与 Salesforce Marketing Cloud 的集成
本页介绍了将 Salesforce Marketing Cloud (SFMC) 中的数据作为 Cortex Framework Data Foundation 营销工作负载的数据源所需的配置。
SFMC 是 Salesforce 提供的数字营销自动化平台。它为企业提供了一套全面的工具,可跨多个渠道管理和自动执行各种营销活动。Cortex Framework 可用作数据分析和 AI 引擎,帮助您了解成效、确定需要改进的方面,并优化营销策略,从而取得更理想的成效。
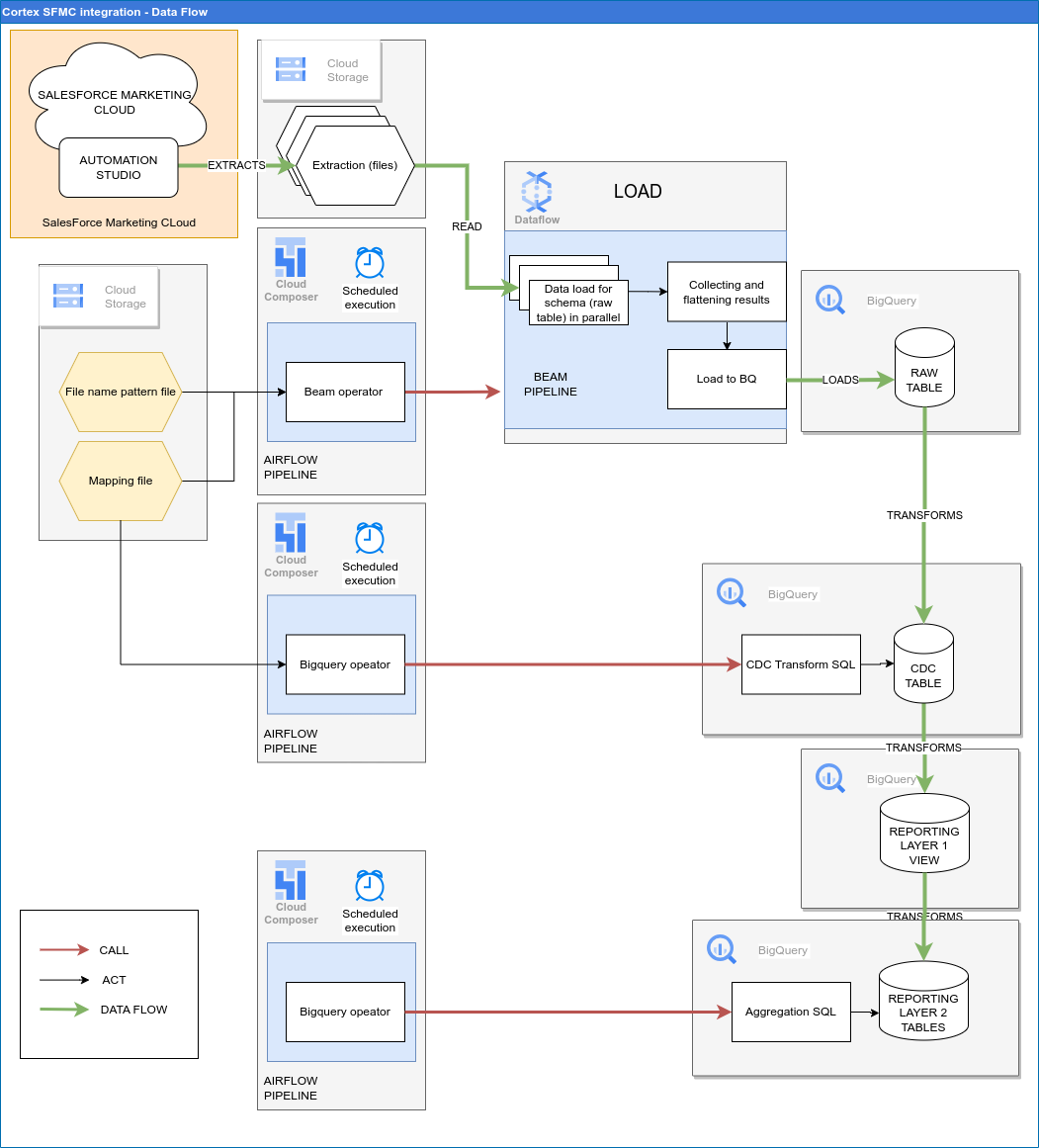
下图描述了如何通过 Cortex Framework Data Foundation 的营销工作负载获取 SFMC 数据:
配置文件
config.json 文件用于配置连接到数据源以从各种工作负载传输数据所需的设置。此文件包含 SFMC 的以下参数:
"marketing": {
"deploySFMC": true,
"SFMC": {
"deployCDC": true,
"fileTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFMC"
}
}
}
下表介绍了每项营销参数的值:
| 参数 | 含义 | 默认值 | 说明 |
marketing.deploySFMC
|
部署 SFMC | true
|
为 SFMC 数据源执行部署。 |
marketing.SFMC.deployCDC
|
为 SFMC 部署 CDC 脚本 | true
|
生成 Salesforce Marketing Cloud (SFMC) CDC 处理脚本,以便在 Cloud Composer 中作为 DAG 运行。 |
