Integración con Salesforce (SFDC)
En esta página, se describen los pasos de integración para la carga de trabajo operativa de Salesforce (SFDC) en la base de datos de Cortex Framework. Cortex Framework integra los datos de Salesforce con las canalizaciones de Dataflow en BigQuery, mientras que Cloud Composer programa y supervisa estas canalizaciones de Dataflow para obtener estadísticas a partir de tus datos.
Archivo de configuración
El archivo config.json del repositorio de Cortex Framework Data Foundation configura los parámetros necesarios para transferir datos desde cualquier fuente de datos, incluido Salesforce. Este archivo contiene los siguientes parámetros para las cargas de trabajo operativas de Salesforce:
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
En la siguiente tabla, se describe el valor de cada parámetro operativo de SFDC:
| Parámetro | Significado | Valor predeterminado | Descripción |
SFDC.deployCDC
|
Implementa la CDC | true
|
Genera secuencias de comandos de procesamiento de CDC para ejecutarlas como DAGs en Cloud Composer. Consulta la documentación sobre las diferentes opciones de transferencia de datos para Salesforce Sales Cloud. |
SFDC.createMappingViews
|
Crea vistas de asignación | true
|
Los DAGs proporcionados para recuperar registros nuevos de las APIs de Salesforce actualizan los registros en la página de destino. Si este valor se establece en verdadero, se generan vistas en el conjunto de datos procesado por CDC para exponer tablas con la "versión más reciente de la verdad" del conjunto de datos sin procesar. Si es falso y SFDC.deployCDC es true, se generan DAG con procesamiento de captura de datos modificados (CDC) basado en SystemModstamp. Consulta los detalles sobre el procesamiento de CDC para Salesforce.
|
SFDC.createPlaceholders
|
Cómo crear marcadores de posición | true
|
Crea tablas de marcadores de posición vacías en caso de que el proceso de transferencia no las genere para permitir que la implementación de informes posteriores se ejecute sin errores. |
SFDC.datasets.raw
|
Conjunto de datos de la página de destino sin procesar | - | El proceso de CDC usa esta ubicación, donde la herramienta de replicación coloca los datos de Salesforce. Si usas datos de prueba, crea un conjunto de datos vacío. |
SFDC.datasets.cdc
|
Conjunto de datos procesado de CDC | - | Es el conjunto de datos que funciona como fuente para las vistas de informes y como destino para los DAG de registros procesados. Si usas datos de prueba, crea un conjunto de datos vacío. |
SFDC.datasets.reporting
|
Conjunto de datos de informes de SFDC | "REPORTING_SFDC"
|
Nombre del conjunto de datos al que pueden acceder los usuarios finales para generar informes, en el que se implementan las vistas y las tablas orientadas al usuario. |
SFDC.currencies
|
Filtrar monedas | [ "USD" ]
|
Si no usas datos de prueba, ingresa una sola moneda (por ejemplo, [ "USD" ]) o varias (por ejemplo,[ "USD", "CAD" ]) según corresponda a tu empresa.
Estos valores se usan para reemplazar los marcadores de posición en SQL en los modelos de Analytics cuando están disponibles.
|
Modelo de datos
En esta sección, se describe el modelo de datos de Salesforce (SFDC) con el diagrama de relación entre entidades (ERD).
