Integração com o SAP
Nesta página, descrevemos as etapas de integração para cargas de trabalho operacionais do SAP (SAP ECC e SAP S/4 HANA) na Cortex Framework Data Foundation. O Cortex Framework pode acelerar a integração de dados do SAP com o BigQuery usando modelos predefinidos de processamento de dados com pipelines do Dataflow até o BigQuery. Já o Cloud Composer programa e monitora esses pipelines do Dataflow para extrair insights dos dados operacionais do SAP.
O arquivo config.json no repositório do Cortex Framework Data Foundation configura as definições necessárias para transferir dados de
qualquer fonte de dados, incluindo SAP. Esse arquivo contém os seguintes parâmetros para cargas de trabalho operacionais do SAP:
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
}
A tabela a seguir descreve o valor de cada parâmetro operacional do SAP:
| Parâmetro | Significado | Valor padrão | Descrição |
SAP.deployCDC
|
Implantar a CDC | true
|
Gere scripts de processamento de CDC para serem executados como DAGs no Cloud Composer. |
SAP.datasets.raw
|
Conjunto de dados de destino bruto | - | Usado pelo processo de CDC, é onde a ferramenta de replicação coloca os dados da SAP. Se estiver usando dados de teste, crie um conjunto de dados vazio. |
SAP.datasets.cdc
|
Conjunto de dados processado pela CDC | - | Conjunto de dados que funciona como uma fonte para as visualizações de relatórios e como destino para os DAGs de registros processados. Se você estiver usando dados de teste, crie um conjunto de dados vazio. |
SAP.datasets.reporting
|
Conjunto de dados de relatórios SAP | "REPORTING"
|
Nome do conjunto de dados acessível aos usuários finais para geração de relatórios, em que as visualizações e as tabelas voltadas ao usuário são implantadas. |
SAP.SQLFlavor
|
Dialeto SQL para o sistema de origem | "ecc"
|
s4 ou ecc.
Para dados de teste, mantenha o valor padrão (ecc).
|
SAP.mandt
|
Mandante ou cliente | "100"
|
Mandante ou cliente padrão para SAP.
Para dados de teste, mantenha o valor padrão (100).
|
SAP.languages
|
Filtro de idioma | ["E","S"]
|
Códigos de idioma da SAP (SPRAS) a serem usados em campos relevantes (como nomes). |
SAP.currencies
|
Filtro de moeda | ["USD"]
|
Códigos de moeda de destino do SAP (TCURR) para conversão de moeda. |
Embora não haja uma versão mínima obrigatória do SAP, os modelos do ECC foram desenvolvidos na versão mais antiga compatível do SAP ECC. É esperado que haja diferenças nos campos entre nosso sistema e outros, independente da versão.