marketing.SFMC.fileTransferBucket
|
包含数据提取文件的存储分区 | - | 存储 Salesforce Marketing Cloud (SFMC) Automation Studio 数据提取文件的存储分区。 |
marketing.SFMC.datasets.cdc
|
适用于 SFMC 的 CDC 数据集 | 适用于 Salesforce Marketing Cloud (SFMC) 的 CDC 数据集。 | |
marketing.SFMC.datasets.raw
|
SFMC 的原始数据集 | Salesforce Marketing Cloud (SFMC) 的原始数据集。 | |
marketing.SFMC.datasets.reporting
|
适用于 SFMC 的报告数据集 | "REPORTING_SFMC"
|
Salesforce Marketing Cloud (SFMC) 的报告数据集。 |
数据模型
本部分使用实体关系图 (ERD) 介绍 Salesforce Marketing Cloud (SFMC) 数据模型。
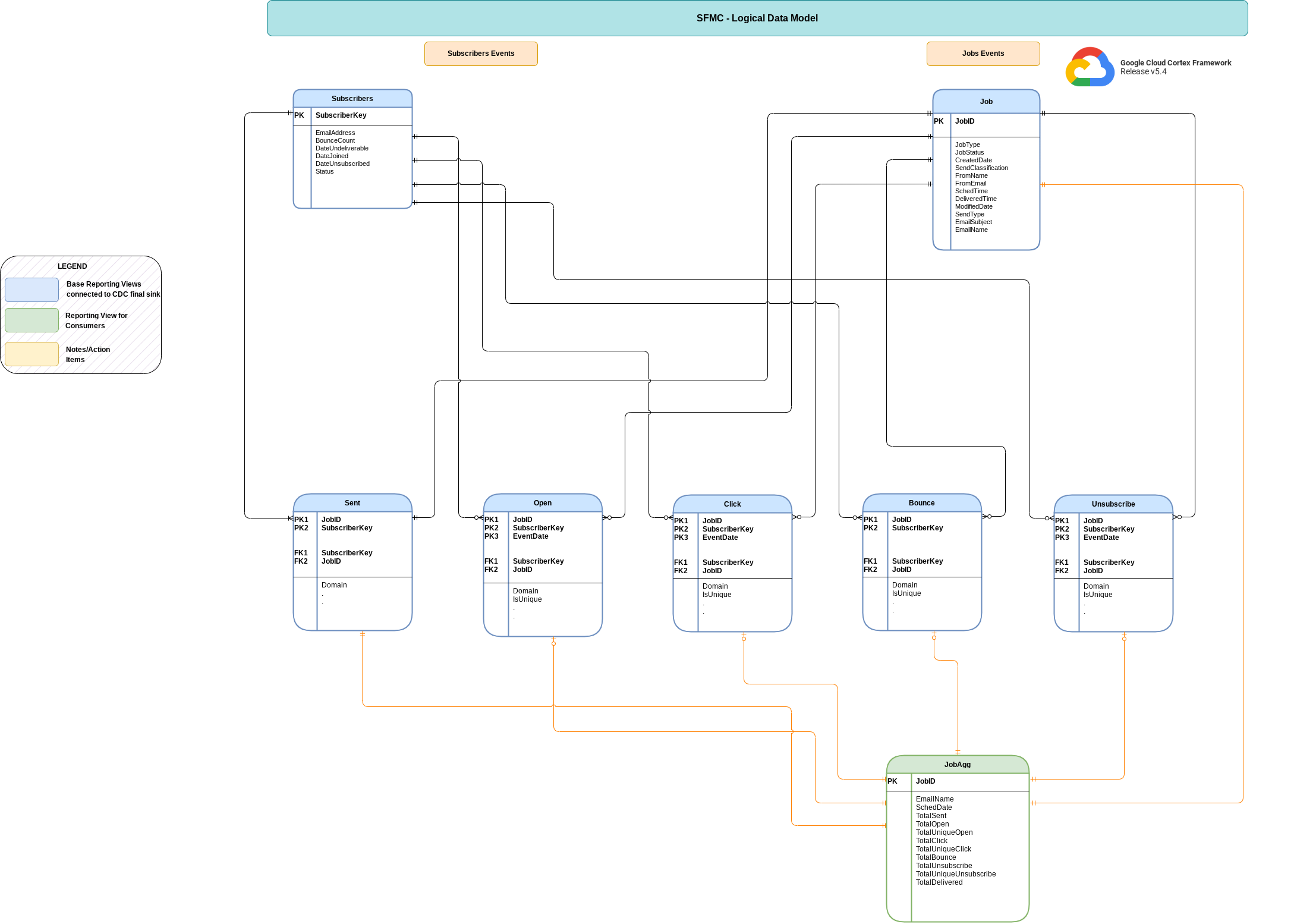
基本视图
这些是 ERD 中的蓝色对象,是 CDC 表上的视图,除了一些列名称别名之外,没有其他转换。请参阅 src/marketing/src/SFMC/src/reporting/ddls 中的脚本。
报告数据视图
这些是 ERD 中的绿色对象,是包含汇总指标的报告视图。请参阅 src/marketing/src/SFMC/src/reporting/ddls 中的脚本。
