El linaje de los datos te permite hacer un seguimiento de cómo se mueven los datos por tus sistemas: de dónde proceden, a dónde se transfieren y qué transformaciones se les aplican.
¿Por qué necesitas el linaje de datos?
Trabajar con grandes conjuntos de datos suele implicar transformar los datos en entidades adaptadas a las necesidades de un proyecto específico: archivos de texto, tablas, informes, paneles de control o modelos.
Por ejemplo, supongamos que tiene una tienda online en la que registra cada compra en una sola tabla SQL. Para que tus analistas puedan trabajar con los datos más fácilmente, empiezas a ejecutar tareas que extraen información de esta tabla y generan tablas más pequeñas por región, marca o precio de venta. Después, tus analistas empiezan a hacer lo mismo: realizan más transformaciones y combinan estas tablas más pequeñas con otras fuentes de datos para generar aún más tablas.
Esto puede convertirse en un gran reto para las partes interesadas:
- Los consumidores de datos no pueden usar una herramienta de autoservicio para saber si los datos proceden de una fuente autorizada.
- Los ingenieros de datos no pueden identificar la causa raíz de los problemas porque no hay una forma fiable de monitorizar todas las transformaciones de datos.
- Los ingenieros y analistas de datos no pueden evaluar por completo el posible impacto antes de modificar o eliminar tablas.
- Los responsables de los datos no pueden saber cómo se usan los datos sensibles en toda la organización ni verificar el cumplimiento de los requisitos normativos.
El linaje de datos es una solución que proporciona una forma práctica de hacer lo siguiente:
- Descubre cómo se extraen y se transforman los datos con la ayuda de gráficos de linaje.
- Rastrea los errores relacionados con las entradas y las operaciones de datos hasta sus causas principales.
- Mejora la gestión de cambios mediante el análisis de impacto: evita los tiempos de inactividad o los errores inesperados, identifica las entradas dependientes y colabora con las partes interesadas pertinentes.
Modelo de información de linaje de datos
En su forma básica, el linaje es un registro de los datos que se transforman de fuentes a destinos. La API Data Lineage recoge esa información y la organiza en un modelo de datos jerárquico mediante los conceptos de procesos, ejecuciones y eventos.
Proceso
Un proceso es la definición de una operación de transformación de datos admitida en un sistema específico. En el contexto del linaje de BigQuery, una process es uno de los tipos de trabajo admitidos.
Ejecutar
Una ejecución es la puesta en marcha de un proceso. Los procesos pueden tener varias ejecuciones.
Las ejecuciones contienen detalles como las horas de inicio y finalización, el estado o atributos adicionales.
Para obtener más información, consulta la referencia de recursos de run.
Evento
Un evento representa un momento en el que se ha llevado a cabo una operación de transformación de datos y ha provocado que los datos se muevan entre una entidad de origen y una de destino.
Los eventos contienen una lista de enlaces que definen qué entrada era la fuente y cuál era el destino en un evento concreto. Aunque los eventos se usan para calcular gráficos de linaje, no se exponen directamente en la consola Google Cloud . Puedes crearlos, leerlos y eliminarlos (pero no actualizarlos) con la API Data Lineage.
Ejemplo
Veamos el siguiente ejemplo, en el que se copian datos entre tablas de BigQuery:
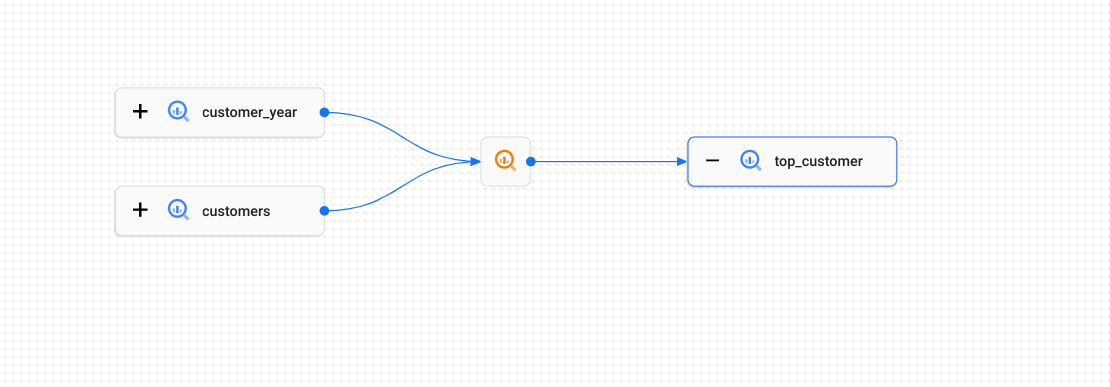
El proceso de linaje describe cómo se mueven los datos entre las tablas (se representa en el gráfico con el icono ![]()
CREATE TABLE AS SELECT
INSERT): puede ser una consulta SQL o una instrucción.