Modelo de dados
Esta seção descreve os modelos de dados da SAP (ECC e S/4HANA) usando os diagramas de relacionamento de entidades (ERD, na sigla em inglês).
SAP ECC

SAP S/4 HANA
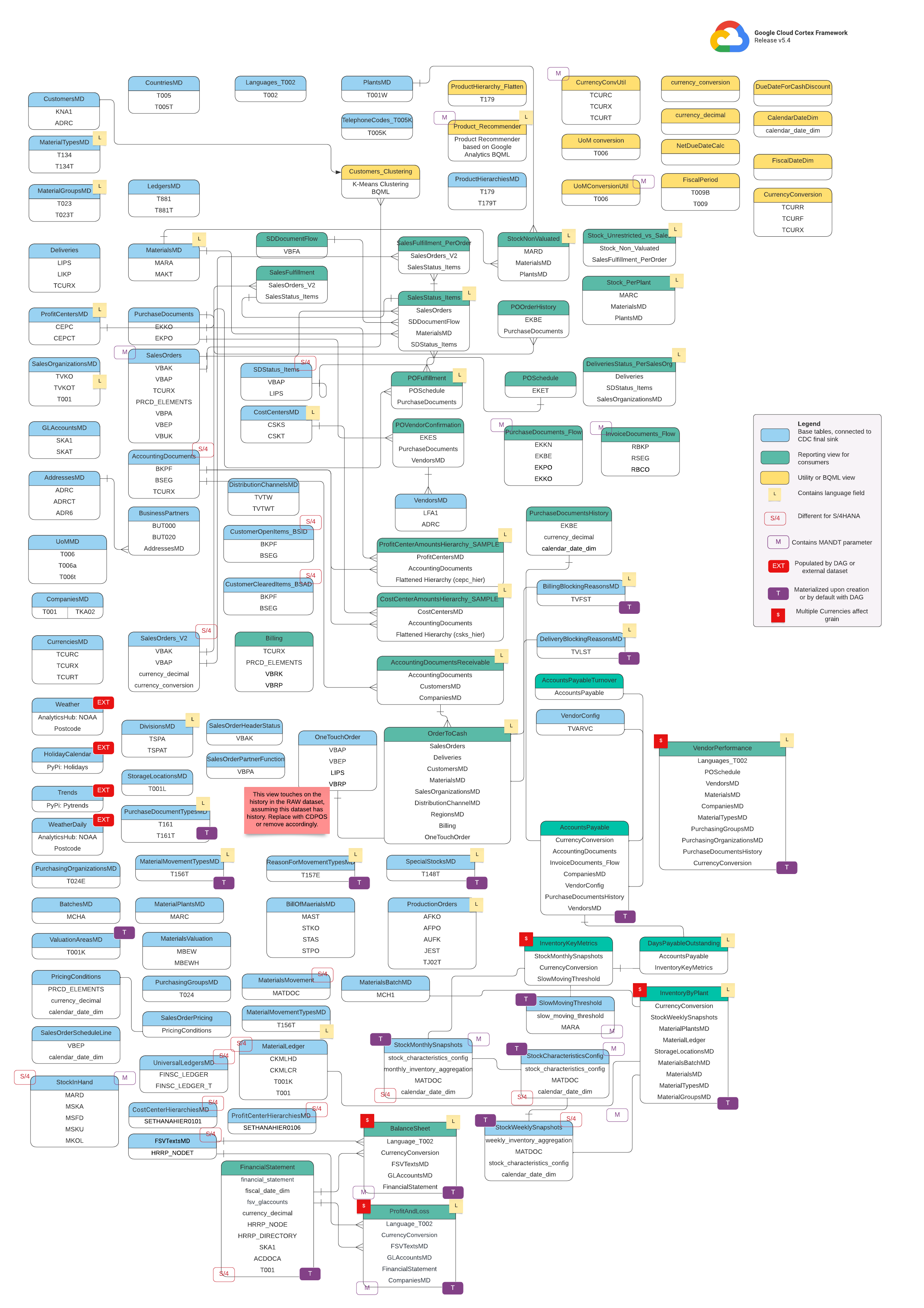
Visualizações básicas
Esses são os objetos azuis no diagrama ER e são visualizações em tabelas de CDC sem transformações além de alguns aliases de nomes de colunas. Consulte scripts em
src/SAP/SAP_REPORTING.
Vistas de relatórios
São os objetos verdes no DER e contêm os atributos dimensionais relevantes usados pelas tabelas de relatórios. Consulte scripts em
src/SAP/SAP_REPORTING.
Visualização de utilidade ou BQML
São os objetos amarelos no DER e contêm os fatos e dimensões unidos, além do tipo específico de visualização usado para análise e geração de relatórios de dados. Consulte scripts em
src/SAP/SAP_REPORTING.
Tags adicionais
As tags codificadas por cores neste DER representam os seguintes recursos das tabelas de relatórios:
| Tag | Cor | Descrição |
L
|
Amarelo | Essa tag se refere a um elemento ou atributo de dados que especifica o idioma em que os dados são armazenados ou mostrados. |
S/4
|
Vermelho | Essa tag indica que atributos específicos são específicos do SAP S/4HANA (esse objeto pode não estar no SAP ECC). |
MANDT
|
Roxo | Essa tag indica que atributos específicos contêm o parâmetro MANDT (representa o cliente ou ID do cliente) para determinar a qual instância de cliente ou empresa um registro de dados específico pertence. |
EXT
|
Vermelho | Essa tag indica que objetos específicos são preenchidos por DAGs ou conjuntos de dados externos. Isso significa que a entidade ou tabela marcada não é armazenada diretamente no próprio sistema SAP, mas pode ser extraída e carregada no SAP usando um DAG ou outro mecanismo. |
T
|
Roxo | Essa tag indica que atributos específicos serão materializados automaticamente usando o DAG configurado. |
S
|
Vermelho | Essa tag indica que os dados em uma entidade ou tabelas são influenciados ou afetados por várias moedas. |
Pré-requisitos para a replicação do SAP
Considere os seguintes pré-requisitos para dados de replicação do SAP com a Cortex Framework Data Foundation:
- Integridade dos dados: a Cortex Framework Data Foundation espera que as tabelas do SAP sejam replicadas com nomes de campos, tipos e estruturas de dados idênticos aos que existem no SAP. Desde que as tabelas sejam replicadas com o mesmo formato, nomes de campos e granularidade da origem, não é necessário usar uma ferramenta de replicação específica.