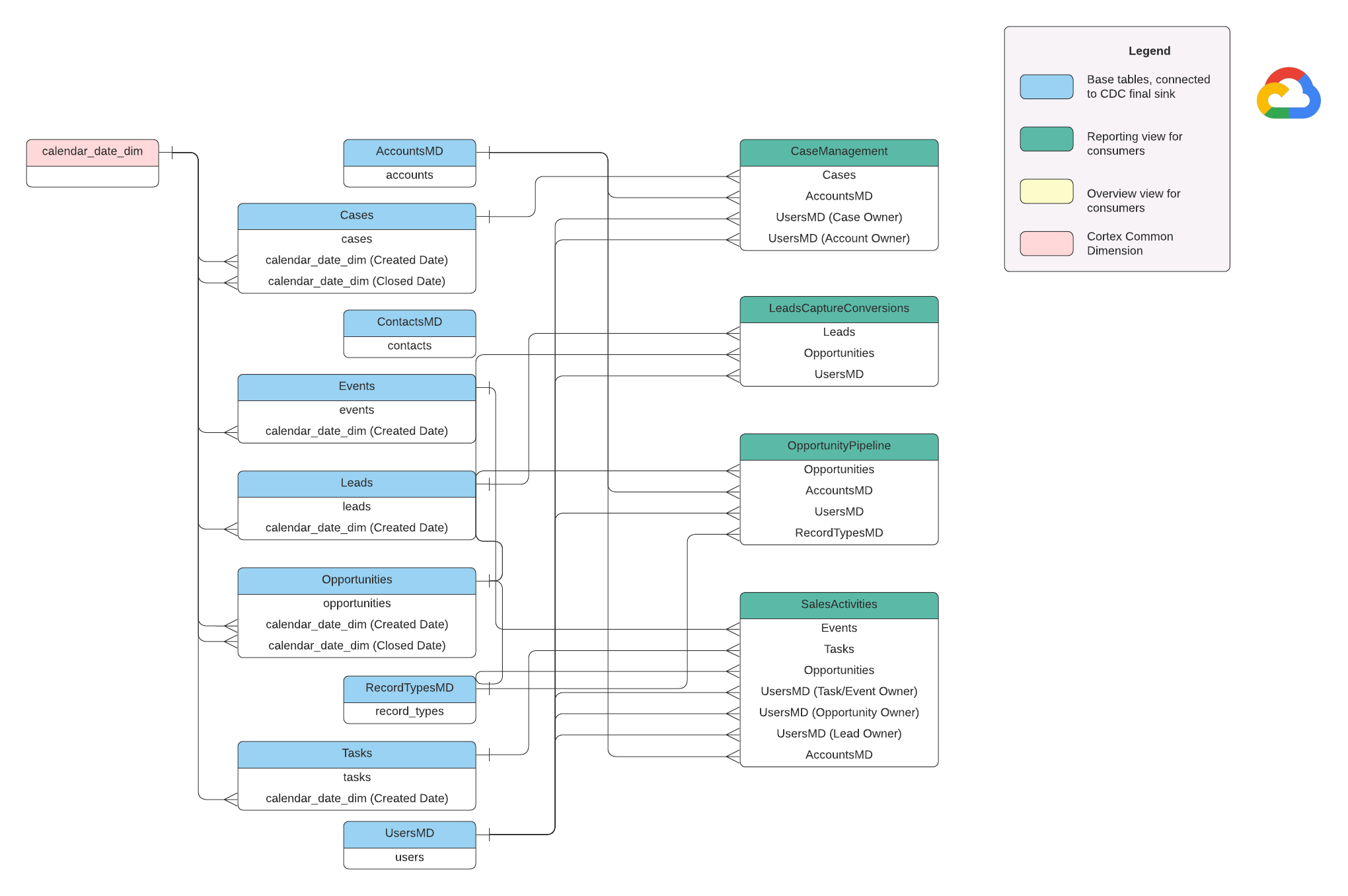
Vistas base
Estos son los objetos azules en el DER y son vistas de las tablas de CDC sin transformaciones, excepto algunos alias de nombres de columnas. Consulta las secuencias de comandos en src/SFDC/src/reporting/ddls.
Vistas de informes
Estos son los objetos verdes del DER y contienen los atributos dimensionales pertinentes que utilizan las tablas de informes. Consulta las secuencias de comandos en src/SFDC/src/reporting/ddls.
Requisitos de los datos de Salesforce
En esta sección, se describen los detalles específicos de cómo deben estructurarse tus datos de Salesforce para usarlos con Cortex Framework.
- Estructura de la tabla:
- Nombres: Los nombres de las tablas usan
snake_case(palabras en minúscula separadas por guiones bajos) y son en plural. Por ejemplo,some_objects. - Tipos de datos: Las columnas conservan los mismos tipos de datos que se representan en Salesforce.