Cada ejecución de esa instrucción SQL constituiría una ejecución individual.
Los procesos contienen eventos que registran qué tablas se han usado como fuentes y cuáles como destinos. En este ejemplo, las tablas customer_year y customers son la fuente de la tabla top_customer de destino.
Gráfico de linaje
Los gráficos de linaje representan la información recogida por la API Data Lineage de una entrada concreta de Dataplex Universal Catalog. Un gráfico de linaje muestra el linaje que está antes o después de una sola entrada raíz. Raíz hace referencia a la entrada de la que estás viendo el linaje.
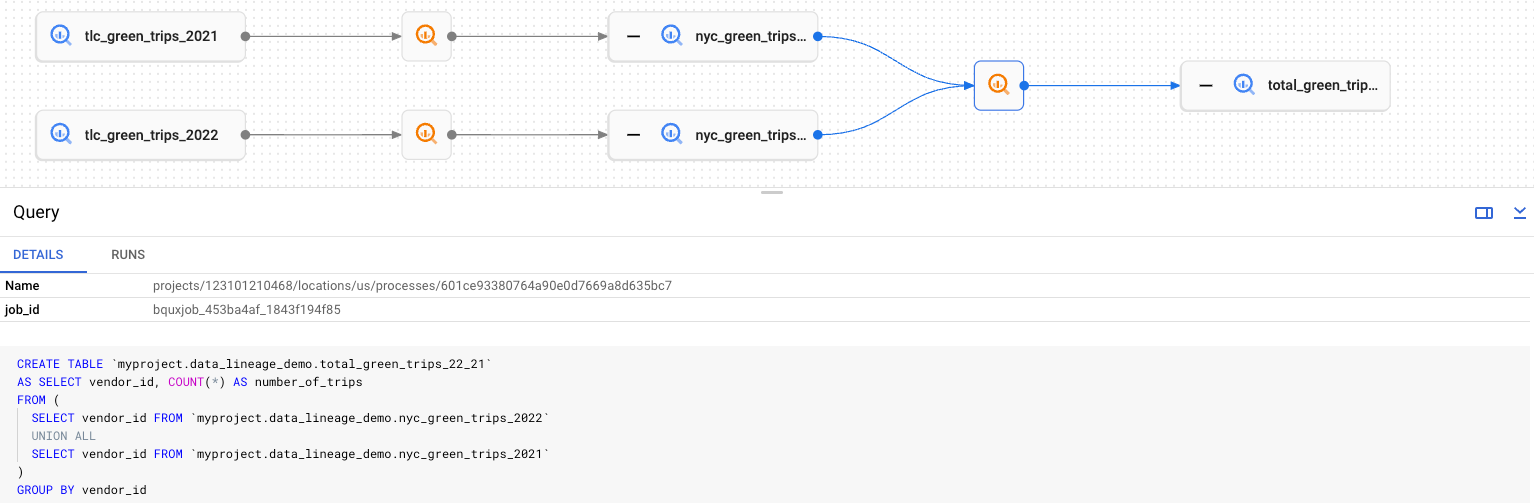
Dataplex Universal Catalog funciona con la API Data Lineage para identificar las entradas cuyo nombre completo coincide con las entidades reconocidas por el linaje de datos. En el caso de las entradas coincidentes de Dataplex Universal Catalog, puedes acceder a la pestaña Linaje de su página de detalles y ver el gráfico.
Los gráficos de linaje muestran dos tipos de elementos:
Botones rectangulares anchos que representan las entidades implicadas en la creación de información de linaje como fuentes o destinos de un evento de linaje.
Botones cuadrados más pequeños que representan los procesos responsables de crear o actualizar las entidades de origen o de destino. Los botones de proceso usan iconos específicos del sistema de origen que los ha comunicado a la API Data Lineage. Por ejemplo, las tareas de BigQuery usan el icono
 .
