La fonctionnalité Data Catalog de Dataplex permet de créer un inventaire central des éléments de données d'une organisation. Data Catalog catalogue automatiquement les métadonnées provenant de sources telles que BigQuery, Vertex AI, Pub/Sub, Spanner, Bigtable, etc. Google Cloud Data Catalog indexe également les métadonnées des tables et des ensembles de fichiers à partir de Cloud Storage via la découverte.
Vous pouvez découvrir des données grâce à la fonctionnalité de recherche de métadonnées gérée à l'échelle de l'organisation de Dataplex. Vous pouvez enrichir davantage les métadonnées avec un contexte métier essentiel, et activer le suivi de la traçabilité, le profilage des données, les contrôles de qualité des données et les fonctionnalités de contrôle des accès.
Grâce à Data Catalog, les entreprises peuvent améliorer la découverte, la gestion et la gouvernance des données.
Pourquoi avez-vous besoin de Data Catalog ?
La plupart des entreprises gèrent un nombre important et croissant d'éléments de données. Les personnes concernées par les données (utilisateurs, producteurs et administrateurs) au sein d'une organisation sont confrontées à plusieurs défis, y compris les suivants:
Rechercher des données pertinentes :
- Les utilisateurs de données ne connaissent pas l'emplacement ni l'origine des données. Ils doivent parcourir le "marécage" de données.
- Les consommateurs de données ne savent pas quelles données utiliser pour obtenir des insights, car la plupart d'entre elles ne sont pas bien documentées et, même si elles le sont, ne sont pas bien gérées.
- Les données sont introuvables et sont souvent perdues lorsqu'elles ne résident que dans l'esprit des utilisateurs.
Comprendre les données :
- Les données sont-elles à jour, nettoyées, validées et approuvées pour une utilisation en production ?
- Parmi les ensembles de données en double, lequel est pertinent et à jour ?
- Quel lien existe-t-il entre un ensemble de données et un autre ?
- Qui utilise les données et qui en est le propriétaire ?
- Qui et quels processus transforment les données ?
Rendre les données utiles :
Les producteurs de données ne disposent pas d'un moyen efficace de transférer leurs données aux consommateurs. En l'absence de libre-service, les consommateurs risquent de submerger les producteurs. Plusieurs ingénieurs de données ne peuvent pas fournir de données manuellement à des milliers d'analystes de données.
Vous perdez un temps précieux si les consommateurs de données doivent déterminer comment demander l'accès aux données, attendre sans délai de réponse défini, faire remonter la demande et attendre encore.
Sans les bons outils, les défis constituent un obstacle majeur à l'utilisation efficace des données. Data Catalog fournit un référentiel centralisé qui permet aux organisations d'effectuer les opérations suivantes:
- bénéficier d'une vue unifiée afin de réduire les difficultés liées à la recherche des données appropriées ;
- Favorisez la prise de décision basée sur les données et accédez plus rapidement aux insights en enrichissant les données avec des métadonnées techniques et métier.
- améliorer la gestion des données pour améliorer l'efficacité opérationnelle et la productivité ;
- revendiquer la propriété des données pour améliorer la confiance à l'égard de celles-ci.
Fonctions Data Catalog
Data Catalog propose trois fonctions principales:
- En recherchant des entrées de données auxquelles vous avez accès
- Ajouter des tags de métadonnées aux entrées de données
- Fournir une sécurité au niveau des colonnes pour les tables BigQuery
En outre, Data Catalog peut s'appuyer sur les résultats d'une analyse Protection des données sensibles pour identifier des données sensibles directement dans Data Catalog sous la forme de modèles de tag.
Fonctionnement de Data Catalog
Data Catalog peut cataloguer les métadonnées des éléments à partir de différents Google Cloud systèmes.
Vous pouvez également utiliser les API Data Catalog pour intégrer des sources de données personnalisées.
Une fois vos données cataloguées, vous pouvez ajouter vos propres métadonnées à ces éléments à l'aide de tags.