- Legibilidad: Es posible que algunos nombres de campos se ajusten ligeramente para mejorar la claridad en la capa de informes.
- Nombres: Los nombres de las tablas usan
- Tablas vacías y la Deployment: Las tablas obligatorias que falten en el conjunto de datos sin procesar se crearán automáticamente como tablas vacías durante el proceso de implementación. Esto garantiza la ejecución sin problemas del paso de implementación del CDC.
- Requisitos de CDC: Los campos
IdySystemModstampson fundamentales para que las secuencias de comandos de CDC realicen un seguimiento de los cambios en tus datos. Pueden tener estos nombres exactos o diferentes. Las secuencias de comandos de procesamiento sin procesar proporcionadas recuperan estos campos automáticamente de las APIs y actualizan la tabla de replicación de destino.Id: Actúa como un identificador único para cada registro.SystemModstamp: Este campo almacena una marca de tiempo que indica la última vez que se modificó un registro.
- Secuencias de comandos de procesamiento sin procesar:Las secuencias de comandos de procesamiento sin procesar proporcionadas no requieren procesamiento adicional (CDC). Este comportamiento se establece durante la implementación de forma predeterminada.
Tablas de origen para la conversión de moneda
Salesforce te permite administrar las monedas de dos maneras:
- Básico: Este es el valor predeterminado, en el que todos los datos usan una sola moneda.
- Avanzado: Realiza conversiones entre varias monedas según los tipos de cambio (requiere habilitar la Administración avanzada de monedas).
Si usas la Administración avanzada de múltiples monedas, Salesforce utiliza dos tablas especiales:
- CurrencyTypes: En esta tabla, se almacena información sobre las diferentes monedas que usas (por ejemplo, USD, EUR, etcétera).
- DatedConversionRates: Esta tabla contiene los tipos de cambio entre monedas a lo largo del tiempo.
Cortex Framework espera que estas tablas estén presentes si usas la administración avanzada de monedas. Si no utilizas la administración avanzada de monedas, puedes quitar las entradas relacionadas con estas tablas de un archivo de configuración (src/SFDC/config/ingestion_settings.yaml). Este paso evita intentos innecesarios de extraer datos de tablas inexistentes.
Carga de datos de SFDC en BigQuery
Cortex Framework proporciona una solución de replicación basada en secuencias de comandos de Python programadas en Apache Airflow y la API masiva de Salesforce 2.0. Estas secuencias de comandos de Python se pueden adaptar y programar en la herramienta que elijas. Para obtener más información, consulta Módulo de extracción de SFDC.
Cortex Framework también ofrece tres métodos diferentes para integrar tus datos, según de dónde provengan y cómo se administren:
- Llamadas a la API: Esta opción es para los datos a los que se puede acceder directamente a través de una API. Cortex Framework puede llamar a la API, tomar los datos y almacenarlos en un conjunto de datos "sin procesar" en BigQuery. Si hay registros existentes en el conjunto de datos, Cortex Framework puede actualizarlos con los datos nuevos.
- Vistas de asignación de estructura: Este método es útil si ya cargaste tus datos en BigQuery a través de otra herramienta, pero la estructura de datos no coincide con lo que necesita Cortex Framework. Cortex Framework usa "vistas" (como tablas virtuales) para traducir la estructura de datos existente al formato que esperan las funciones de informes de Cortex Framework.
Scripts de procesamiento de CDC (captura de datos modificados): Esta opción está diseñada específicamente para los datos que cambian constantemente. Los secuencias de comandos de CDC hacen un seguimiento de estos cambios y actualizan los datos en BigQuery según corresponda. Estas secuencias de comandos se basan en dos campos especiales de tus datos:
Id: Es el identificador único de cada registro.SystemModstamp: Es una marca de tiempo que indica cuándo se cambió un registro.
