Salesforce (SFDC)와의 통합
이 페이지에서는 Cortex Framework Data Foundation에서 Salesforce (SFDC) 운영 워크로드를 통합하는 단계를 설명합니다. Cortex 프레임워크는 Salesforce의 데이터를 Dataflow 파이프라인을 통해 BigQuery와 통합하고, Cloud Composer는 이러한 Dataflow 파이프라인을 예약하고 모니터링하여 데이터에서 유용한 정보를 얻습니다.
구성 파일
Cortex Framework Data Foundation 저장소의 config.json 파일은 Salesforce를 비롯한 모든 데이터 소스에서 데이터를 전송하는 데 필요한 설정을 구성합니다. 이 파일에는 운영 Salesforce 워크로드에 대한 다음 매개변수가 포함되어 있습니다.
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
다음 표에서는 각 SFDC 운영 매개변수의 값을 설명합니다.
| 매개변수 | 의미 | 기본값 | 설명 |
SFDC.deployCDC
|
CDC 배포 | true
|
Cloud Composer에서 DAG로 실행할 CDC 처리 스크립트를 생성합니다. Salesforce Sales Cloud의 다양한 수집 옵션에 관한 문서를 참고하세요. |
SFDC.createMappingViews
|
매핑 뷰 만들기 | true
|
Salesforce API에서 새 레코드를 가져오기 위해 제공된 DAG는 방문 시 레코드를 업데이트합니다. 이 값이 true로 설정되면 CDC 처리된 데이터 세트에서 뷰가 생성되어 원시 데이터 세트의 '최신 버전의 진실'이 있는 테이블이 노출됩니다. false이고 SFDC.deployCDC이 true인 경우 SystemModstamp를 기반으로 변경 데이터 캡처 (CDC) 처리를 사용하여 DAG가 생성됩니다. Salesforce의 CDC 처리에 관한 자세한 내용을 참고하세요.
|
SFDC.createPlaceholders
|
자리표시자 만들기 | true
|
다운스트림 보고 배포가 실패 없이 실행될 수 있도록 수집 프로세스에서 생성되지 않는 경우를 대비해 빈 자리표시자 테이블을 만듭니다. |
SFDC.datasets.raw
|
원시 시작 데이터 세트 | - | CDC 프로세스에서 사용되며, 복제 도구가 Salesforce의 데이터를 가져오는 위치입니다. 테스트 데이터를 사용하는 경우 빈 데이터 세트를 만듭니다. |
SFDC.datasets.cdc
|
CDC 처리된 데이터 세트 | - | 보고 뷰의 소스로 작동하고 레코드 처리 DAG의 타겟으로 작동하는 데이터 세트입니다. 테스트 데이터를 사용하는 경우 빈 데이터 세트를 만듭니다. |
SFDC.datasets.reporting
|
보고 데이터 세트 SFDC | "REPORTING_SFDC"
|
보고를 위해 최종 사용자가 액세스할 수 있는 데이터 세트의 이름입니다. 뷰와 사용자 대상 테이블이 배포됩니다. |
SFDC.currencies
|
통화 필터링 | [ "USD" ]
|
테스트 데이터를 사용하지 않는 경우 비즈니스와 관련된 단일 통화 (예: [ "USD" ]) 또는 여러 통화(예: [ "USD", "CAD" ])를 입력합니다.
이러한 값은 분석 모델의 SQL에서 자리표시자를 대체하는 데 사용됩니다(사용 가능한 경우).
|
데이터 모델
이 섹션에서는 엔티티 관계 다이어그램 (ERD)을 사용하여 Salesforce (SFDC) 데이터 모델을 설명합니다.
