与 Salesforce (SFDC) 集成
本页介绍了在 Cortex 框架数据基础中集成 Salesforce (SFDC) 运营工作负载的步骤。Cortex Framework 通过 Dataflow 流水线将 Salesforce 中的数据集成到 BigQuery 中,而 Cloud Composer 会调度和监控这些 Dataflow 流水线,以便从数据中获取分析洞见。
配置文件
Cortex Framework Data Foundation 代码库中的 config.json 文件用于配置从任何数据源(包括 Salesforce)转移数据所需的设置。此文件包含以下参数,用于运行 Salesforce 工作负载:
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
下表介绍了每个 SFDC 运营参数的值:
| 参数 | 含义 | 默认值 | 说明 |
SFDC.deployCDC
|
部署 CDC | true
|
生成 CDC 处理脚本,以便在 Cloud Composer 中作为 DAG 运行。请参阅有关 Salesforce Sales Cloud 的不同提取选项的文档。 |
SFDC.createMappingViews
|
创建映射视图 | true
|
提供的用于从 Salesforce API 中提取新记录的 DAG 会在着陆时更新记录。如果此值设置为 true,则会在 CDC 处理的数据集中生成视图,以显示原始数据集中的“最新版本的事实”表。如果值为 false 且 SFDC.deployCDC 为 true,则会生成基于 SystemModstamp 的变更数据捕获 (CDC) 处理 DAG。详细了解 Salesforce 的 CDC 处理。
|
SFDC.createPlaceholders
|
创建占位符 | true
|
创建空的占位表,以防提取流程未生成这些表,从而允许下游报告部署正常执行。 |
SFDC.datasets.raw
|
原始着陆数据集 | - | 由 CDC 进程使用,复制工具会将来自 Salesforce 的数据放置在此处。如果使用测试数据,请创建空数据集。 |
SFDC.datasets.cdc
|
CDC 处理后的数据集 | - | 用作报告视图的来源以及已处理记录 DAG 的目标位置的数据集。如果使用测试数据,请创建空数据集。 |
SFDC.datasets.reporting
|
报告数据集 SFDC | "REPORTING_SFDC"
|
最终用户可用于报告的数据集的名称,其中部署了视图和面向用户的表。 |
SFDC.currencies
|
过滤币种 | [ "USD" ]
|
如果您不使用测试数据,请根据您的业务情况输入一种货币(例如 [ "USD" ])或多种货币(例如 [ "USD", "CAD" ])。这些值用于替换分析模型中 SQL 中的占位符(如果可用)。
|
数据模型
本部分使用实体关系图 (ERD) 介绍了 Salesforce (SFDC) 数据模型。
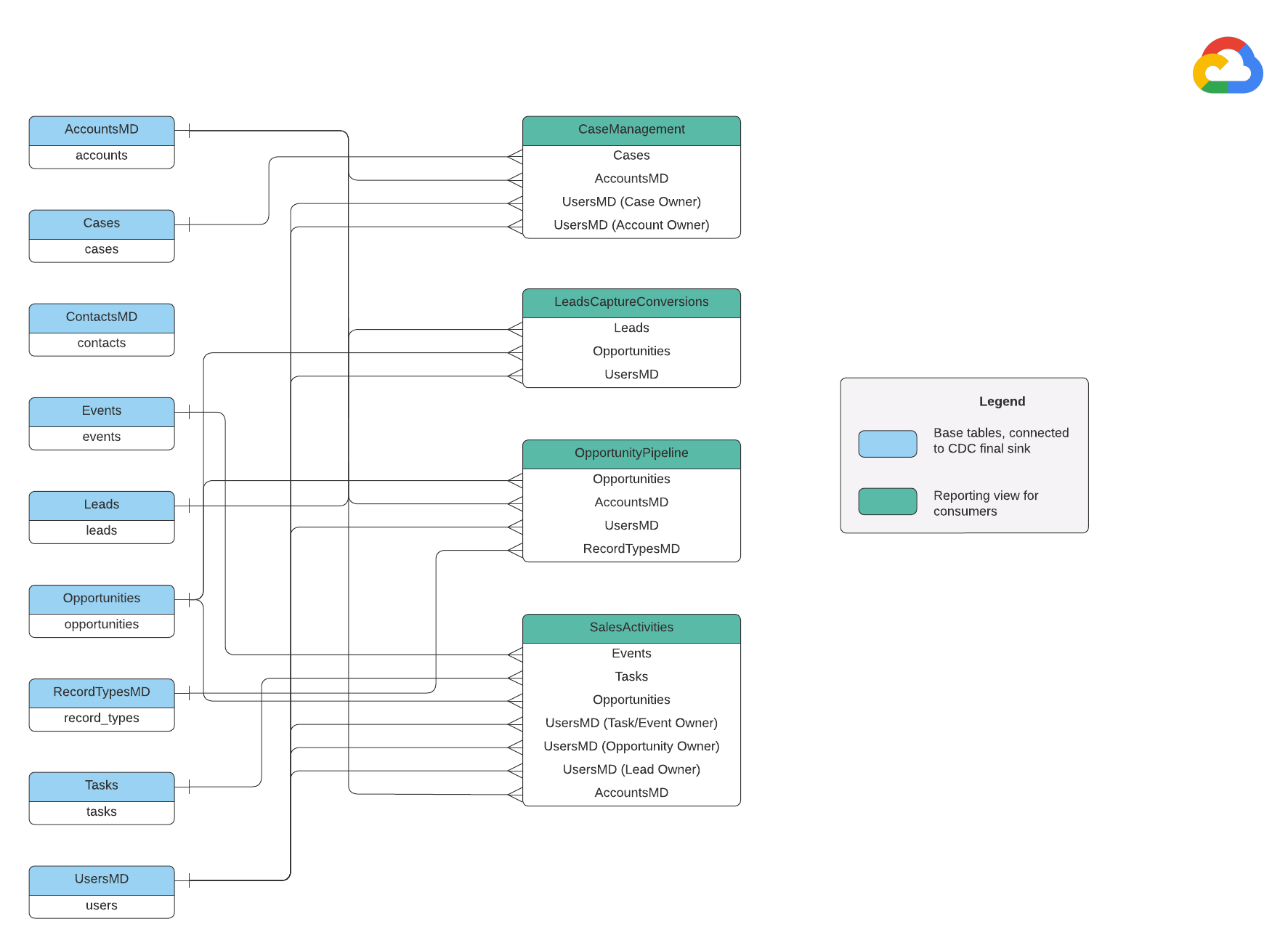
基本视图
这些是 ERD 中的蓝色对象,是 CDC 表的视图,除了某些列名别名之外,没有其他转换。请参阅 src/SFDC/src/reporting/ddls 中的脚本。
报告数据视图
这些是 ERD 中的绿色对象,包含报告表使用的相关维度属性。请参阅 src/SFDC/src/reporting/ddls 中的脚本。
Salesforce 数据要求
本部分概述了 Salesforce 数据在使用 Cortex Framework 时需要采用的结构。
- 表格结构:
- 命名:表名使用