Si tus datos no tienen estos nombres exactos, las secuencias de comandos se pueden ajustar para reconocerlos con nombres diferentes. También puedes agregar campos personalizados a tu esquema de datos durante este proceso. Por ejemplo, la tabla de origen con datos del objeto Account debe tener los campos originales
IdySystemModstamp. Si estos campos tienen nombres diferentes, el archivosrc/SFDC/src/table_schema/accounts.csvdebe actualizarse con el nombre del campoIdasignado aAccountIdy cualquier campo de marca de tiempo de modificación del sistema asignado aSystemModstamp. Para obtener más información, consulta la documentación de SystemModStamp.
Si ya cargaste datos a través de otra herramienta (y se actualizan constantemente), Cortex aún puede usarlos. Las secuencias de comandos de CDC incluyen archivos de asignación que pueden traducir tu estructura de datos existente al formato que necesita Cortex Framework. Incluso puedes agregar campos personalizados a tus datos durante este proceso.
Configura la integración de la API y el CDC
Para transferir tus datos de Salesforce a BigQuery, puedes usar los siguientes métodos:
- Secuencias de comandos de Cortex para llamadas a la API: Proporciona secuencias de comandos de replicación para Salesforce o una herramienta de replicación de datos de tu elección.La clave es que los datos que importes deben verse igual que si provinieran de las APIs de Salesforce.
- Herramienta de replicación y agregar siempre : Si usas una herramienta de replicación, esta opción es para una herramienta que puede agregar registros de datos nuevos (_appendalways_pattern) o actualizar registros existentes.
- Herramienta de replicación y adición de registros nuevos: Si la herramienta no actualiza los registros y replica los cambios como registros nuevos en una tabla de destino (sin procesar), Cortex Data Foundation proporciona la opción de crear secuencias de comandos de procesamiento de CDC. Para obtener más información, consulta el proceso de los CDC.

Para asegurarte de que tus datos coincidan con lo que espera Cortex Framework, puedes ajustar la configuración de asignación para asignar tu herramienta de replicación o esquemas existentes. Esto genera vistas de asignación compatibles con la estructura que espera Cortex Framework Data Foundation.
Usa el archivo ingestion_settings.yaml para configurar la generación de secuencias de comandos para llamar a las APIs de Salesforce y replicar los datos en el conjunto de datos sin procesar (sección salesforce_to_raw_tables) y la generación de secuencias de comandos para procesar los cambios entrantes en el conjunto de datos sin procesar y en el conjunto de datos procesados de CDC (sección raw_to_cdc_tables).
De forma predeterminada, las secuencias de comandos proporcionadas para leer desde las APIs actualizan los cambios en el conjunto de datos sin procesar, por lo que no se requieren secuencias de comandos de procesamiento de CDC. En su lugar, se crean vistas de asignación para alinear el esquema de origen con el esquema esperado.
La generación de secuencias de comandos de procesamiento de CDC no se ejecuta si SFDC.createMappingViews=true en config.json (comportamiento predeterminado). Si se requieren secuencias de comandos de CDC, establece SFDC.createMappingViews=false. Este segundo paso también permite la asignación entre los esquemas de origen y los esquemas requeridos por la base de datos de Cortex Framework.
En el siguiente ejemplo de un archivo de configuración setting.yaml, se ilustra la generación de vistas de asignación cuando una herramienta de replicación actualiza los datos directamente en el conjunto de datos replicado, como se ilustra en option 3 (es decir, no se requiere CDC, solo se deben reasignar los nombres de las tablas y los campos). Como no se requiere ningún CDC, esta opción se ejecuta siempre y cuando el parámetro SFDC.createMappingViews en el archivo config.json permanezca como true.
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
En este ejemplo, quitar la configuración de una tabla base o de todas ellas de las secciones omite la generación de DAG de esa tabla base o de toda la sección, como se ilustra para salesforce_to_raw_tables. En este caso, establecer el parámetro deployCDC : False tiene el mismo efecto, ya que no es necesario generar secuencias de comandos de procesamiento de CDC.