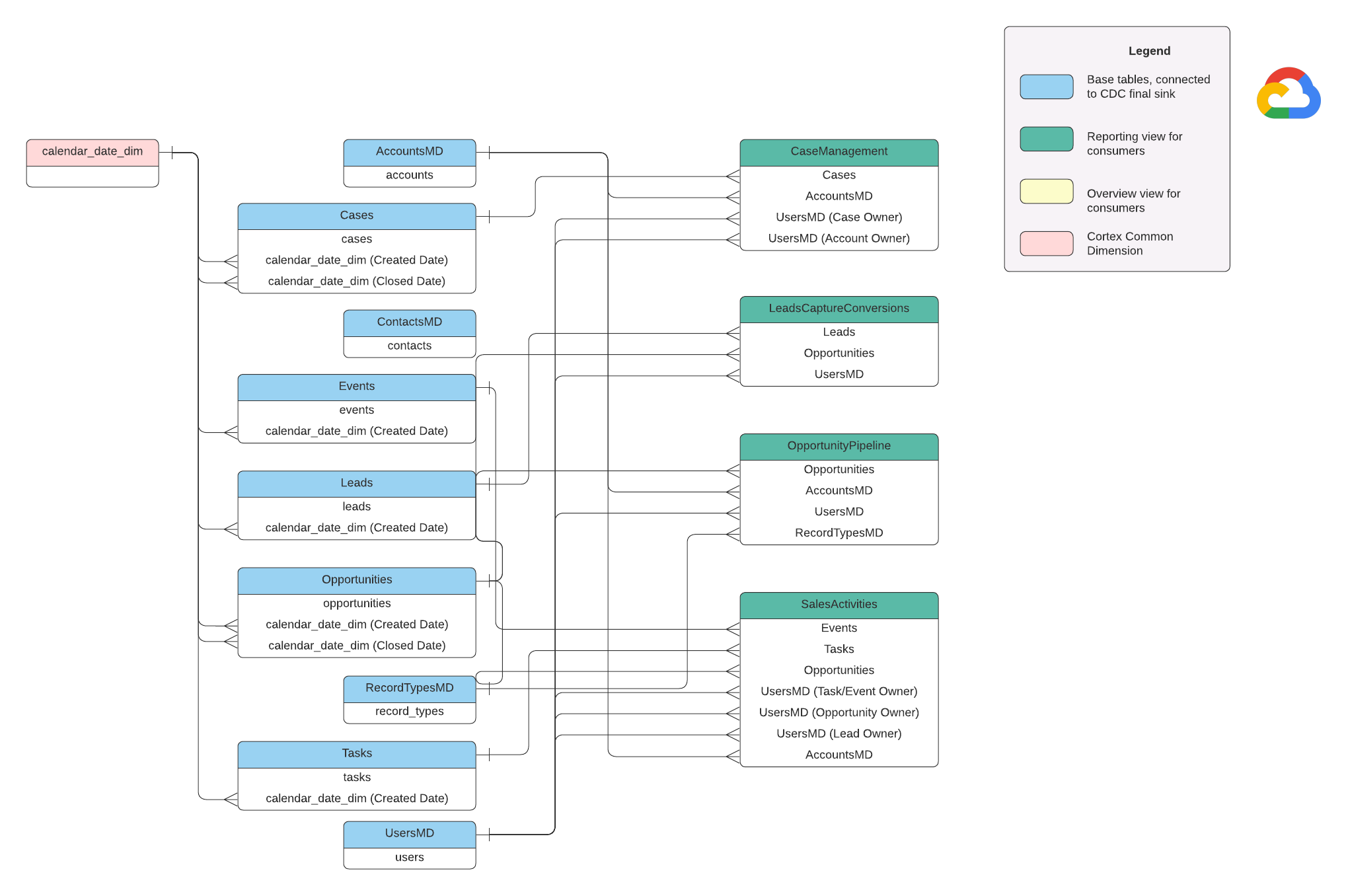
기본 뷰
ERD의 파란색 객체이며 일부 열 이름 별칭 외에는 변환이 없는 CDC 테이블의 뷰입니다. src/SFDC/src/reporting/ddls의 스크립트를 참고하세요.
보고 보기
ERD의 녹색 객체이며 보고 테이블에서 사용하는 관련 측정기준 속성이 포함되어 있습니다. src/SFDC/src/reporting/ddls의 스크립트를 참고하세요.
Salesforce 데이터 요구사항
이 섹션에서는 Cortex 프레임워크에서 사용할 수 있도록 Salesforce 데이터를 구조화하는 방법을 구체적으로 설명합니다.
- 표 구조:
- 이름 지정: 테이블 이름은
snake_case(밑줄로 구분된 소문자 단어)을 사용하며 복수형입니다. 예를 들면some_objects입니다. - 데이터 유형: 열은 Salesforce 내에 표시되는 것과 동일한 데이터 유형을 유지합니다.
- 가독성: 보고 레이어에서 명확성을 높이기 위해 일부 필드 이름이 약간 조정될 수 있습니다.
- 이름 지정: 테이블 이름은
- 빈 테이블 및 배포: 원시 데이터 세트에서 누락된 필수 테이블은 배포 프로세스 중에 빈 테이블로 자동 생성됩니다. 이렇게 하면 CDC 배포 단계를 원활하게 실행할 수 있습니다.