snake_case(用下划线分隔的小写字词),并且采用复数形式。例如some_objects。 - 数据类型:列会保持与 Salesforce 中表示的数据类型相同的数据类型。
- 可读性:某些字段名称可能会略作调整,以便在报告层中更清晰地显示。
- 命名:表名使用
- 空表和部署:在部署过程中,系统会自动将原始数据集中缺少的任何必需表创建为空表。这可确保顺利执行 CDC 部署步骤。
- CDC 要求:
Id和SystemModstamp字段对于 CDC 脚本跟踪数据变化至关重要。它们可以具有这些确切的名称,也可以具有不同的名称。提供的原始处理脚本会自动从 API 中提取这些字段,并更新目标复制表。Id:用作每条记录的唯一标识符。SystemModstamp:此字段存储一个时间戳,用于指示上次修改记录的时间。
- 原始处理脚本:提供的原始处理脚本不需要额外的 (CDC) 处理。此行为在部署期间默认设置。
货币换算的源表
Salesforce 允许您通过两种方式管理币种:
- 基本:这是默认设置,所有数据都使用单一币种。
- 高级:根据汇率在多种货币之间进行换算(需要启用高级币种管理)。
如果您使用高级币种管理,Salesforce 会使用两个特殊表:
- CurrencyTypes:此表存储有关您使用的不同币种(例如美元、欧元等)的信息。
- DatedConversionRates:此表包含不同时间段内各种货币之间的汇率。
如果您使用高级币种管理,Cortex Framework 会要求存在这些表。如果您不使用高级币种管理功能,可以从配置文件 (src/SFDC/config/ingestion_settings.yaml) 中移除与这些表相关的条目。此步骤可防止系统不必要地尝试从不存在的表中提取数据。
将 SFDC 数据加载到 BigQuery 中
Cortex Framework 提供了一种基于 Python 脚本的复制解决方案,该脚本在 Apache Airflow 和 Salesforce Bulk API 2.0 中进行调度。您可以根据需要在所选工具中调整和安排这些 Python 脚本。如需了解详情,请参阅 SFDC 提取模块。
Cortex Framework 还提供了三种不同的数据集成方法,具体取决于数据的来源和管理方式:
- API 调用:此选项适用于可通过 API 直接访问的数据。Cortex Framework 可以调用该 API,抓取数据并将其存储在 BigQuery 中的“原始”数据集中。如果数据集中存在现有记录,Cortex Framework 可以使用新数据更新这些记录。
- 结构映射视图:如果您已通过其他工具将数据加载到 BigQuery 中,但数据结构与 Cortex Framework 的需求不符,此方法非常有用。Cortex Framework 使用“视图”(类似于虚拟表)将现有数据结构转换为 Cortex Framework 报告功能所需的格式。
CDC(变更数据捕获)处理脚本:此选项专门针对不断变化的数据而设计。CDC 脚本会跟踪这些更改,并相应地更新 BigQuery 中的数据。这些脚本依赖于数据中的两个特殊字段:
Id:每条记录的唯一标识符。SystemModstamp:指示记录更改时间的时间戳。
如果您的数据不包含这些确切的名称,您可以调整脚本,使其能够识别具有不同名称的数据。在此过程中,您还可以向数据架构添加自定义字段。例如,包含“客户”对象数据的源表应具有原始的
Id和SystemModstamp字段。如果这些字段具有不同的名称,则必须更新src/SFDC/src/table_schema/accounts.csv文件,将Id字段的名称映射到AccountId,并将任何系统修改时间戳字段映射到SystemModstamp。如需了解详情,请参阅 SystemModStamp 文档。
