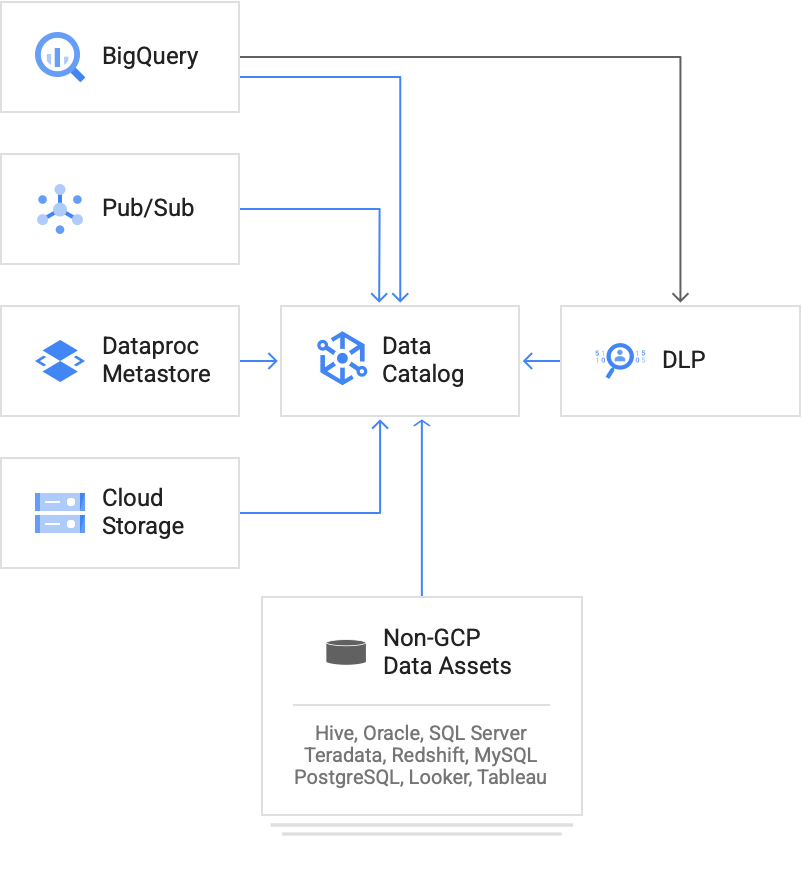
Dataplex의 Data Catalog 기능은 조직 데이터 애셋의 중앙 인벤토리입니다. Data Catalog는 BigQuery, Vertex AI, Pub/Sub, Spanner, Bigtable과 같은 Google Cloud 소스의 메타데이터를 자동으로 분류합니다. Data Catalog는 탐색을 통해 Cloud Storage의 테이블 및 파일 세트 메타데이터의 색인을 생성합니다.
Dataplex의 거버넌스 적용된 조직 전체 메타데이터 검색 기능을 사용하여 데이터를 탐색할 수 있습니다. 중요한 비즈니스 컨텍스트로 메타데이터를 더욱 풍부하게 만들고 계보 추적, 데이터 프로파일링, 데이터 품질 검사, 액세스 제어 기능을 사용 설정할 수 있습니다.
Data Catalog를 사용하면 조직은 더 나은 데이터 검색, 메타데이터 관리, 거버넌스를 달성할 수 있습니다.
Data Catalog가 필요한 이유는 무엇인가요?
대부분의 조직은 점점 증가하는 대규모 데이터 애셋을 다룹니다.
조직 내의 데이터 이해관계자 (소비자, 제작자, 관리자)는 다음과 같은 여러 문제를 겪고 있습니다.
유용한 데이터 검색:
데이터 소비자는 데이터의 위치와 출처를 알 수 없습니다. 데이터 '늪'을 탐색해야 합니다.
대부분의 데이터는 잘 문서화되어 있지 않으며 문서화되어 있더라도 제대로 유지관리되어 있지 않으므로 데이터 소비자는 유용한 정보를 얻기 위해 어떤 데이터를 사용해야 할지 모릅니다.
