Intégration à Salesforce (SFDC)
Cette page décrit les étapes d'intégration de la charge de travail opérationnelle Salesforce (SFDC) dans la base de données Cortex Framework. Cortex Framework intègre les données de Salesforce aux pipelines Dataflow dans BigQuery, tandis que Cloud Composer planifie et surveille ces pipelines Dataflow pour obtenir des insights à partir de vos données.
Fichier de configuration
Le fichier config.json du dépôt Cortex Framework Data Foundation configure les paramètres requis pour transférer des données depuis n'importe quelle source de données, y compris Salesforce. Ce fichier contient les paramètres suivants pour les charges de travail opérationnelles Salesforce :
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
Le tableau suivant décrit la valeur de chaque paramètre opérationnel SFDC :
| Paramètre | Signification | Valeur par défaut | Description |
SFDC.deployCDC
|
Déployer la CDC | true
|
Générez des scripts de traitement CDC à exécuter en tant que DAG dans Cloud Composer. Consultez la documentation pour découvrir les différentes options d'ingestion pour Salesforce Sales Cloud. |
SFDC.createMappingViews
|
Créer des vues de mappage | true
|
Les DAG fournis pour extraire de nouveaux enregistrements à partir des API Salesforce mettent à jour les enregistrements à l'arrivée. Si cette valeur est définie sur "true", des vues sont générées dans l'ensemble de données traité par CDC pour exposer les tables avec la "dernière version de la vérité" de l'ensemble de données brut. Si la valeur est "false" et que SFDC.deployCDC est true, les DAG sont générés avec le traitement de la capture des données modifiées (CDC, Change Data Capture) basé sur SystemModstamp. Pour en savoir plus, consultez Traitement CDC pour Salesforce.
|
SFDC.createPlaceholders
|
Créer des espaces réservés | true
|
Créez des tables de substitution vides au cas où elles ne seraient pas générées par le processus d'ingestion pour permettre au déploiement de reporting en aval de s'exécuter sans échec. |
SFDC.datasets.raw
|
Ensemble de données brutes de la page de destination | - | Utilisé par le processus CDC, c'est là que l'outil de réplication dépose les données de Salesforce. Si vous utilisez des données de test, créez un ensemble de données vide. |
SFDC.datasets.cdc
|
Ensemble de données traitées du CDC | - | Ensemble de données qui sert de source pour les vues de reporting et de cible pour les DAG de traitement des enregistrements. Si vous utilisez des données de test, créez un ensemble de données vide. |
SFDC.datasets.reporting
|
Ensemble de données de reporting SFDC | "REPORTING_SFDC"
|
Nom de l'ensemble de données accessible aux utilisateurs finaux pour le reporting, où les vues et les tables destinées aux utilisateurs sont déployées. |
SFDC.currencies
|
Filtrer les devises | [ "USD" ]
|
Si vous n'utilisez pas de données de test, saisissez une seule devise (par exemple, [ "USD" ]) ou plusieurs devises (par exemple, [ "USD", "CAD" ]), selon ce qui convient à votre entreprise.
Ces valeurs sont utilisées pour remplacer les espaces réservés dans le code SQL des modèles analytiques, le cas échéant.
|
Modèle de données
Cette section décrit le modèle de données Salesforce (SFDC) à l'aide du diagramme entité-relation (ERD).