- Nomenclatura de tabelas: os nomes de tabela do BigQuery precisam ser criados em letras minúsculas.
- Configuração da tabela: a lista de tabelas usadas pelos modelos do SAP está disponível e pode ser configurada no arquivo
cdc_settings.yamlda CDC (captura de dados alterados). Se uma tabela não for listada durante a implantação, os modelos que dependem dela vão falhar, mas outros modelos não dependentes serão implantados com sucesso. - Considerações específicas BigQuery Connector para SAP:
- Mapeamento de tabela: sobre a opção de conversão, siga a documentação padrão de mapeamento de tabela.
- Desativar a compactação de registros: recomendamos desativar a compactação de registros que pode afetar a camada de CDC do Cortex e o conjunto de dados de relatórios do Cortex.
- Replicação de metadados: se você não estiver implantando dados de teste e gerando scripts DAG de CDC durante a implantação, verifique se a tabela
DD03Lde metadados do SAP foi replicada do SAP no projeto de origem. Essa tabela contém metadados sobre tabelas, como a lista de chaves, e é necessária para que o gerador de CDC e o resolvedor de dependências funcionem. Essa tabela também permite adicionar tabelas não cobertas pelo modelo, como tabelas personalizadas ou Z, para que os scripts de CDC possam ser gerados. Como lidar com pequenas variações no nome da tabela: se houver pequenas diferenças no nome de uma tabela, algumas visualizações poderão não encontrar os campos obrigatórios, porque os sistemas SAP podem ter pequenas variações devido a versões ou complementos, ou porque algumas ferramentas de replicação podem ter um tratamento ligeiramente diferente de caracteres especiais. Recomendamos executar a implantação com
turboMode : falsepara identificar a maioria das falhas em uma tentativa. Confira alguns problemas comuns:- Os campos que começam com
_(por exemplo,_DATAAGING) têm o_removido. - Os campos não podem começar com
/no BigQuery.
Nesse caso, ajuste a visualização com falha para selecionar o campo conforme ele é inserido pela ferramenta de replicação escolhida.
- Os campos que começam com
Como replicar dados brutos do SAP
O objetivo da Data Foundation é expor modelos de dados e análises para relatórios e aplicativos. Os modelos consomem os dados replicados de um sistema SAP usando uma ferramenta de replicação preferida, como as listadas nos Guias de integração de dados para SAP.
Os dados do sistema SAP (ECC ou S/4 HANA) são replicados na forma bruta.
Os dados são copiados diretamente do SAP para o BigQuery sem
alterações na estrutura. É essencialmente uma imagem espelhada das tabelas no seu sistema SAP. O BigQuery usa nomes de tabelas em letras minúsculas para o modelo de dados. Portanto, mesmo que as tabelas do SAP tenham nomes em maiúsculas (como MANDT), elas são convertidas para minúsculas (como mandt) no BigQuery.
Processamento de captura de dados alterados (CDC)
Escolha um dos seguintes modos de processamento de CDC que o Cortex Framework oferece para ferramentas de replicação carregarem registros do SAP:
- Append-always: insere todas as mudanças em um registro com um carimbo de data/hora e uma flag de operação (Insert, Update, Delete), para que a última versão possa ser identificada.
- Atualizar ao chegar (mesclar ou upsert): cria uma versão atualizada de um registro ao chegar no
change data capture processed. Ele realiza a operação de CDC no BigQuery.
A Data Foundation do Cortex Framework é compatível com os dois modos, mas, para o modo de adição sempre, ela fornece modelos de processamento de CDC. Alguns recursos precisam ser comentados para atualização na página de destino. Por exemplo, OneTouchOrder.sql e todas as consultas dependentes. A capacidade pode ser substituída por tabelas como CDPOS.