.
Visualización de la ruta de linaje
Las visualizaciones de la ruta de linaje te ayudan a entender los enlaces de linaje entre dos recursos seleccionados. (Esto contrasta con el gráfico de linaje, que muestra el linaje que está antes o después de una sola entrada raíz, posiblemente para varias fuentes o destinos).
Elige el recurso raíz y el recurso de destino, y la Google Cloud consola mostrará los enlaces de linaje entre los dos recursos. Otros recursos y procesos que no se encuentran en una ruta entre los dos recursos se ocultan de la visualización de la ruta.
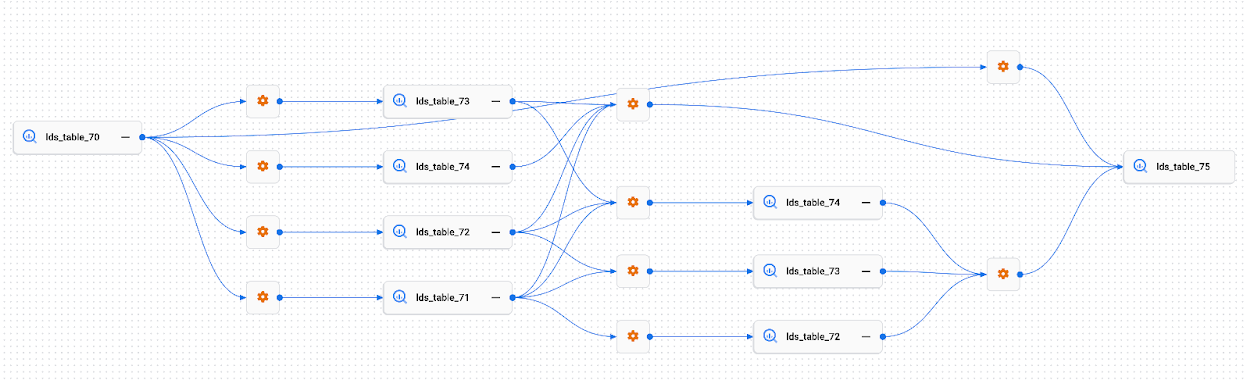
Vista de lista de linaje
La vista de lista de linaje muestra información detallada sobre el linaje de las entidades en una sola tabla.
En comparación con el gráfico de linaje, que es más adecuado para ver gráficos de linaje relativamente pequeños, la vista de lista de linaje te permite ver información de linaje de entidades con muchas conexiones.
En la siguiente imagen se muestra un ejemplo de la vista de lista de linaje en la consola deGoogle Cloud . En la lista que aparece a continuación se describe la imagen con más detalle.

Cada fila de la tabla representa un único enlace de linaje entre dos entradas. En el gráfico, estos nombres se representan como los enlaces de linaje entre dos entradas, incluidos los nodos de proceso intermedios. Por ejemplo,
SourceyTargetson nodos de recursos, con varios nodos de proceso entre ellos.La opción Dirección especifica la parte del flujo de datos que se va a mostrar en la lista, en relación con el recurso raíz:
Ascendente: muestra información sobre el linaje de las entradas que son fuentes de datos de la entrada seleccionada. En el gráfico de linaje, estas entradas son las que aparecen a la izquierda de la entrada seleccionada.
Descendente: muestra información sobre el linaje de las entradas que usan o se derivan de la entrada seleccionada. En el gráfico de linaje, estas entradas son las que aparecen a la derecha de la entrada seleccionada.
La opción Intervalo de tiempo te permite filtrar la información de linaje en función del momento en que se produjo el linaje:
Hora de inicio: muestra el linaje que se produjo después de la hora de inicio.
Hora de finalización: muestra el linaje que se produjo antes de la hora de finalización.
Profundidad: indica la distancia de un recurso de origen o derivado con respecto al recurso raíz. La vista de lista muestra hasta 1000 enlaces de linaje, con una profundidad máxima de 10 enlaces de linaje desde la raíz. Si hay algún linaje fuera de este intervalo, se te notificará. Para ver el linaje fuera de este intervalo, selecciona el nombre de otra entidad en la vista de lista.
El panel Detalles muestra información sobre la fuente del enlace, el destino del enlace y todos los procesos que crearon este enlace.