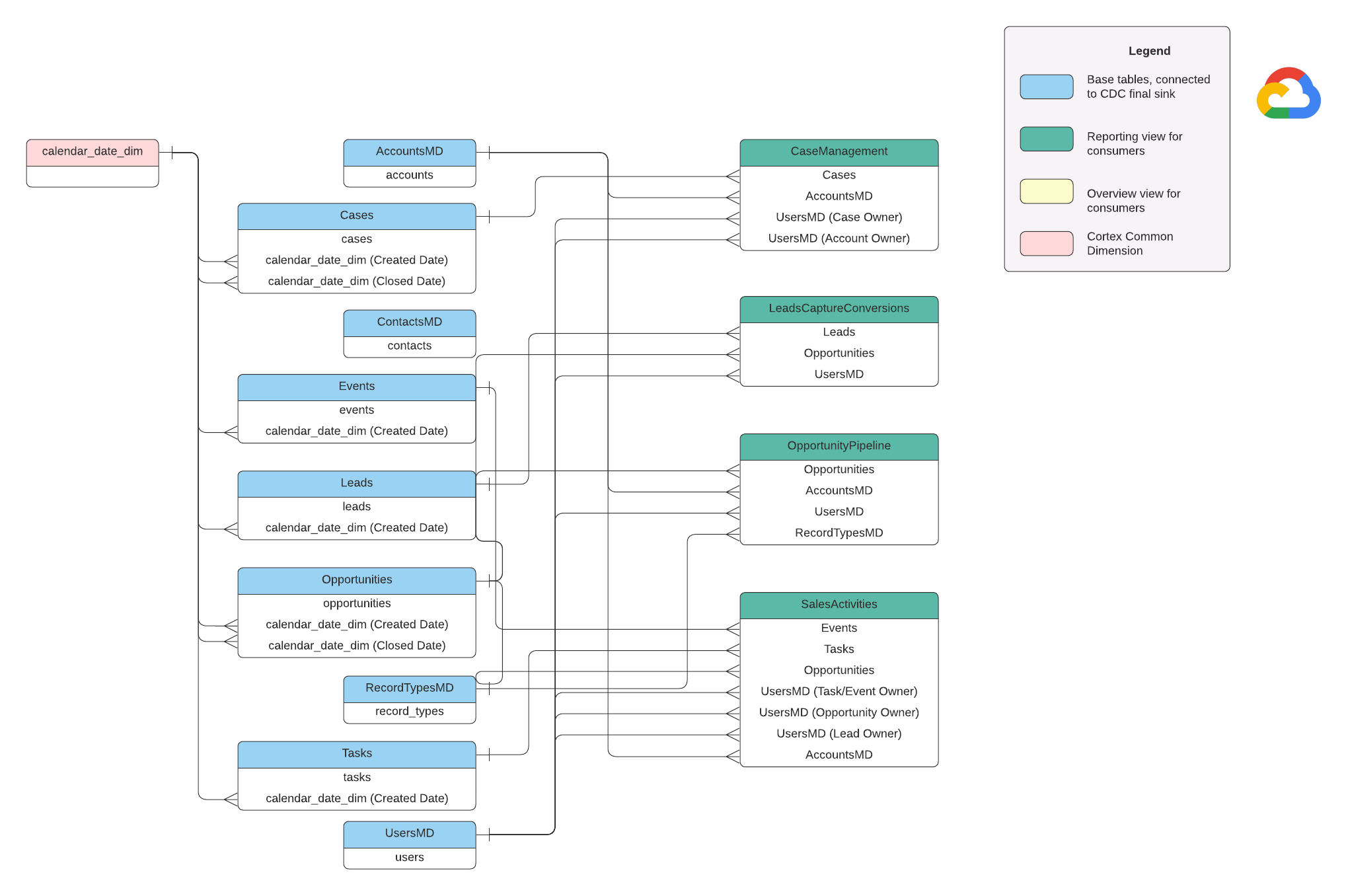
Vues de base
Il s'agit des objets bleus du diagramme ERD, qui sont des vues sur les tables CDC sans transformations, à l'exception de certains alias de noms de colonnes. Consultez les scripts dans src/SFDC/src/reporting/ddls.
Vues de rapports
Il s'agit des objets verts du diagramme entité-relation. Ils contiennent les attributs dimensionnels pertinents utilisés par les tables de rapport. Consultez les scripts dans src/SFDC/src/reporting/ddls.
Exigences concernant les données Salesforce
Cette section décrit en détail la structure que doivent avoir vos données Salesforce pour être utilisées avec Cortex Framework.
- Structure du tableau :
- Nommage : les noms de tables utilisent
snake_case(mots en minuscules séparés par des traits de soulignement) et sont au pluriel. Par exemple,some_objects. - Types de données : les colonnes conservent les mêmes types de données que ceux représentés dans Salesforce.