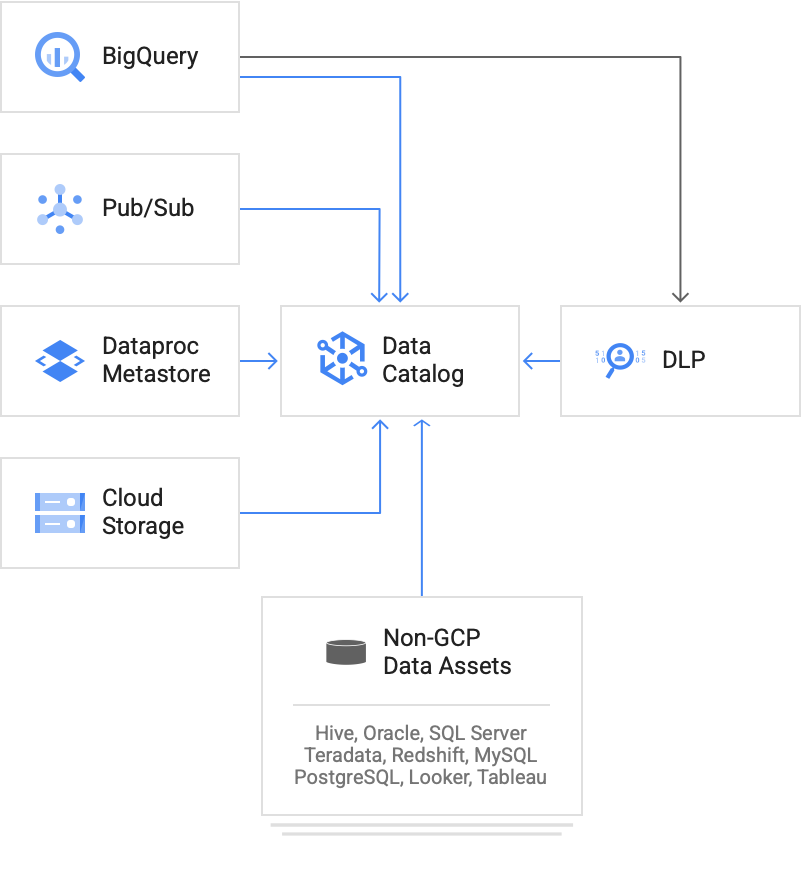
Métadonnées Data Catalog
Data Catalog gère deux types de métadonnées : les métadonnées techniques et les métadonnées commerciales. Pour en savoir plus sur les métadonnées, consultez la page Métadonnées Data Catalog.
Recherche et découverte
Data Catalog offre une expérience de recherche puissante basée sur des prédicats pour les métadonnées techniques et métier associées à une entrée de données. Vous devez disposer des autorisations nécessaires pour lire les métadonnées d'une entrée de données afin de pouvoir appliquer la recherche et la découverte aux métadonnées. Data Catalog n'indexe pas les données dans une entrée de données. Data Catalog n'indexe que les métadonnées décrivant un élément.
Data Catalog contrôle certaines métadonnées telles que les tags générés par l'utilisateur. Pour toutes les métadonnées provenant du système de stockage sous-jacent, Data Catalog est un service en lecture seule qui reflète les métadonnées et les autorisations fournies par le système de stockage sous-jacent. Vous pouvez apporter des modifications dans le système de stockage sous-jacent pour ajouter, mettre à jour ou supprimer les métadonnées d'une entrée de données.
Pour en savoir plus sur la recherche dans Data Catalog, consultez la page Rechercher des éléments de données avec Data Catalog.
Catalogage automatique des composants
Pour un projet donné, Data Catalog répertorie automatiquement les éléments Google Cloud suivants:
- Ensembles de données associés à Analytics Hub
- Ensembles de données, tables, modèles, routines et connexions BigQuery
- Instances, clusters et tables Bigtable (y compris les détails des familles de colonnes)
- Lacs, zones, tables et fichiers Dataplex
- Services, bases de données et tables Dataproc Metastore
- Sujets Pub/Sub
- Instances, bases de données, tables et vues Spanner
Modèles Vertex AI, ensembles de données et ressources Vertex AI Feature Store
En plus de cataloguer les éléments dans les ID de projet pour lesquels vous avez accès aux métadonnées, Data Catalog peut cataloguer des données stockées dans les projets BigQuery qui contiennent des ensembles de données publics.
Cataloguer des éléments autres queGoogle Cloud
Pour répertorier les métadonnées de systèmes autres queGoogle Cloud dans votre organisation, vous pouvez utiliser les éléments suivants:
- Connecteurs de la communauté vers plusieurs sources de données sur site populaires
- API Data Catalog pour les entrées personnalisées exploitées manuellement
Accéder à Data Catalog
Vous pouvez accéder aux fonctionnalités de Data Catalog à l'aide des éléments suivants:
Dataplex dans la console Google Cloud
Interface de ligne de commande (CLI)
gcloud
Étape suivante
Découvrez comment taguer une table BigQuery à l'aide de Data Catalog.
Découvrez comment effectuer des recherches dans les éléments de données avec Data Catalog.
Découvrez comment intégrer Google Cloud et des sources de données sur site à Data Catalog.