Configurar modelos de CDC para ferramentas que fazem a replicação no modo "append-always"
Recomendamos configurar o cdc_settings.yaml de acordo com suas necessidades.
Algumas frequências padrão podem resultar em custos desnecessários se a empresa não precisar desse nível de atualização de dados. Se você estiver usando uma ferramenta que é executada no modo
"append-always", a Data Foundation do Cortex Framework vai fornecer modelos de CDC
para automatizar as atualizações e criar uma versão mais recente
da verdade ou do gêmeo digital no conjunto de dados processado pela CDC.
Você pode usar a configuração no arquivo cdc_settings.yaml se precisar gerar
scripts de processamento de CDC. Consulte Configurar o processamento de CDC para ver as opções. Para dados de teste, deixe esse arquivo como padrão.
Faça todas as mudanças necessárias nos modelos de DAG de acordo com sua instância do Airflow ou do Cloud Composer. Para mais informações, consulte Como reunir configurações do Cloud Composer.
Opcional: se quiser adicionar e processar tabelas individualmente
após a implantação, modifique o arquivo cdc_settings.yaml
para processar apenas
as tabelas necessárias e execute novamente o módulo especificado chamando
src/SAP_CDC/cloudbuild.cdc.yaml diretamente.
Configurar o processamento de CDC
Durante a implantação, é possível mesclar mudanças em tempo real usando uma visualização no BigQuery ou programando uma operação de mesclagem no Cloud Composer (ou em qualquer outra instância do Apache Airflow). O Cloud Composer pode programar os scripts para processar as operações de mesclagem periodicamente. Os dados são atualizados para a versão mais recente sempre que as operações de mesclagem são executadas. No entanto, operações de mesclagem mais frequentes resultam em custos mais altos. Personalize a frequência programada de acordo com as necessidades da sua empresa. Para mais informações, consulte programação compatível com o Apache Airflow.
O exemplo de script a seguir mostra um trecho do arquivo de configuração:
data_to_replicate:
- base_table: adrc
load_frequency: "@hourly"
- base_table: adr6
target_table: adr6_cdc
load_frequency: "@daily"
Este arquivo de amostra de configuração faz o seguinte:
- Crie uma cópia de
SOURCE_PROJECT_ID.REPLICATED_DATASET.adrcemTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc, se este último não existir. - Crie um script de CDC no bucket especificado.
- Crie uma cópia de
SOURCE_PROJECT_ID.REPLICATED_DATASET.adr6emTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdc, se este último não existir. - Crie um script de CDC no bucket especificado.
Se você quiser criar DAGs ou visualizações de tempo de execução para processar mudanças em tabelas
que existem no SAP e não estão listadas no arquivo, adicione-as a ele
antes da implantação. Isso funciona desde que a tabela DD03L seja replicada no conjunto de dados de origem e o esquema da tabela personalizada esteja presente nela.
Por exemplo, a configuração a seguir cria um script de CDC para a tabela personalizada zztable_customer e uma visualização de tempo de execução para verificar mudanças em tempo real em outra tabela personalizada chamada zzspecial_table:
- base_table: zztable_customer
load_frequency: "@daily"
- base_table: zzspecial_table
load_frequency: "RUNTIME"
Exemplo de modelo gerado
O modelo a seguir gera o processamento de mudanças. Modificações, como o nome do campo de carimbo de data/hora ou operações adicionais, podem ser modificadas neste ponto:
MERGE `${target_table}` T
USING (
SELECT *
FROM `${base_table}`
WHERE
recordstamp > (
SELECT IF(
MAX(recordstamp) IS NOT NULL,
MAX(recordstamp),
TIMESTAMP("1940-12-25 05:30:00+00"))
FROM `${target_table}` )
) S
ON ${p_key}
WHEN MATCHED AND S.operation_flag='D' AND S.is_deleted = true THEN
DELETE
WHEN NOT MATCHED AND S.operation_flag='I' THEN
INSERT (${fields})
VALUES
(${fields})
WHEN MATCHED AND S.operation_flag='U' THEN
UPDATE SET
${update_fields}
Como alternativa, se sua empresa precisar de insights quase em tempo real e a ferramenta de replicação for compatível, a ferramenta de implantação aceitará a opção RUNTIME.
Isso significa que um script da CDC não será gerado. Em vez disso, uma visualização faria a varredura e buscaria o registro mais recente disponível no tempo de execução para consistência imediata.