如果您已通过其他工具加载数据(并且数据会不断更新),Cortex 仍可使用这些数据。CDC 脚本附带映射文件,可将现有数据结构转换为 Cortex Framework 所需的格式。在此过程中,您甚至可以向数据添加自定义字段。
配置 API 集成和 CDC
如需将 Salesforce 数据导入 BigQuery,您可以使用以下方法:
- 用于 API 调用的 Cortex 脚本:为 Salesforce 或您选择的数据复制工具提供复制脚本。关键在于,您导入的数据应与通过 Salesforce API 导入的数据看起来相同。
- 复制工具和附加始终:如果您使用的是复制工具,则此方式适用于可以添加新数据记录 (_appendalways_pattern) 或更新现有记录的工具。
- 复制工具和添加新记录:如果该工具不更新记录,而是将所有更改复制为新记录到目标(原始)表中,Cortex Data Foundation 会提供创建 CDC 处理脚本的选项。如需了解详情,请参阅 CDC 流程。

为确保数据与 Cortex Framework 的预期一致,您可以调整映射配置,以映射复制工具或现有架构。这会生成与 Cortex Framework Data Foundation 所需结构兼容的映射视图。
使用 ingestion_settings.yaml 文件配置脚本的生成,以调用 Salesforce API 并将数据复制到原始数据集(第 salesforce_to_raw_tables 部分),以及配置脚本的生成,以处理传入原始数据集和 CDC 处理后的数据集(第 raw_to_cdc_tables 部分)的更改。
默认情况下,用于从 API 读取数据的脚本会将更改更新到原始数据集中,因此不需要 CDC 处理脚本,而是创建映射视图来使源架构与预期架构保持一致。
如果 config.json 中的值为 SFDC.createMappingViews=true,则不会执行 CDC 处理脚本的生成(默认行为)。如果需要 CDC 脚本,请设置 SFDC.createMappingViews=false。在第二步中,您还可以根据 Cortex Framework Data Foundation 的要求,将源架构映射到所需的架构。
以下 setting.yaml 配置文件示例展示了当复制工具将数据直接更新到复制的数据集中时(如 option 3 中所示),如何生成映射视图(即,不需要 CDC,只需要重新映射表和字段名称)。由于不需要 CDC,只要 config.json 文件中的参数 SFDC.createMappingViews 保持为 true,此选项就会执行。
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
在此示例中,从相应部分移除基本表或所有基本表的配置会跳过生成相应基本表或整个部分的 DAG,如 salesforce_to_raw_tables 所示。对于此场景,设置参数 deployCDC : False 的效果与不设置参数的效果相同,因为不需要生成 CDC 处理脚本。
数据映射
您需要将传入的数据字段映射到 Cortex Data Foundation 预期的格式。例如,源数据系统中名为 unicornId 的字段应在 Cortex Data Foundation 中重命名并识别为 AccountId(数据类型为字符串):
- 源字段:
unicornId(源系统中使用的名称) - Cortex 字段:
AccountId(Cortex 预期的名称) - 数据类型:
String(Cortex 预期的数据类型)
映射多态字段