Puede personalizar las columnas que se muestran en la tabla y filtrar los resultados. También puedes exportar los resultados a un archivo CSV.
Seguimiento automatizado del linaje de datos
Cuando habilitas la API Data Lineage, Google Cloud los sistemas que admiten el linaje de datos empiezan a registrar sus movimientos de datos. Cada sistema integrado puede enviar información de linaje de un intervalo diferente de fuentes de datos. Para obtener más información sobre todos los productos compatibles, consulta las secciones siguientes.
BigQuery
Si habilitas el linaje de datos en tu proyecto de BigQuery, Dataplex Universal Catalog registrará automáticamente la información del linaje de los siguientes elementos:
Se crearán tablas como resultado de los siguientes trabajos de BigQuery:
- Tareas de copia
- Tareas de carga que usan el URI de Cloud Storage para cargar datos en cualquier formato permitido desde Cloud Storage
- Las tareas de consulta que usan el siguiente lenguaje de definición de datos (DDL) en GoogleSQL:
Tablas creadas como resultado de usar las siguientes declaraciones del lenguaje de manipulación de datos (DML) en GoogleSQL:
- SELECT en relación con cualquiera de los tipos de tabla que se indican a continuación:
- INSERT SELECT
- FUSIONAR
- ACTUALIZACIÓN
- ELIMINAR
Las tareas de copia, consulta y carga de BigQuery se representan como procesos. Para ver los detalles del proceso, haz clic en ![]() en el gráfico de linaje.
Cada proceso contiene el job_id de BigQuery
en la lista de
atributos
del trabajo de BigQuery más reciente.
en el gráfico de linaje.
Cada proceso contiene el job_id de BigQuery
en la lista de
atributos
del trabajo de BigQuery más reciente.
Otros servicios
El linaje de datos admite la integración con los siguientes servicios:Google Cloud
Linaje de datos de fuentes de datos personalizadas
Puede usar la API Data Lineage para registrar información de linaje manualmente de cualquier fuente de datos que no sea compatible con los sistemas integrados.
Dataplex Universal Catalog puede crear gráficos de linaje para el linaje registrado manualmente si usas un fullyQualifiedName que coincida con los nombres completos de las entradas de Dataplex Universal Catalog. Si quieres registrar el linaje de una fuente de datos personalizada, primero debes crear una entrada personalizada.
Cada proceso de fuente de datos personalizada puede contener sql claves en la lista de atributos. El valor de esta clave se usará para renderizar el resaltado de código en el panel de detalles del gráfico de linaje de datos. La instrucción SQL se mostrará tal como se
proporcionó. El usuario es responsable de filtrar la información sensible. En el nombre de la clave sql se distingue entre mayúsculas y minúsculas.
OpenLineage
Si ya usa OpenLineage para recoger información de linaje de otras fuentes de datos, puede importar eventos de OpenLineage al catálogo universal de Dataplex y mostrarlos en la consola de Google Cloud . Para obtener más información, consulta Integración con OpenLineage.
Limitaciones
- Toda la información de linaje se conserva en el sistema durante 30 días.
- La información de linaje se conserva aunque elimines la fuente de datos relacionada. Es decir, si eliminas una tabla de BigQuery y su entrada del catálogo universal de Dataplex, podrás seguir leyendo el linaje de esa tabla mediante la API durante un máximo de 30 días.
Acceder al linaje de datos
Para obtener más información sobre cómo acceder al linaje de datos, consulta Usar el linaje de datos con sistemas de Google Cloud y la API Data Lineage.
Precios
Dataplex Universal Catalog usa la SKU de procesamiento premium para cobrar por el linaje de datos. Para obtener más información, consulta los precios.
Para separar los cargos de linaje de datos de otros cargos en el SKU de procesamiento premium del catálogo universal de Dataplex, en el informe de facturación de Cloud, utilice la etiqueta
goog-dataplex-workload-typecon el valorLINEAGE.Si llamas a la API Data Lineage
OriginsourceTypecon un valor distinto deCUSTOM, se aplican costes adicionales.
Siguientes pasos
Sigue una guía de inicio rápido para hacer un seguimiento del linaje de datos de las tareas de copia y consulta de una tabla de BigQuery.
Consulta cómo usar el linaje de datos con Google Cloud sistemas.
Para obtener información administrativa, consulta las consideraciones sobre el linaje y el registro de auditoría del linaje de datos.