Estrutura de diretórios para DAGs e scripts de CDC
A estrutura de bucket do Cloud Storage para DAGs de CDC do SAP espera que os arquivos SQL sejam gerados em /data/bq_data_replication, como no exemplo a seguir.
É possível modificar esse caminho antes da implantação. Se você ainda não tiver um ambiente do Cloud Composer disponível, crie um depois e mova os arquivos para o bucket de DAGs.
with airflow.DAG("CDC_BigQuery_${base table}",
template_searchpath=['/home/airflow/gcs/data/bq_data_replication/'], ##example
default_args=default_dag_args,
schedule_interval="${load_frequency}") as dag:
start_task = DummyOperator(task_id="start")
copy_records = BigQueryOperator(
task_id='merge_query_records',
sql="${query_file}",
create_disposition='CREATE_IF_NEEDED',
bigquery_conn_id="sap_cdc_bq", ## example
use_legacy_sql=False)
stop_task = DummyOperator (task_id="stop")
start_task >> copy_records >> stop_task
Os scripts que processam dados no Airflow ou no Cloud Composer são gerados separadamente dos scripts específicos do Airflow. Isso permite que você faça a portabilidade desses scripts para outra ferramenta de sua escolha.
Campos de CDC obrigatórios para operações MERGE
Especifique os seguintes parâmetros para a geração automática de processos em lote de CDC:
- Projeto e conjunto de dados de origem:conjunto de dados em que os dados do SAP são transmitidos ou replicados. Para que os scripts de CDC funcionem por padrão, as tabelas precisam ter
um campo de carimbo de data/hora (chamado "recordstamp") e um campo de operação com os
seguintes valores, todos definidos durante a replicação:
- I: para inserir.
- U: para "Update" (Atualizar).
- D: para exclusão.
- Projeto e conjunto de dados de destino para o processamento de CDC: por padrão, o script gerado cria as tabelas com base em uma cópia do conjunto de dados de origem, caso elas não existam.
- Tabelas replicadas: tabelas para as quais os scripts precisam ser gerados.
- Frequência de processamento: seguindo a notação Cron, com que frequência os DAGs devem ser executados:
- Bucket de destino do Cloud Storage em que os arquivos de saída da CDC são copiados.
- Nome da conexão: o nome da conexão usada pelo Cloud Composer.
- (Opcional) Nome da tabela de destino:disponível se o resultado do processamento de CDC permanecer no mesmo conjunto de dados que o destino.
Otimização de performance para tabelas de CDC
Para determinados conjuntos de dados de CDC, talvez seja interessante aproveitar o particionamento de tabelas e o clustering de tabelas do BigQuery, ou ambos. Essa escolha depende dos seguintes fatores:
- Tamanho e dados da tabela.
- Colunas disponíveis na tabela.
- Necessidade de dados em tempo real com visualizações.
- Dados materializados como tabelas.
Por padrão, as configurações de CDC não aplicam particionamento ou clustering de tabelas.
A escolha é sua para configurar com base no que funciona melhor para você. Para criar tabelas com partições ou clusters, atualize o arquivo cdc_settings.yaml com as configurações relevantes. Para mais informações, consulte
Partição de tabela
e Configurações de cluster.
- Esse recurso só se aplica quando um conjunto de dados em
cdc_settings.yamlé configurado para replicação como uma tabela (por exemplo,load_frequency = "@daily") e não definido como uma visualização (load_frequency = "RUNTIME"). - Uma tabela pode ser tabela particionada e em cluster.
Se você estiver usando uma ferramenta de replicação que permite partições no conjunto de dados bruto, como o BigQuery Connector para SAP, é recomendável definir partições com base em tempo nas tabelas brutas. O tipo de partição funciona melhor se corresponder à frequência dos DAGs de CDC na configuração cdc_settings.yaml. Para mais informações, consulte
Considerações de design para a modelagem de dados SAP no BigQuery.
Opcional: configurar o módulo de inventário do SAP
O módulo de inventário do Cortex Framework SAP inclui visualizações InventoryKeyMetrics
e InventoryByPlant que fornecem insights importantes sobre seu inventário.
Essas visualizações são apoiadas por tabelas de snapshots mensais e semanais usando DAGs especializados. Ambos podem ser executados ao mesmo tempo e não vão interferir um no outro.