Cortex Framework Data Foundation 支持映射多态字段,即名称可能不同但结构保持一致的字段。通过在相应的映射 CSV 文件中添加 [Field Name]_Type 项,可以复制多态字段类型名称(例如 Who.Type):src/SFDC/src/table_schema/tasks.csv。例如,如果您需要复制 Task 对象的 Who.Type 字段,请添加 Who_Type,Who_Type,STRING 行。这会定义一个名为 Who.Type 的新字段,该字段会映射到自身(保持相同的名称),并且具有字符串数据类型。
修改 DAG 模板
您可能需要根据 Airflow 或 Cloud Composer 实例的要求调整 CDC 的 DAG 模板或原始数据处理的 DAG 模板。如需了解详情,请参阅收集 Cloud Composer 设置。
如果您不需要通过 API 调用生成 CDC 或原始数据,请设置 deployCDC=false。或者,您也可以移除 ingestion_settings.yaml 中相应部分的内容。如果已知数据结构与 Cortex Framework Data Foundation 预期的数据结构一致,您可以跳过生成映射视图的步骤,只需设置 SFDC.createMappingViews=false 即可。
配置提取模块
本部分介绍了使用 Data Foundation 提供的 Salesforce 到 BigQuery 提取模块的步骤。您的要求和流程可能会因您的系统和现有配置而异。您也可以使用其他可用工具。
设置凭据和关联的应用
以管理员身份登录 Salesforce 实例,完成以下操作:
- 在 Salesforce 中创建或确定符合以下要求的个人资料:
Permission for Apex REST Services and API Enabled是在系统权限下授予的。- 为要复制的所有对象授予
View All权限。例如,“客户”和“支持请求”。向您的安全管理员咨询是否存在限制或问题。 - 未授予与用户界面登录相关的任何权限,例如 Lightning Experience 中的 Salesforce Anywhere、移动设备上的 Salesforce Anywhere、Lightning Experience 用户和 Lightning 登录用户。检查是否存在安全管理员施加的限制或问题。
- 在 Salesforce 中创建用户或使用现有用户。您需要知道用户的用户名、密码和安全令牌。请考虑以下事项:
- 最好是专门用于执行此复制的用户。
- 应将用户分配给您在第 1 步中创建或确定的个人资料。
- 您可以在此处查看用户名并重置密码。
- 如果您没有安全令牌,并且该令牌未被其他进程使用,则可以重置安全令牌。
- 创建关联的应用。这是唯一一种通信渠道,可借助配置文件、Salesforce API、标准用户凭据及其安全令牌,从外部世界建立与 Salesforce 的连接。
- 按照说明为 API 集成启用 OAuth 设置。
- 确保在 API(启用 OAuth 设置)部分中启用了
Require Secret for Web Server Flow和Require Secretfor Refresh Token Flow。 - 请参阅相关文档,了解如何获取消费者密钥(稍后将用作客户端 ID)。请咨询您的安全管理员,了解是否存在问题或限制。
- 将您的关联应用分配给创建的配置文件。
- 在 Salesforce 主屏幕的右上角,选择设置。
- 在快速查找框中,输入
profile,然后选择个人资料。搜索在第 1 步中创建的配置文件。 - 打开配置文件。
- 点击已分配的关联应用链接。
- 点击修改。
- 添加新创建的关联的应用。
- 点击保存按钮。
设置 Secret Manager
配置 Secret Manager 以存储连接详细信息。Salesforce-to-BigQuery 模块依赖于 Secret Manager 来安全地存储连接到 Salesforce 和 BigQuery 所需的凭据。这种方法可避免在代码或配置文件中直接泄露密码等敏感信息,从而提高安全性。