- Lisibilité : certains noms de champs peuvent être légèrement modifiés pour plus de clarté dans la couche de reporting.
- Nommage : les noms de tables utilisent
- Tables vides et déploiement : toutes les tables requises manquantes dans l'ensemble de données brutes sont automatiquement créées en tant que tables vides lors du processus de déploiement. Cela garantit une exécution fluide de l'étape de déploiement du CDC.
- Exigences concernant la CDC : les champs
IdetSystemModstampsont essentiels pour que les scripts CDC puissent suivre les modifications apportées à vos données. Ils peuvent porter ces noms exacts ou d'autres noms. Les scripts de traitement brut fournis récupèrent automatiquement ces champs à partir des API et mettent à jour la table de réplication cible.Id: identifiant unique de chaque enregistrement.SystemModstamp: ce champ stocke un code temporel indiquant la dernière modification d'un enregistrement.
- Scripts de traitement des données brutes : les scripts de traitement des données brutes fournis ne nécessitent pas de traitement supplémentaire (CDC). Ce comportement est défini par défaut lors du déploiement.
Tables sources pour la conversion des devises
Salesforce vous permet de gérer les devises de deux façons :
- De base : il s'agit de l'option par défaut, où toutes les données utilisent une seule devise.
- Avancé : permet de convertir plusieurs devises en fonction des taux de change (nécessite l'activation de la gestion avancée des devises).
Si vous utilisez la gestion avancée des devises, Salesforce utilise deux tables spéciales :
- CurrencyTypes : ce tableau stocke des informations sur les différentes devises que vous utilisez (USD, EUR, etc.).
- DatedConversionRates : ce tableau contient les taux de change entre les devises au fil du temps.
Cortex Framework s'attend à ce que ces tables soient présentes si vous utilisez la gestion avancée des devises. Si vous n'utilisez pas la gestion avancée des devises, vous pouvez supprimer les entrées liées à ces tables d'un fichier de configuration (src/SFDC/config/ingestion_settings.yaml). Cette étape permet d'éviter les tentatives inutiles d'extraction de données à partir de tables inexistantes.
Charger des données SFDC dans BigQuery
Cortex Framework fournit une solution de réplication basée sur des scripts Python planifiés dans Apache Airflow et l'API Salesforce Bulk 2.0. Ces scripts Python peuvent être adaptés et planifiés dans l'outil de votre choix. Pour en savoir plus, consultez Module d'extraction SFDC.
Cortex Framework propose également trois méthodes différentes pour intégrer vos données, en fonction de leur origine et de la façon dont elles sont gérées :
- Appels d'API : cette option concerne les données accessibles directement via une API. Cortex Framework peut appeler l'API, récupérer les données et les stocker dans un ensemble de données "brutes" dans BigQuery. Si l'ensemble de données contient déjà des enregistrements, Cortex Framework peut les mettre à jour avec les nouvelles données.
- Vues de mappage de structure : cette méthode est utile si vous avez déjà chargé vos données dans BigQuery à l'aide d'un autre outil, mais que la structure des données ne correspond pas à celle requise par Cortex Framework. Cortex Framework utilise des "vues" (comme des tables virtuelles) pour traduire la structure de données existante au format attendu par les fonctionnalités de reporting de Cortex Framework.
Scripts de traitement CDC (Change Data Capture) : cette option est spécifiquement conçue pour les données qui changent constamment. Les scripts CDC suivent ces modifications et mettent à jour les données dans BigQuery en conséquence. Ces scripts s'appuient sur deux champs spéciaux dans vos données :
Id: identifiant unique de chaque enregistrement.SystemModstamp: code temporel indiquant la date de modification d'un enregistrement.