Para atualizar uma ou as duas tabelas de snapshot, siga estas etapas:
Atualize
SlowMovingThreshold.sqleStockCharacteristicsConfig.sqlpara definir o limite de movimentação lenta e as características de estoque para diferentes tipos de materiais, com base nos seus requisitos.Para carga inicial ou atualização completa, execute os DAGs
Stock_Monthly_Snapshots_InitialeStock_Weekly_Snapshots_Initial.Para atualizações subsequentes, programe ou execute os seguintes DAGs:
- Atualizações mensais e semanais:
Stock_Monthly_Snapshots_Periodical_UpdateStock_Weekly_Snapshots_periodical_Update
- Atualização diária:
Stock_Monthly_Snapshots_Daily_UpdateStock_Weekly_Snapshots_Update_Daily
- Atualizações mensais e semanais:
Atualize as visualizações intermediárias
StockMonthlySnapshotseStockWeeklySnapshots, seguidas pelas visualizaçõesInventoryKeyMetricseInventoryByPlants, respectivamente, para expor os dados atualizados.
Opcional: configurar a visualização "Textos da hierarquia de produtos"
A visualização "Textos da hierarquia de produtos" simplifica materiais e hierarquias de produtos. A tabela resultante pode ser usada para fornecer ao complemento Trends uma lista de termos e recuperar o interesse ao longo do tempo. Configure
essa visualização seguindo estas etapas:
- Ajuste os níveis da hierarquia e o idioma no arquivo
prod_hierarchy_texts.sql, nos marcadores de## CORTEX-CUSTOMER. Se a hierarquia de produtos tiver mais níveis, talvez seja necessário adicionar uma instrução SELECT semelhante à Expressão de tabela comum
h1_h2_h3.Pode haver outras personalizações dependendo dos sistemas de origem. Recomendamos envolver os usuários ou analistas de negócios no início do processo para ajudar a identificar esses problemas.
Opcional: configurar visualizações de nivelamento de hierarquia
A partir da versão v6.0, o Cortex Framework oferece suporte ao nivelamento de hierarquia como visualizações de relatórios. Essa é uma grande melhoria em relação ao aplanador de hierarquia legada, já que agora ele aplana toda a hierarquia, otimiza melhor para o S/4 usando tabelas específicas do S/4 em vez de tabelas legadas do ECC e também melhora significativamente o desempenho.
Resumo das visualizações de relatórios
Encontre as seguintes visualizações relacionadas ao nivelamento da hierarquia:
| Tipo de hierarquia | Tabela com hierarquia simplificada | Visualizações para visualizar a hierarquia nivelada | Lógica de integração de P&L usando essa hierarquia |
| Versão do demonstrativo financeiro (FSV) | fsv_glaccounts
|
FSVHierarchyFlattened
|
ProfitAndLossOverview
|
| Centro de lucro | profit_centers
|
ProfitCenterHierarchyFlattened
|
ProfitAndLossOverview_ProfitCenterHierarchy
|
| Centro de custos | cost_centers
|
CostCenterHierarchyFlattened
|
ProfitAndLossOverview_CostCenterHierarchy
|
Considere o seguinte ao usar visualizações de nivelamento de hierarquia:
- As visualizações de hierarquia nivelada são funcionalmente equivalentes às tabelas geradas pela solução legada de nivelamento de hierarquia.
- As visões gerais não são implantadas por padrão, porque mostram apenas a lógica de BI. Encontre o código-fonte deles no diretório
src/SAP/SAP_REPORTING.
Configurar o nivelamento da hierarquia
Com base na hierarquia com que você está trabalhando, os seguintes parâmetros de entrada são obrigatórios:
| Tipo de hierarquia | Parâmetro obrigatório | Campo de origem (ECC) | Campo de origem (S4) |
| Versão do demonstrativo financeiro (FSV) | Gráfico de contas | ktopl
|
nodecls
|
| Nome da hierarquia | versn
|
hryid
|
|
| Centro de lucro | Classe do conjunto | setclass
|
setclass
|
| Unidade organizacional: área de controle ou chave adicional para o conjunto. | subclass
|
subclass
|
|
| Centro de custos | Classe do conjunto | setclass
|
setclass
|
| Unidade organizacional: área de controle ou chave adicional para o conjunto. | subclass
|
subclass
|
Se você não tiver certeza sobre os parâmetros exatos, pergunte a um consultor de finanças ou controle do SAP.