Asignación de datos
Debes asignar los campos de datos entrantes al formato que espera Cortex Data Foundation. Por ejemplo, un campo llamado unicornId de tu sistema de datos fuente se debe cambiar de nombre y reconocer como AccountId (con un tipo de datos de cadena) dentro de Cortex Data Foundation:
- Campo de origen:
unicornId(nombre que se usa en el sistema de origen) - Cortex Field:
AccountId(nombre esperado por Cortex) - Tipo de datos:
String(tipo de datos que espera Cortex)
Cómo asignar campos polimórficos
La base de datos de Cortex Framework admite la asignación de campos polimórficos, que son campos cuyo nombre puede variar, pero su estructura sigue siendo coherente. Los nombres de los tipos de campos polimórficos (por ejemplo, Who.Type) se pueden replicar agregando un elemento [Field Name]_Type en los archivos CSV de asignación respectivos: src/SFDC/src/table_schema/tasks.csv. Por ejemplo, si necesitas que se replique el campo Who.Type del objeto Task, agrega la línea Who_Type,Who_Type,STRING. Esto define un nuevo campo llamado Who.Type que se asigna a sí mismo (conserva el mismo nombre) y tiene un tipo de datos de cadena.
Cómo modificar plantillas de DAG
Es posible que debas ajustar las plantillas de DAG para CDC o para el procesamiento de datos sin procesar según lo requiera tu instancia de Airflow o Cloud Composer. Para obtener más información, consulta Cómo recopilar la configuración de Cloud Composer.
Si no necesitas CDC ni generación de datos sin procesar a partir de llamadas a la API, establece deployCDC=false. Como alternativa, puedes quitar el contenido de las secciones en ingestion_settings.yaml. Si se sabe que las estructuras de datos son coherentes con las que espera Cortex Framework Data Foundation, puedes omitir la generación de la configuración de vistas de asignación SFDC.createMappingViews=false.
Cómo configurar el módulo de extracción
En esta sección, se presentan los pasos para usar el módulo de extracción de Salesforce a BigQuery que proporciona Data Foundation. Tus requisitos y flujo pueden variar según tu sistema y la configuración existente. También puedes usar otras herramientas disponibles.
Configura las credenciales y la app conectada
Accede como administrador a tu instancia de Salesforce para completar los siguientes pasos:
- Crea o identifica un perfil en Salesforce que cumpla con los siguientes requisitos:
Permission for Apex REST Services and API Enabledse otorga en Permisos del sistema.- Se otorga permiso
View Allpara todos los objetos que desees replicar. Por ejemplo, Cuenta y Casos. Comprueba si hay restricciones o problemas con tu administrador de seguridad. - No se otorgaron permisos relacionados con el acceso a la interfaz de usuario, como Salesforce Anywhere en Lightning Experience, Salesforce Anywhere en dispositivos móviles, usuario de Lightning Experience y usuario de acceso de Lightning. Comprueba si hay restricciones o problemas con tu administrador de seguridad.
- Crea o usa la opción para identificar a un usuario existente en Salesforce. Debes conocer el nombre de usuario, la contraseña y el token de seguridad del usuario. Ten en cuenta lo siguiente:
- Lo ideal sería que fuera un usuario dedicado a ejecutar esta replicación.
- El usuario debe estar asignado al perfil que creaste o identificaste en el paso 1.
- Aquí puedes ver el nombre de usuario y restablecer la contraseña.
- Puedes restablecer el token de seguridad si no lo tienes y no lo usa otro proceso.
- Crea una aplicación conectada. Es el único canal de comunicación para establecer la conexión a Salesforce desde el mundo externo con la ayuda del perfil, la API de Salesforce, las credenciales de usuario estándar y su token de seguridad.
- Sigue las instrucciones para habilitar la configuración de OAuth para la integración de la API.
- Asegúrate de que
Require Secret for Web Server FlowyRequire Secretfor Refresh Token Flowestén habilitados en la sección API (Habilitar configuración de OAuth). - Consulta la documentación para obtener tu clave del consumidor (que se usará más adelante como tu ID de cliente). Consulta a tu administrador de seguridad sobre problemas o restricciones.