Si vos données ne portent pas exactement ces noms, vous pouvez ajuster les scripts pour qu'ils les reconnaissent sous d'autres noms. Vous pouvez également ajouter des champs personnalisés à votre schéma de données au cours de ce processus. Par exemple, la table source avec les données de l'objet "Compte" doit comporter les champs d'origine
IdetSystemModstamp. Si ces champs ont des noms différents, le fichiersrc/SFDC/src/table_schema/accounts.csvdoit être mis à jour avec le nom du champIdmappé surAccountIdet le champ d'horodatage de modification du système mappé surSystemModstamp. Pour en savoir plus, consultez la documentation sur SystemModStamp.
Si vous avez déjà chargé des données à l'aide d'un autre outil (et qu'elles sont constamment mises à jour), Cortex peut toujours les utiliser. Les scripts CDC sont fournis avec des fichiers de mappage qui peuvent traduire votre structure de données existante au format requis par Cortex Framework. Vous pouvez même ajouter des champs personnalisés à vos données au cours de ce processus.
Configurer l'intégration de l'API et la CDC
Pour importer vos données Salesforce dans BigQuery, vous pouvez procéder de l'une des manières suivantes :
- Scripts Cortex pour les appels d'API : fournit des scripts de réplication pour Salesforce ou un outil de réplication de données de votre choix.L'important est que les données que vous importez doivent être identiques à celles provenant des API Salesforce.
- Outil de réplication et ajout systématique : si vous utilisez un outil de réplication, cette méthode est destinée à un outil qui peut ajouter de nouveaux enregistrements de données (_appendalways_pattern) ou mettre à jour des enregistrements existants.
- Outil de réplication et ajout de nouveaux enregistrements : si l'outil ne met pas à jour les enregistrements et réplique les modifications en tant que nouveaux enregistrements dans une table cible (brute), Cortex Data Foundation permet de créer des scripts de traitement CDC. Pour en savoir plus, consultez la section sur le processus CDC.

Pour vous assurer que vos données correspondent à ce que Cortex Framework attend, vous pouvez ajuster la configuration du mappage afin de mapper votre outil de réplication ou vos schémas existants. Cela génère des vues de mappage compatibles avec la structure attendue par Cortex Framework Data Foundation.
Utilisez le fichier ingestion_settings.yaml pour configurer la génération de scripts permettant d'appeler les API Salesforce et de répliquer les données dans l'ensemble de données brutes (section salesforce_to_raw_tables), ainsi que la génération de scripts permettant de traiter les modifications entrantes dans l'ensemble de données brutes et dans l'ensemble de données traitées CDC (section raw_to_cdc_tables).
Par défaut, les scripts fournis pour lire les données des API mettent à jour les modifications dans l'ensemble de données "Brutes". Les scripts de traitement CDC ne sont donc pas nécessaires. À la place, des vues de mappage sont créées pour aligner le schéma source sur le schéma attendu.
La génération de scripts de traitement CDC n'est pas exécutée si SFDC.createMappingViews=true dans config.json (comportement par défaut). Si des scripts CDC sont requis, définissez SFDC.createMappingViews=false. Cette deuxième étape permet également de mapper les schémas sources dans les schémas requis par la base de données Cortex Framework.
L'exemple suivant de fichier de configuration setting.yaml illustre la génération de vues de mappage lorsqu'un outil de réplication met à jour les données directement dans l'ensemble de données répliqué, comme illustré dans option 3 (c'est-à-dire qu'aucune CDC n'est requise, seul le remappage des tables et des noms de champs). Aucun CDC n'étant requis, cette option s'exécute tant que le paramètre SFDC.createMappingViews du fichier config.json reste défini sur true.
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
Dans cet exemple, la suppression de la configuration d'une table de base ou de toutes les tables de base des sections ignore la génération des DAG de cette table de base ou de l'ensemble de la section, comme illustré pour salesforce_to_raw_tables. Dans ce scénario, la définition du paramètre deployCDC : False a le même effet, car aucun script de traitement CDC n'a besoin d'être généré.