- CDC 요구사항:
Id및SystemModstamp필드는 CDC 스크립트가 데이터의 변경사항을 추적하는 데 중요합니다. 이러한 이름은 정확히 같거나 다를 수 있습니다. 제공된 원시 처리 스크립트는 API에서 이러한 필드를 자동으로 가져오고 타겟 복제 테이블을 업데이트합니다.Id: 각 레코드의 고유 식별자 역할을 합니다.SystemModstamp: 이 필드는 레코드가 마지막으로 수정된 시간을 나타내는 타임스탬프를 저장합니다.
- 원시 처리 스크립트:제공된 원시 처리 스크립트에는 추가 (CDC) 처리가 필요하지 않습니다. 이 동작은 배포 중에 기본적으로 설정됩니다.
통화 변환의 소스 테이블
Salesforce에서는 다음 두 가지 방법으로 통화를 관리할 수 있습니다.
- 기본: 모든 데이터가 단일 통화를 사용하는 기본값입니다.
- 고급: 환율에 따라 여러 통화 간에 변환합니다 (고급 통화 관리를 사용 설정해야 함).
고급 통화 관리를 사용하는 경우 Salesforce는 다음 두 가지 특수 테이블을 사용합니다.
- CurrencyTypes: 이 표에는 사용되는 다양한 통화 (예: USD, EUR 등)에 관한 정보가 저장됩니다.
- DatedConversionRates: 이 표에는 시간 경과에 따른 통화 간 환율이 포함됩니다.
고급 통화 관리를 사용하는 경우 Cortex 프레임워크는 이러한 테이블이 있어야 합니다. 고급 통화 관리를 사용하지 않는 경우 구성 파일(src/SFDC/config/ingestion_settings.yaml)에서 이러한 테이블과 관련된 항목을 삭제할 수 있습니다. 이 단계를 통해 존재하지 않는 테이블에서 데이터를 추출하려는 불필요한 시도를 방지할 수 있습니다.
BigQuery에 SFDC 데이터 로드
Cortex Framework는 Apache Airflow 및 Salesforce Bulk API 2.0에서 예약된 Python 스크립트를 기반으로 복제 솔루션을 제공합니다. 이러한 Python 스크립트는 원하는 도구에서 조정하고 예약할 수 있습니다. 자세한 내용은 SFDC 추출 모듈을 참고하세요.
또한 Cortex Framework는 데이터 소스와 데이터 관리 방식에 따라 데이터를 통합하는 세 가지 방법을 제공합니다.
- API 호출: 이 옵션은 API를 통해 직접 액세스할 수 있는 데이터에 사용됩니다. Cortex Framework는 API를 호출하고 데이터를 가져와 BigQuery 내의 'Raw' 데이터 세트에 저장할 수 있습니다. 데이터 세트에 기존 레코드가 있는 경우 Cortex Framework에서 새 데이터로 업데이트할 수 있습니다.
- 구조 매핑 뷰: 다른 도구를 통해 이미 BigQuery에 데이터를 로드했지만 데이터 구조가 Cortex 프레임워크에 필요한 구조와 일치하지 않는 경우에 유용합니다. Cortex Framework는 '뷰' (가상 테이블과 유사)를 사용하여 기존 데이터 구조를 Cortex Framework의 보고 기능에서 예상하는 형식으로 변환합니다.
CDC (변경 데이터 캡처) 처리 스크립트: 이 옵션은 지속적으로 변경되는 데이터를 위해 특별히 설계되었습니다. CDC 스크립트는 이러한 변경사항을 추적하고 BigQuery의 데이터를 그에 따라 업데이트합니다. 이러한 스크립트는 데이터의 두 가지 특수 필드를 사용합니다.
Id: 각 레코드의 고유 식별자입니다.SystemModstamp: 레코드가 변경된 시간을 나타내는 타임스탬프입니다.
데이터에 이러한 정확한 이름이 없는 경우 스크립트를 조정하여 다른 이름으로 인식할 수 있습니다. 이 과정에서 데이터 스키마에 맞춤 필드를 추가할 수도 있습니다. 예를 들어 계정 객체의 데이터가 있는 소스 테이블에는 원래
Id및SystemModstamp필드가 있어야 합니다. 이러한 필드의 이름이 다른 경우src/SFDC/src/table_schema/accounts.csv파일은AccountId에 매핑된Id필드의 이름과SystemModstamp에 매핑된 시스템 수정 타임스탬프 필드로 업데이트해야 합니다. 자세한 내용은 SystemModStamp 문서를 참고하세요.