데이터가 사람들의 머리 속에만 있으면 찾을 수 없으며 손실되기 쉽습니다.
데이터 이해:
프로덕션에서 사용할 수 있도록 최신이며 정제, 검증, 승인된 최신 데이터인가요?
여러 중복 데이터 세트 중 관련이 있는 어떤 데이터 세트가 관련성이 있고 최신인가요?
하나의 데이터 세트는 다른 데이터 세트와 어떤 관련이 있나요?
누가 데이터를 사용하고 누가 소유자인가요?
누가 어떤 프로세스로 데이터를 변환하나요?
데이터를 유용하게 활용:
데이터 제작자가 소비자를 위한 데이터를 전달할 수 있는 효율적인 방법이 없습니다. 셀프서비스가 없으면 제작자는 소비자를 감당할 수 없습니다.
데이터 엔지니어 몇 명이 데이터 분석가 수천 명에게 데이터를 수동으로 제공할 수는 없습니다.
데이터 소비자가 데이터 액세스를 요청하는 방법을 직접 알아내고, 기약 없이 응답을 기다리고, 에스컬레이션하고, 다시 기다려야 한다면 소중한 시간을 낭비하는 셈입니다.
적절한 도구가 없다면 이 문제가 데이터를 효율적으로 사용하는 데 심각한 장애물이 됩니다. Data Catalog를 사용하는 조직은 중앙 저장소에서 다음을 수행할 수 있습니다.
통합 뷰가 있으면 적절한 데이터를 쉽게 찾을 수 있습니다.
기술 및 비즈니스 메타데이터로 데이터를 보강하여 데이터 중심의 의사결정을 지원하고 통계 시간을 단축합니다.
데이터가 카탈로그화된 후 태그를 사용하여 고유한 메타데이터를 이러한 자산에 추가할 수 있습니다.
그림 1.
Data Catalog는 Google Cloud 서비스 및 커스텀 데이터 소스에서 메타데이터를 읽습니다.
Data Catalog 메타데이터
Data Catalog는 기술 메타데이터와 비즈니스 메타데이터라는 두 가지 유형의 메타데이터를 처리합니다. 메타데이터에 대한 자세한 내용은 Data Catalog 메타데이터를 참조하세요.
검색 및 탐색
Data Catalog는 데이터 항목과 연결된 기술 및 비즈니스 메타데이터에 대해 강력한 조건자 기반 검색 환경을 제공합니다. 메타데이터에 검색 및 탐색을 적용할 수 있도록 데이터 항목의 메타데이터를 읽을 수 있는 권한이 있어야 합니다. Data Catalog는 데이터 항목 내의 데이터에 대한 색인을 생성하지 않습니다. Data Catalog는 애셋을 설명하는 메타데이터의 색인만 생성합니다.
Data Catalog는 사용자가 생성한 태그 같은 일부 메타데이터를 제어합니다.
기본 스토리지 시스템의 모든 메타데이터의 경우 Data Catalog는 기본 스토리지 시스템에서 제공하는 메타데이터와 권한을 반영하는 읽기 전용 서비스입니다. 기본 스토리지 시스템에서 편집하여 데이터 항목의 메타데이터를 추가, 업데이트 또는 삭제할 수 있습니다.
