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/my_projectid/locations/us-central1/entryGroups/my_entry_group",
"displayName": "Entry Group display name",
"dataCatalogTimestamps": {
"createTime": "2019-10-19T16:35:50.135Z",
"updateTime": "2019-10-19T16:35:50.135Z"
}
}
- Crea un set di file all'interno del gruppo di voci
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- project_id: il tuo Google Cloud ID progetto
- entryGroupId: ID di entryGroup esistente. Il set di file verrà creato in questo sntryGroup.
- entryId: EntryId del nuovo set di file. L'ID deve iniziare con una lettera o un trattino basso, contenere solo lettere, numeri e trattini bassi in inglese e non superare i 64 caratteri.
- description: descrizione del set di file.
- displayName: il nome della voce del set di file.
- filePatterns: deve iniziare con "gs://bucket_name/". Consulta Requisiti dei pattern dei file.
- schema: schema del set di file.
Schema JSON di esempio:
{ ... "schema": { "columns": [ { "column": "first_name", "description": "First name", "mode": "REQUIRED", "type": "STRING" }, { "column": "last_name", "description": "Last name", "mode": "REQUIRED", "type": "STRING" }, { "column": "address", "description": "Address", "mode": "REPEATED", "subcolumns": [ { "column": "city", "description": "City", "mode": "NULLABLE", "type": "STRING" }, { "column": "state", "description": "State", "mode": "NULLABLE", "type": "STRING" } ], "type": "RECORD" } ] } ... }
Metodo HTTP e URL:
POST https://datacatalog.googleapis.com/v1/projects/project_id/locations/region/entryGroups/entryGroupId/entries?entryId=entryId
Corpo JSON della richiesta:
{
"description": "Fileset description.",
"displayName": "Display name",
"gcsFilesetSpec": {
"filePatterns": [
"gs://bucket_name/file_pattern"
]
},
"type": "FILESET",
"schema": { schema }
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/my_project_id/locations/us-central1/entryGroups/my_entryGroup_id/entries/my_entry_id",
"type": "FILESET",
"displayName": "My Fileset",
"description": "My Fileset description.",
"schema": {
"columns": [
{
"type": "STRING",
"description": "First name",
"mode": "REQUIRED",
"column": "first_name"
},
{
"type": "STRING",
"description": "Last name",
"mode": "REQUIRED",
"column": "last_name"
},
{
"type": "RECORD",
"description": "Address",
"mode": "REPEATED",
"column": "address",
"subcolumns": [
{
"type": "STRING",
"description": "City",
"mode": "NULLABLE",
"column": "city"
},
{
"type": "STRING",
"description": "State",
"mode": "NULLABLE",
"column": "state"
}
]
}
]
},
"gcsFilesetSpec": {
"filePatterns": [
"gs://my_bucket_name/chicago_taxi_trips/csv/shard-*.csv"
]
},
"sourceSystemTimestamps": {
"createTime": "2019-10-23T23:11:26.326Z",
"updateTime": "2019-10-23T23:11:26.326Z"
},
"linkedResource": "//datacatalog.googleapis.com/projects/my_project_id/locations/us-central1/entryGroups/my_entryGroup_id/entries/my_entry_id"
}
Ruoli, autorizzazioni e criteri IAM
Data Catalog definisce i ruoli di voce e gruppo di voci per facilitare la gestione delle autorizzazioni dei set di file e di altre risorse di Data Catalog.
| Ruoli di voce | Descrizione |
|---|---|
dataCatalog.entryOwner |
Proprietario di una determinata voce o di un gruppo di voci.
|
dataCatalog.entryViewer |
Può visualizzare i dettagli di entry e entryGroup.
|
| Ruoli del gruppo di voci | Descrizione |
|---|---|
dataCatalog.entryGroupOwner |
Proprietario di un determinato gruppo di voci.
|
dataCatalog.entryGroupCreator |
Può creare entryGroup all'interno di un progetto. Al creatore di un gruppo di voci viene assegnato automaticamente il ruolo dataCatalog.entryGroupOwner.
|
Imposta policy IAM
Gli utenti con autorizzazione datacatalog.<resource>.setIamPolicy possono impostare i criteri IAM sui gruppi di voci di Data Catalog e su altre risorse di Data Catalog (consulta Ruoli di Data Catalog).