Mappage de données
Vous devez mapper les champs de données entrants au format attendu par Cortex Data Foundation. Par exemple, un champ nommé unicornId provenant de votre système de données source doit être renommé et reconnu comme AccountId (avec un type de données de chaîne) dans Cortex Data Foundation :
- Champ source :
unicornId(nom utilisé dans le système source) - Champ Cortex :
AccountId(nom attendu par Cortex) - Type de données :
String(type de données attendu par Cortex)
Mapper les champs polymorphes
La couche de données Cortex Framework permet de mapper les champs polymorphes, c'est-à-dire les champs dont le nom peut varier, mais dont la structure reste cohérente. Les noms de types de champs polymorphes (par exemple, Who.Type) peuvent être répliqués en ajoutant un élément [Field Name]_Type dans les fichiers CSV de mappage respectifs : src/SFDC/src/table_schema/tasks.csv. Par exemple, si vous avez besoin que le champ Who.Type de l'objet Task soit répliqué, ajoutez la ligne Who_Type,Who_Type,STRING. Cela définit un nouveau champ nommé Who.Type qui se mappe à lui-même (conserve le même nom) et possède un type de données de chaîne.
Modifier les modèles de DAG
Vous devrez peut-être ajuster les modèles de DAG pour la CDC ou pour le traitement des données brutes en fonction des besoins de votre instance Airflow ou Cloud Composer. Pour en savoir plus, consultez Collecter les paramètres Cloud Composer.
Si vous n'avez pas besoin de la CDC ni de la génération de données brutes à partir des appels d'API, définissez deployCDC=false. Vous pouvez également supprimer le contenu des sections dans ingestion_settings.yaml. Si les structures de données sont connues pour être cohérentes avec celles attendues par la Data Foundation de Cortex Framework, vous pouvez ignorer le paramètre de génération des vues de mappage SFDC.createMappingViews=false.
Configurer le module d'extraction
Cette section présente les étapes à suivre pour utiliser le module d'extraction Salesforce vers BigQuery fourni par Data Foundation. Vos exigences et votre flux peuvent varier en fonction de votre système et de votre configuration existante. Vous pouvez également utiliser d'autres outils disponibles.
Configurer les identifiants et l'application associée
Connectez-vous en tant qu'administrateur à votre instance Salesforce pour effectuer les opérations suivantes :
- Créez ou identifiez un profil dans Salesforce qui répond aux exigences suivantes :
Permission for Apex REST Services and API Enabledest accordé dans Autorisations système.- L'autorisation
View Allest accordée pour tous les objets que vous souhaitez répliquer. Par exemple, "Compte" et "Demandes". Vérifiez auprès de votre administrateur de sécurité s'il existe des restrictions ou des problèmes. - Aucune autorisation n'est accordée pour la connexion à l'interface utilisateur, comme Salesforce Anywhere dans Lightning Experience, Salesforce Anywhere sur mobile, Utilisateur Lightning Experience et Utilisateur de connexion Lightning. Vérifiez s'il existe des restrictions ou des problèmes avec votre administrateur de sécurité.
- Créez un utilisateur ou identifiez-en un existant dans Salesforce. Vous devez connaître le nom d'utilisateur, le mot de passe et le jeton de sécurité de l'utilisateur. Tenez compte des points suivants :
- Idéalement, il s'agit d'un utilisateur dédié à l'exécution de cette réplication.
- L'utilisateur doit être attribué au profil que vous avez créé ou identifié à l'étape 1.
- Vous pouvez consulter le nom d'utilisateur et réinitialiser le mot de passe ici.
- Vous pouvez réinitialiser le jeton de sécurité si vous ne l'avez pas et qu'il n'est pas utilisé par un autre processus.
- Créez une application connectée. Il s'agit du seul canal de communication permettant d'établir une connexion à Salesforce depuis le monde extérieur à l'aide d'un profil, de l'API Salesforce, d'identifiants utilisateur standards et de son jeton de sécurité.
- Suivez les instructions pour activer les paramètres OAuth pour l'intégration de l'API.
- Assurez-vous que
Require Secret for Web Server FlowetRequire Secretfor Refresh Token Flowsont activés dans la section API (Enabled OAuth Settings) (API [Paramètres OAuth activés]). - Consultez la documentation pour savoir comment obtenir votre clé consommateur (qui sera utilisée ultérieurement comme ID client). Contactez votre administrateur de sécurité pour connaître les problèmes ou les restrictions.