[[["이해하기 쉬움","easyToUnderstand","thumb-up"],["문제가 해결됨","solvedMyProblem","thumb-up"],["기타","otherUp","thumb-up"]],[["이해하기 어려움","hardToUnderstand","thumb-down"],["잘못된 정보 또는 샘플 코드","incorrectInformationOrSampleCode","thumb-down"],["필요한 정보/샘플이 없음","missingTheInformationSamplesINeed","thumb-down"],["번역 문제","translationIssue","thumb-down"],["기타","otherDown","thumb-down"]],["최종 업데이트: 2025-01-16(UTC)"],[[["\u003cp\u003eData Catalog is a centralized inventory within Dataplex that automatically catalogs metadata from various Google Cloud sources, including BigQuery, Vertex AI, Pub/Sub, Spanner, and more, enabling organization-wide metadata search and discovery.\u003c/p\u003e\n"],["\u003cp\u003eData Catalog addresses challenges such as difficulty in finding, understanding, and utilizing data by providing a unified view, enriching data with metadata, improving data management, and fostering data ownership.\u003c/p\u003e\n"],["\u003cp\u003eData Catalog offers functionalities like searching for accessible data entries, tagging data entries with metadata, and providing column-level security for BigQuery tables, thus enhancing data discoverability and governance.\u003c/p\u003e\n"],["\u003cp\u003eData Catalog indexes both technical and business metadata, allowing for predicate-based searches, and while it catalogs metadata, it does not index the data within a data entry.\u003c/p\u003e\n"],["\u003cp\u003eData catalog can catalog metadata from non-Google Cloud systems using community-contributed connectors or manually building with the Data Catalog APIs.\u003c/p\u003e\n"]]],[],null,["# Data Catalog overview\n\nData Catalog is a central inventory\nof an organization's data assets. Data Catalog automatically\ncatalogs metadata from Google Cloud sources such as BigQuery,\nVertex AI, Pub/Sub, Spanner, Bigtable,\nand more. Data Catalog also indexes table and fileset metadata\nfrom Cloud Storage through [discovery](/dataplex/docs/discover-data).\n\nYou can discover data with Dataplex Universal Catalog's governed organization-wide\nmetadata search capability. You can further enrich metadata with critical\nbusiness context, and enable lineage tracking, data profiling, data quality\nchecks, and access control capabilities.\n\nUsing Data Catalog, organizations can achieve better data\ndiscovery, metadata management, and governance.\n\nWhy do you need Data Catalog?\n-----------------------------\n\nMost organizations deal with a large and growing number of data assets.\nData stakeholders (consumers, producers, and administrators) within an\norganization face multiple challenges, including the following:\n\n- **Searching for insightful data**:\n\n - Data consumers don't know the location and origin of data. They have to navigate data \"swamps\".\n - Data consumers don't know what data to use to get insights because most data isn't well documented and, even if documented, isn't well maintained.\n - Data can't be found and is often lost when it resides only in people's minds.\n- **Understanding data**:\n\n - Is the data fresh, clean, validated, approved for use in production?\n - Which dataset out of several duplicate sets is relevant and up-to-date?\n - How does one dataset relate to another?\n - Who is using the data and who is the owner?\n - Who and what processes are transforming the data?\n- **Making data useful**:\n\n - Data producers don't have an efficient way to put forward their data for\n consumers. If there's no self-service, consumers may overwhelm producers.\n Several data engineers can't manually provide data to thousands of data\n analysts.\n\n - Valuable time is lost if data consumers have to find out how to request\n data access, wait without a defined response time, escalate, and wait again.\n\nWithout the right tools, the challenges become a major obstacle\nto the efficient use of data. Data Catalog provides a centralized\nrepository that lets organizations achieve the following:\n\n- Gain a **unified view** to reduce the pain of searching for the right data.\n- Support data-driven decision making and accelerate the insight time by enriching data with **technical and business metadata**.\n- Improve **data management** to increase operational efficiency and productivity.\n- Take **ownership** over the data to improve trust and confidence in it.