다른 도구를 통해 데이터를 이미 로드한 경우 (그리고 데이터가 지속적으로 업데이트되는 경우) Cortex에서 해당 데이터를 계속 사용할 수 있습니다. CDC 스크립트에는 기존 데이터 구조를 Cortex Framework에 필요한 형식으로 변환할 수 있는 매핑 파일이 함께 제공됩니다. 이 과정에서 데이터에 맞춤 필드를 추가할 수도 있습니다.
API 통합 및 CDC 구성
Salesforce 데이터를 BigQuery로 가져오려면 다음 방법을 사용하면 됩니다.
- API 호출용 Cortex 스크립트: Salesforce 또는 원하는 데이터 복제 도구용 복제 스크립트를 제공합니다.핵심은 가져오는 데이터가 Salesforce API에서 가져온 것처럼 보여야 한다는 것입니다.
- 복제 도구 및 항상 추가 : 복제 도구를 사용하는 경우 이 방법은 새 데이터 레코드(_appendalways_pattern)를 추가하거나 기존 레코드를 업데이트할 수 있는 도구를 위한 것입니다.
- 복제 도구 및 새 레코드 추가: 도구에서 레코드를 업데이트하지 않고 변경사항을 타겟 (원시) 테이블에 새 레코드로 복제하는 경우 Cortex Data Foundation에서 CDC 처리 스크립트를 만드는 옵션을 제공합니다. 자세한 내용은 CDC 프로세스를 참고하세요.

데이터가 Cortex Framework에서 예상하는 것과 일치하는지 확인하려면 매핑 구성을 조정하여 복제 도구 또는 기존 스키마를 매핑하면 됩니다. 이렇게 하면 Cortex Framework Data Foundation에서 예상하는 구조와 호환되는 매핑 뷰가 생성됩니다.
ingestion_settings.yaml 파일을 사용하여 Salesforce API를 호출하고 데이터를 원시 데이터 세트 (salesforce_to_raw_tables 섹션)로 복제하는 스크립트 생성과 원시 데이터 세트 및 CDC 처리 데이터 세트 (raw_to_cdc_tables 섹션)로 수신되는 변경사항을 처리하는 스크립트 생성을 구성합니다.
기본적으로 API에서 읽어오는 데 제공되는 스크립트는 변경사항을 원시 데이터 세트로 업데이트하므로 CDC 처리 스크립트가 필요하지 않으며, 대신 소스 스키마를 예상 스키마에 맞추기 위한 매핑 뷰가 생성됩니다.
config.json의 SFDC.createMappingViews=true인 경우 CDC 처리 스크립트 생성은 실행되지 않습니다 (기본 동작). CDC 스크립트가 필요한 경우 SFDC.createMappingViews=false를 설정합니다. 이 두 번째 단계에서는 Cortex Framework Data Foundation에서 요구하는 대로 소스 스키마와 필수 스키마 간의 매핑도 허용합니다.
다음 setting.yaml 구성 파일 예시에서는 복제 도구가 option 3에 표시된 대로 복제된 데이터 세트에 직접 데이터를 업데이트할 때 매핑 뷰가 생성되는 방법을 보여줍니다 (즉, CDC가 필요하지 않고 테이블 및 필드 이름의 재매핑만 필요함). CDC가 필요하지 않으므로 config.json 파일의 SFDC.createMappingViews 매개변수가 true로 유지되는 한 이 옵션이 실행됩니다.
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
이 예시에서 섹션에서 기본 테이블 또는 모든 테이블의 구성을 삭제하면 salesforce_to_raw_tables에 표시된 대로 해당 기본 테이블 또는 전체 섹션의 DAG 생성이 건너뛰어집니다. 이 시나리오에서는 CDC 처리 스크립트를 생성할 필요가 없으므로 deployCDC : False 매개변수를 설정하는 것이 동일한 효과를 갖습니다.
데이터 매핑
수신 데이터 필드를 Cortex Data Foundation에서 예상하는 형식으로 매핑해야 합니다. 예를 들어 소스 데이터 시스템의 unicornId라는 필드의 이름을 바꾸고 Cortex Data Foundation 내에서 AccountId (문자열 데이터 유형)로 인식해야 합니다.