- Attribuez votre application connectée au profil créé.
- En haut à droite de l'écran d'accueil Salesforce, sélectionnez Configuration.
- Dans la zone Quick Find (Recherche rapide), saisissez
profile, puis sélectionnez Profile (Profil). Recherchez le profil créé à l'étape 1. - Ouvrez le profil.
- Cliquez sur le lien Applications connectées attribuées.
- Cliquez sur Modifier.
- Ajoutez l'application connectée que vous venez de créer.
- Cliquez sur le bouton Enregistrer.
Configurer Secret Manager
Configurez Secret Manager pour stocker les informations de connexion. Le module Salesforce vers BigQuery s'appuie sur Secret Manager pour stocker de manière sécurisée les identifiants dont il a besoin pour se connecter à Salesforce et BigQuery. Cette approche évite d'exposer des informations sensibles telles que des mots de passe directement dans votre code ou vos fichiers de configuration, ce qui renforce la sécurité.
Créez un secret avec les spécifications suivantes. Pour obtenir des instructions détaillées, consultez Créer un secret.
- Nom du secret :
airflow-connections-salesforce-conn Valeur du code secret :
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`Remplacez les éléments suivants :
USERNAMEpar votre nom d'utilisateur.PASSWORDavec votre mot de passe.INSTANCE_NAMEpar le nom de l'instance.CLIENT_IDpar votre ID client.SECRET_TOKENpar votre jeton secret.
Pour en savoir plus, consultez Trouver le nom de votre instance.
Bibliothèques Cloud Composer pour la réplication
Pour exécuter les scripts Python dans les DAG fournis par la base de données Cortex Framework, vous devez installer certaines dépendances. Pour Airflow version 1.10, suivez la documentation Installer les dépendances Python pour Cloud Composer 1 pour installer les packages suivants, dans l'ordre :
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
Pour Airflow version 2.x, consultez la documentation Installer des dépendances Python pour Cloud Composer 2 pour installer apache-airflow-providers-salesforce~=5.2.0.
Exécutez la commande suivante pour installer chaque package requis :
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
Remplacez les éléments suivants :
ENVIRONMENT_NAMEpar le nom de l'environnement attribué.LOCATIONpar l'emplacement.PACKAGE_NAMEpar le nom de package choisi.EXTRAS_AND_VERSIONavec les spécifications des extras et de la version.
La commande suivante est un exemple d'installation de package requise :
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
Activer Secret Manager en tant que backend
Activez Google Secret Manager comme backend de sécurité. Cette étape vous explique comment activer Secret Manager comme emplacement de stockage principal pour les informations sensibles telles que les mots de passe et les clés API utilisés par votre environnement Cloud Composer. Cela améliore la sécurité en centralisant et en gérant les identifiants dans un service dédié. Pour en savoir plus, consultez Secret Manager.
Autoriser le compte de service Composer à accéder aux secrets
Cette étape permet de s'assurer que le compte de service associé à Cloud Composer dispose des autorisations nécessaires pour accéder aux secrets stockés dans Secret Manager.
Par défaut, Cloud Composer utilise le compte de service Compute Engine.
L'autorisation requise est Secret Manager Secret Accessor.
Cette autorisation permet au compte de service de récupérer et d'utiliser les secrets stockés dans Secret Manager.Pour obtenir un guide complet sur la configuration des contrôles d'accès dans Secret Manager, consultez la documentation sur le contrôle des accès.
Connexion BigQuery dans Airflow
Assurez-vous de créer la connexion sfdc_cdc_bq en suivant Collecter les paramètres Cloud Composer. Cette connexion est probablement utilisée par le module Salesforce vers BigQuery pour établir la communication avec BigQuery.
Étape suivante
- Pour en savoir plus sur les autres sources de données et charges de travail, consultez Sources de données et charges de travail.
- Pour en savoir plus sur les étapes de déploiement dans les environnements de production, consultez Conditions préalables au déploiement de la couche de données du framework Cortex.