Console
Vai alla pagina Dettagli gruppo di voci nell'interfaccia utente di Data Catalog, quindi utilizza il riquadro IAM a destra per concedere o revocare le autorizzazioni.
gcloud
Imposta il criterio IAM di un gruppo di voci con Google Cloud CLI data-catalog entry-groups set-iam-policy:
gcloud data-catalog entry-groups set-iam-policy my_entrygroup \ --location=us-central1 \ policy file
Recupera il criterio IAM di un gruppo di voci con Google Cloud CLI data-catalog entry-groups get-iam-policy
gcloud data-catalog entry-groups get-iam-policy my_entrygroup \ --location=us-central1
Concedi i ruoli del gruppo di voci
Esempio 1
Un'azienda con contesti aziendali diversi per i propri set di file
crea gruppi di voci order-files e user-files separati:
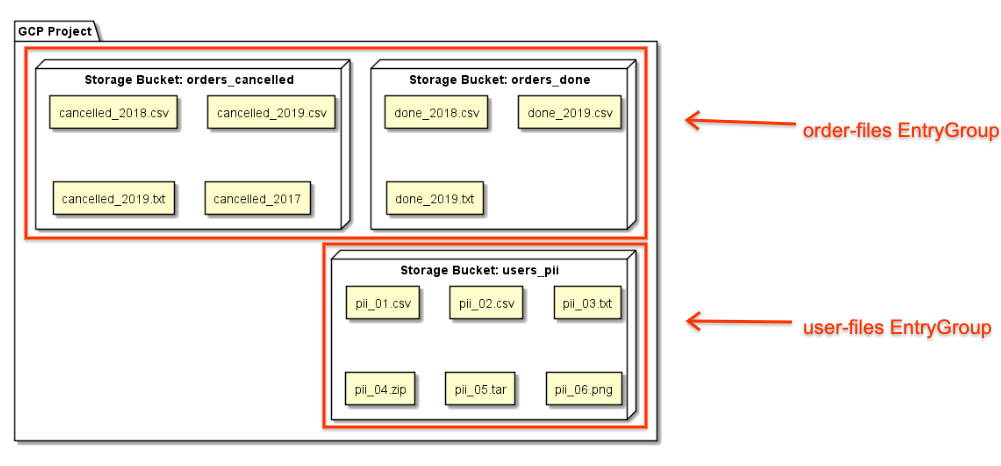
L'azienda concede agli utenti il ruolo Visualizzatore gruppo di voci per order-files, il che significa che possono cercare solo le voci contenute in quel gruppo di voci. I risultati di ricerca non restituiscono voci nel gruppo di voci user-files.
Esempio 2
Un'azienda concede il ruolo Visualizzatore gruppo di voci a un utente solo nel progettoproject_entry_group. L'utente potrà visualizzare solo le voci all'interno del progetto.
Cerca set di file
Gli utenti possono limitare l'ambito della ricerca in Data Catalog utilizzando
la dimensione type. type=entry_group limita la query di ricerca ai gruppi di voci, mentre type=fileset cerca solo set di file.
Le sfaccettature type possono essere utilizzate in combinazione con altre sfaccettature, ad esempio projectid.
gcloud
Per cercare gruppi di voci in un progetto:
gcloud data-catalog search \ --include-project-ids=my-project "projectid=my-project type=entry_group"
Cerca tutti i gruppi di voci a cui puoi accedere:
gcloud data-catalog search \ --include-project-ids=my-project "type=entry_group"
Cerca i set di file in un progetto:
gcloud data-catalog search \ --include-project-ids=my-project "type=entry.fileset"
Cerca i set di file in un progetto (sintassi semplificata):
gcloud data-catalog search \ --include-project-ids=my-project "type=fileset"