- 소스 필드:
unicornId(소스 시스템에서 사용되는 이름) - Cortex 필드:
AccountId(Cortex에서 예상하는 이름) - 데이터 유형:
String(Cortex에서 예상하는 데이터 유형)
다형성 필드 매핑
Cortex Framework 데이터 파운데이션은 이름이 다를 수 있지만 구조는 일관되게 유지되는 다형성 필드의 매핑을 지원합니다. 다형 필드 유형 이름(예: Who.Type)은 해당 매핑 CSV 파일(src/SFDC/src/table_schema/tasks.csv)에 [Field Name]_Type 항목을 추가하여 복제할 수 있습니다. 예를 들어 Task 객체의 Who.Type 필드를 복제해야 하는 경우 Who_Type,Who_Type,STRING 행을 추가합니다. 이렇게 하면 자체에 매핑되고 (이름이 동일하게 유지됨) 문자열 데이터 유형이 있는 Who.Type라는 새 필드가 정의됩니다.
DAG 템플릿 수정
Airflow 또는 Cloud Composer 인스턴스에 따라 CDC용 DAG 템플릿 또는 원시 데이터 처리용 템플릿을 조정해야 할 수 있습니다. 자세한 내용은 Cloud Composer 설정 수집을 참고하세요.
API 호출에서 CDC 또는 원시 데이터 생성이 필요하지 않은 경우 deployCDC=false를 설정합니다. 또는 ingestion_settings.yaml에서 섹션의 콘텐츠를 삭제할 수 있습니다. 데이터 구조가 Cortex Framework 데이터 기반에서 예상하는 구조와 일치하는 것으로 알려진 경우 SFDC.createMappingViews=false를 설정하여 매핑 뷰 생성을 건너뛸 수 있습니다.
추출 모듈 구성
이 섹션에서는 Data Foundation에서 제공하는 Salesforce to BigQuery 추출 모듈을 사용하는 단계를 설명합니다. 요구사항과 흐름은 시스템과 기존 구성에 따라 다를 수 있습니다. 다른 사용 가능한 도구를 대신 사용할 수도 있습니다.
사용자 인증 정보 및 연결된 앱 설정
관리자로 Salesforce 인스턴스에 로그인하여 다음을 완료합니다.
- 다음 요구사항을 충족하는 Salesforce 프로필을 만들거나 식별합니다.
Permission for Apex REST Services and API Enabled은 시스템 권한에 따라 부여됩니다.- 복제하려는 모든 객체에 대해
View All권한이 부여됩니다. 예를 들어 계정, 케이스가 있습니다. 보안 관리자에게 제한사항이나 문제가 있는지 확인하세요. - Lightning Experience의 Salesforce Anywhere, 모바일의 Salesforce Anywhere, Lightning Experience 사용자, Lightning 로그인 사용자 등 사용자 인터페이스 로그인과 관련된 권한이 부여되지 않았습니다. 보안 관리자에게 제한사항이나 문제가 있는지 확인하세요.
- Salesforce에서 기존 사용자를 식별하거나 사용자를 만듭니다. 사용자의 사용자 이름, 비밀번호, 보안 토큰을 알아야 합니다. 다음 사항을 고려하세요.
- 이 사용자는 이 복제를 실행하는 데 전용으로 사용되는 것이 좋습니다.
- 사용자는 1단계에서 만든 프로필 또는 식별한 프로필에 할당되어야 합니다.
- 여기에서 사용자 이름을 확인하고 비밀번호를 재설정할 수 있습니다.
- 보안 토큰이 없고 다른 프로세스에서 사용하지 않는 경우 보안 토큰을 재설정할 수 있습니다.
- 연결된 앱을 만듭니다. 프로필, Salesforce API, 표준 사용자 인증 정보 및 보안 토큰을 사용하여 외부에서 Salesforce에 연결하는 유일한 통신 채널입니다.
- 안내에 따라 API 통합을 위한 OAuth 설정을 사용 설정합니다.
- API (OAuth 설정 사용 설정) 섹션에서
Require Secret for Web Server Flow및Require Secretfor Refresh Token Flow이 사용 설정되어 있는지 확인합니다. - 컨슈머 키 (나중에 클라이언트 ID로 사용됨)를 가져오는 방법은 문서를 참고하세요. 보안 관리자에게 문제나 제한사항이 있는지 확인하세요.
- 생성된 프로필에 연결된 앱을 할당합니다.
- Salesforce 홈 화면의 오른쪽 상단에서 설정을 선택합니다.