Depois que os parâmetros forem coletados, atualize os comentários ## CORTEX-CUSTOMER em cada um dos diretórios correspondentes, com base nos seus requisitos:
| Tipo de hierarquia | Localização do código |
| Versão do demonstrativo financeiro (FSV) | src/SAP/SAP_REPORTING/local_k9/fsv_hierarchy
|
| Centro de lucro | src/SAP/SAP_REPORTING/local_k9/profitcenter_hierarchy
|
| Centro de custos | src/SAP/SAP_REPORTING/local_k9/costcenter_hierarchy
|
Se aplicável, atualize os comentários ## CORTEX-CUSTOMER nas visualizações de relatórios relevantes no diretório src/SAP/SAP_REPORTING.
Detalhes sobre a solução
As seguintes tabelas de origem são usadas para o nivelamento da hierarquia:
| Tipo de hierarquia | Tabelas de origem (ECC) | Tabelas de origem (S4) |
| Versão do demonstrativo financeiro (FSV) |
|
|
| Centro de lucro |
|
|
| Centro de custos |
|
|
Como visualizar as hierarquias
A solução de nivelamento da hierarquia SAP do Cortex nivela toda a hierarquia. Se você quiser criar uma representação visual da hierarquia carregada que seja comparável ao que o SAP mostra na UI, consulte uma das visualizações para visualizar hierarquias simplificadas com a condição IsLeafNode=True.
Migrar da solução legada de nivelamento de hierarquia
Para migrar da solução legada de nivelamento de hierarquia antes do Cortex v6.0, substitua as tabelas conforme mostrado na tabela a seguir. Verifique se os nomes dos campos estão corretos, já que alguns foram ligeiramente modificados. Por exemplo, prctr em cepc_hier
agora é profitcenter na tabela profit_centers.
| Tipo de hierarquia | Substitua esta tabela: | Com: |
| Versão do demonstrativo financeiro (FSV) | ska1_hier
|
fsv_glaccounts
|
| Centro de lucro | cepc_hier
|
profit_centers
|
| Centro de custos | csks_hier
|
cost_centers
|
Opcional: configurar o módulo financeiro da SAP
O módulo de finanças do SAP do Cortex Framework inclui visualizações FinancialStatement, BalanceSheet e ProfitAndLoss que fornecem insights financeiros importantes.
Para atualizar essas tabelas de finanças, siga estas etapas:
Para o carregamento inicial
- Após a implantação, verifique se o conjunto de dados de CDC está preenchido corretamente (execute as DAGs de CDC conforme necessário).
- Verifique se as visualizações de simplificação da hierarquia estão configuradas corretamente para os tipos de hierarquias que você está usando (FSV, centro de custo e centro de lucro).
Execute o DAG
financial_statement_initial_load.Se implantado como tabelas (recomendado), atualize o seguinte em ordem executando os DAGs correspondentes:
Financial_StatementsBalanceSheetsProfitAndLoss
Para atualização periódica
- Verifique se as visualizações de simplificação da hierarquia estão configuradas e atualizadas corretamente para os tipos de hierarquias que você está usando (FSV, centro de custo e centro de lucro).
Programe ou execute o DAG
financial_statement_periodical_load.Se implantado como tabelas (recomendado), atualize o seguinte em ordem executando os DAGs correspondentes:
Financial_StatementsBalanceSheetsProfitAndLoss
Para visualizar os dados dessas tabelas, consulte as seguintes visões gerais:
ProfitAndLossOverview.sqlse você estiver usando a hierarquia de FSV.ProfitAndLossOverview_CostCenter.sqlse você estiver usando a hierarquia de centro de custo.ProfitAndLossOverview_ProfitCenter.sqlse você estiver usando a hierarquia do centro de lucro.
Opcional: ativar DAGs dependentes de tarefas
O Cortex Framework também oferece configurações de dependência recomendadas para a maioria das tabelas SQL do SAP (ECC e S/4 HANA), em que todas as tabelas dependentes podem ser atualizadas por um único DAG. Você pode personalizar ainda mais. Para mais informações, consulte DAGs dependentes de tarefas.
A seguir
- Para mais informações sobre outras fontes de dados e cargas de trabalho, consulte Fontes de dados e cargas de trabalho.
- Para mais informações sobre as etapas de implantação em ambientes de produção, consulte Pré-requisitos de implantação da Data Foundation do framework Cortex.