\n\nData Catalog functions\n----------------------\n\nData Catalog provides three main functions:\n\n- Searching for data entries for which you have access\n- Tagging data entries with metadata\n- Providing [column-level security](/bigquery/docs/column-level-security-intro) for BigQuery tables\n\nIn addition, Data Catalog can build on the results of a\n[Sensitive Data Protection](/sensitive-data-protection/docs) scan to identify sensitive\ndata directly within Data Catalog in the form of tag templates.\n\nHow Data Catalog works\n----------------------\n\nData Catalog can catalog asset metadata from different Google Cloud systems.\n\nYou can also use Data Catalog APIs to integrate with [custom data sources](/data-catalog/docs/how-to/custom-entries).\n\nAfter your data is cataloged, you can add your own metadata to these assets using tags.\n**Figure 1.** Data Catalog reads metadata from Google Cloud services and custom data sources.\n\nData Catalog metadata\n---------------------\n\nData Catalog handles two types of metadata: **technical metadata** and **business metadata** . To know more about metadata, see [Data Catalog metadata](/data-catalog/docs/concepts/metadata).\n\nSearch and discovery\n--------------------\n\nData Catalog offers a powerful predicate-based search\nexperience for technical and business metadata associated with a data entry. You\nmust have the permissions to read the metadata for a data entry so that you can\napply search and discovery on the metadata. Data Catalog does not\nindex the data within a data entry. Data Catalog only indexes the\nmetadata that describes an asset.\n\nData Catalog controls some metadata such as user-generated tags.\nFor all metadata sourced from the underlying storage system,\nData Catalog is a read-only service that reflects the metadata\nand permissions provided by the underlying storage system. You can make edits in\nthe underlying storage system to add, update, or delete the metadata of a data\nentry.\n\nTo know more about Data Catalog search, see\n[Search for data assets with Data Catalog](/data-catalog/docs/how-to/search).\n\n### Automatic cataloging of assets\n\nFor a given project, Data Catalog automatically catalogs the\nfollowing Google Cloud assets:\n\n- BigQuery sharing (formerly Analytics Hub) linked datasets\n- BigQuery datasets, tables, models, routines, and connections\n- Bigtable instances, clusters, and tables (including column family details)\n- Dataplex Universal Catalog lakes, zones, tables, and filesets\n- Dataproc Metastore services, databases, and tables\n- Pub/Sub topics\n- Spanner instances, databases, tables, and views\n- [Vertex AI models](/vertex-ai/docs/model-registry/introduction),\n [datasets](/vertex-ai/docs/datasets/overview), and\n [Vertex AI Feature Store resources](/vertex-ai/docs/featurestore/latest/overview)\n\n | **Note:** If a project name contains `:`, Dataplex Universal Catalog doesn't catalog `FeatureView` and `Feature` resources created in that project.\n\nIn addition to cataloging assets within the project IDs for which you have metadata access, Data Catalog can catalog data stored in the BigQuery projects\nthat contain public datasets.\n\n### Catalog non-Google Cloud assets\n\nTo catalog metadata from non-Google Cloud systems in your organization, you can use the\nfollowing:\n\n- [Community-contributed connectors](/data-catalog/docs/integrate-data-sources#integrate_on-premises_data_sources) to multiple popular on-premises data sources\n- Manually build on the [Data Catalog APIs for custom entries](/data-catalog/docs/integrate-data-sources#integrate_unsupported_data_sources)\n\nAccess Data Catalog\n-------------------\n\nYou can access Data Catalog functionalities using:\n\n- Dataplex Universal Catalog in the [Google Cloud console](https://console.cloud.google.com/dataplex)\n\n- [`gcloud`](/sdk/gcloud/reference/data-catalog) command-line interface (CLI)\n\n- [Data Catalog APIs](/data-catalog/docs/reference#data-catalog-api-reference)\n\n- [Cloud Client Libraries](/data-catalog/docs/reference/libraries)\n\nWhat's next\n-----------\n\n- Learn how to\n [tag a BigQuery table by using Data Catalog](/data-catalog/docs/quickstarts/quickstart-search-tag).\n\n- Learn how to\n [search data assets with Data Catalog](/data-catalog/docs/how-to/search).\n\n- Learn how to\n [integrate Google Cloud and on-premises data sources with Data Catalog](/data-catalog/docs/integrate-data-sources)."]]