- 빠른 찾기 상자에
profile를 입력한 다음 프로필을 선택합니다. 1단계에서 만든 프로필을 검색합니다. - 프로필을 엽니다.
- 할당된 연결된 앱 링크를 클릭합니다.
- 수정을 클릭합니다.
- 새로 만든 Connected App을 추가합니다.
- 저장 버튼을 클릭합니다.
Secret Manager 설정
연결 세부정보를 저장하도록 Secret Manager를 구성합니다. Salesforce-to-BigQuery 모듈은 Secret Manager를 사용하여 Salesforce 및 BigQuery에 연결하는 데 필요한 사용자 인증 정보를 안전하게 저장합니다. 이 접근 방식을 사용하면 비밀번호와 같은 민감한 정보가 코드나 구성 파일에 직접 노출되지 않아 보안이 강화됩니다.
다음 사양으로 보안 비밀을 만듭니다. 자세한 내용은 보안 비밀 만들기를 참고하세요.
- 보안 비밀 이름:
airflow-connections-salesforce-conn 보안 비밀 값:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`다음을 바꿉니다.
USERNAME을 사용자 이름으로 바꿉니다.PASSWORD을 비밀번호로 바꿉니다.INSTANCE_NAME을 인스턴스 이름으로 바꿉니다.CLIENT_ID를 클라이언트 ID로 바꿉니다.SECRET_TOKEN을 보안 비밀 토큰으로 바꿉니다.
자세한 내용은 인스턴스 이름을 찾는 방법을 참고하세요.
복제를 위한 Cloud Composer 라이브러리
Cortex Framework Data Foundation에서 제공하는 DAG에서 Python 스크립트를 실행하려면 일부 종속 항목을 설치해야 합니다. Airflow 버전 1.10의 경우 Cloud Composer 1용 Python 종속 항목 설치 문서에 따라 다음 패키지를 순서대로 설치하세요.
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
Airflow 버전 2.x의 경우 Cloud Composer 2용 Python 종속 항목 설치 문서를 참고하여 apache-airflow-providers-salesforce~=5.2.0을 설치하세요.
다음 명령어를 사용하여 필요한 각 패키지를 설치합니다.
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
다음을 바꿉니다.
ENVIRONMENT_NAME을 할당된 환경 이름으로 바꿉니다.LOCATION을 위치로 바꿉니다.PACKAGE_NAME을 선택한 패키지 이름으로 바꿉니다.EXTRAS_AND_VERSION: 추가 항목 및 버전의 사양
다음 명령어는 필수 패키지 설치의 예시입니다.
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
Secret Manager를 백엔드로 사용 설정
Google Secret Manager를 보안 백엔드로 사용 설정합니다. 이 단계에서는 Cloud Composer 환경에서 사용하는 비밀번호 및 API 키와 같은 민감한 정보의 기본 저장 위치로 Secret Manager를 활성화하도록 안내합니다. 이렇게 하면 전용 서비스에서 사용자 인증 정보를 중앙 집중화하고 관리하여 보안이 강화됩니다. 자세한 내용은 Secret Manager를 참고하세요.
Composer 서비스 계정이 보안 비밀에 액세스하도록 허용
이 단계를 통해 Cloud Composer와 연결된 서비스 계정에 Secret Manager 내에 저장된 보안 비밀에 액세스하는 데 필요한 권한이 있는지 확인할 수 있습니다.
기본적으로 Cloud Composer는 Compute Engine 서비스 계정을 사용합니다.
필요한 권한은 Secret Manager Secret Accessor입니다.
이 권한을 사용하면 서비스 계정이 Secret Manager에 저장된 보안 비밀을 가져와 사용할 수 있습니다.Secret Manager에서 액세스 제어를 구성하는 방법에 관한 자세한 가이드는 액세스 제어 문서를 참고하세요.
Airflow의 BigQuery 연결
Cloud Composer 설정 수집에 따라 연결 sfdc_cdc_bq을 만들어야 합니다. 이 연결은 Salesforce-to-BigQuery 모듈에서 BigQuery와의 통신을 설정하는 데 사용될 수 있습니다.
다음 단계
- 기타 데이터 소스 및 워크로드에 대한 자세한 내용은 데이터 소스 및 워크로드를 참고하세요.
- 프로덕션 환경에서의 배포 단계에 관한 자세한 내용은 Cortex Framework 데이터 기반 배포 필수사항을 참고하세요.