- Asigna tu app conectada al perfil creado.
- Selecciona Configuración en la parte superior derecha de la pantalla principal de Salesforce.
- En el cuadro Búsqueda rápida, ingresa
profiley, luego, selecciona Perfil. Busca el perfil que creaste en el paso 1. - Abre el perfil.
- Haz clic en el vínculo Assigned Connected Apps.
- Haz clic en Editar.
- Agrega la app conectada recién creada.
- Haz clic en el botón Guardar.
Configura Secret Manager
Configura Secret Manager para almacenar los detalles de la conexión. El módulo de Salesforce a BigQuery se basa en Secret Manager para almacenar de forma segura las credenciales que necesita para conectarse a Salesforce y BigQuery. Este enfoque evita exponer información sensible, como contraseñas, directamente en el código o los archivos de configuración, lo que mejora la seguridad.
Crea un secreto con las siguientes especificaciones. Para obtener instrucciones más detalladas, consulta Crea un secreto.
- Nombre del secreto:
airflow-connections-salesforce-conn Valor secreto:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`Reemplaza lo siguiente:
USERNAMEpor tu nombre de usuarioPASSWORDcon tu contraseña.INSTANCE_NAMEcon el nombre de la instanciaCLIENT_IDpor tu ID de cliente.SECRET_TOKENcon tu token secreto.
Para obtener más información, consulta cómo encontrar el nombre de tu instancia.
Bibliotecas de Cloud Composer para la replicación
Para ejecutar las secuencias de comandos de Python en los DAGs proporcionados por Cortex Framework Data Foundation, debes instalar algunas dependencias. Para la versión 1.10 de Airflow, sigue la documentación de instalación de dependencias de Python para Cloud Composer 1 para instalar los siguientes paquetes, en orden:
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
Para la versión 2.x de Airflow, consulta la documentación sobre cómo instalar dependencias de Python para Cloud Composer 2 para instalar apache-airflow-providers-salesforce~=5.2.0.
Usa el siguiente comando para instalar cada paquete requerido:
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
Reemplaza lo siguiente:
ENVIRONMENT_NAMEpor el nombre del entorno asignado.LOCATIONcon la ubicaciónPACKAGE_NAMEpor el nombre del paquete elegido.EXTRAS_AND_VERSIONcon las especificaciones de los extras y la versión.
El siguiente comando es un ejemplo de la instalación de un paquete obligatorio:
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
Habilita Secret Manager como backend
Habilita Google Secret Manager como backend de seguridad. En este paso, se te indica que actives Secret Manager como la ubicación de almacenamiento principal para la información sensible, como contraseñas y claves de API, que usa tu entorno de Cloud Composer. Esto mejora la seguridad, ya que centraliza y administra las credenciales en un servicio dedicado. Para obtener más información, consulta Secret Manager.
Permite que la cuenta de servicio de Composer acceda a los secretos
Este paso garantiza que la cuenta de servicio asociada a Cloud Composer tenga los permisos necesarios para acceder a los secretos almacenados en Secret Manager.
De forma predeterminada, Cloud Composer usa la cuenta de servicio de Compute Engine.
El permiso requerido es Secret Manager Secret Accessor.
Este permiso permite que la cuenta de servicio recupere y use los secretos almacenados en Secret Manager.Para obtener una guía completa sobre la configuración de los controles de acceso en Secret Manager, consulta la documentación sobre el control de acceso.
Conexión de BigQuery en Airflow
Asegúrate de crear la conexión sfdc_cdc_bq según la sección Recopilación de la configuración de Cloud Composer. Es probable que el módulo de Salesforce a BigQuery use esta conexión para establecer comunicación con BigQuery.
Próximos pasos
- Para obtener más información sobre otras fuentes de datos y cargas de trabajo, consulta Fuentes de datos y cargas de trabajo.
- Para obtener más información sobre los pasos para la implementación en entornos de producción, consulta Requisitos previos para la implementación de la base de datos de Cortex Framework.