创建具有以下规范的 Secret。如需了解更详细的说明,请参阅创建 Secret。
- Secret 名称:
airflow-connections-salesforce-conn Secret 值:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`替换以下内容:
- 将
USERNAME替换为您的用户名。 - 将
PASSWORD替换为您的密码。 - 将
INSTANCE_NAME替换为实例名称。 - 将
CLIENT_ID替换为您的客户端 ID。 - 将
SECRET_TOKEN替换为您的 Secret 令牌。
- 将
如需了解详情,请参阅如何查找实例名称。
用于复制的 Cloud Composer 库
如需执行 Cortex Framework Data Foundation 提供的 DAG 中的 Python 脚本,您需要安装一些依赖项。对于 Airflow 版本 1.10,请按照为 Cloud Composer 1 安装 Python 依赖项文档的说明,按顺序安装以下软件包:
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
对于 Airflow 版本 2.x,请参阅为 Cloud Composer 2 安装 Python 依赖项文档,以安装 apache-airflow-providers-salesforce~=5.2.0。
使用以下命令安装每个必需的软件包:
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
替换以下内容:
- 将
ENVIRONMENT_NAME替换为分配的环境名称。 - 将
LOCATION替换为相应位置。 - 将
PACKAGE_NAME替换为所选的软件包名称。 EXTRAS_AND_VERSION,其中包含 extra 和版本的规范。
以下命令是必需软件包安装的示例:
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
启用 Secret Manager 作为后端
启用 Google Secret Manager 作为安全后端。此步骤会指导您将 Secret Manager 激活为 Cloud Composer 环境所用密码和 API 密钥等敏感信息的主要存储位置。这可以通过在专用服务中集中管理凭据来增强安全性。如需了解详情,请参阅 Secret Manager。
允许 Composer 服务账号访问 Secret
此步骤可确保与 Cloud Composer 关联的服务账号拥有访问 Secret Manager 中存储的 Secret 所需的权限。默认情况下,Cloud Composer 使用 Compute Engine 服务账号。所需权限为 Secret Manager Secret Accessor。
此权限允许服务账号检索和使用存储在 Secret Manager 中的 Secret。如需有关在 Secret Manager 中配置访问权限控制的全面指南,请参阅访问权限控制文档。
Airflow 中的 BigQuery 连接
请务必根据收集 Cloud Composer 设置创建连接 sfdc_cdc_bq。此连接可能由 Salesforce-to-BigQuery 模块用于与 BigQuery 建立通信。
后续步骤
- 如需详细了解其他数据源和工作负载,请参阅数据源和工作负载。
- 如需详细了解生产环境中的部署步骤,请参阅 Cortex Framework Data Foundation 部署前提条件。