使用 Automation Studio 提取数据
借助 SFMC Automation Studio,SFMC 使用方可以将其 SFMC 数据导出到各种存储系统。Cortex Framework Data Foundation 会在 Cloud Storage 存储分区中查找使用 Automation Studio 创建的一组文件。您还需要在此过程中使用 SFMC Email Studio。
如需设置数据提取和导出流程,请按以下步骤操作:
- 设置 Cloud Storage 存储分区。此存储分区用于存储从 SFMC 导出的文件。为存储分区
marketing.SFMC.fileTransferBucket配置参数命名。请参阅 Salesforce 文档中的说明。 创建数据附加信息。对于您要提取数据的每个实体,请在电子邮件营销工作室中创建数据扩展。这对于从 SFMC 内部数据库中识别数据源至关重要。
- 列出为实体在
src/SFMC/config/table_schema中定义的所有字段。如果您需要自定义此参数以提取更多或更少的字段,请确保这些步骤中的字段列表以及表架构文件中的字段列表保持一致。例如:
Entity: unsubscribe Fields: AccountID OYBAccountID JobID ListID BatchID SubscriberID SubscriberKey EventDate IsUnique Domain- 列出为实体在
创建 SQL 查询 activity。为每个实体创建一个 SQL 查询 activity。此活动与之前创建的相应数据扩展程序相关联。 如需了解此步骤,请参阅 Salesforce 文档 :
- 使用所有相关字段定义 SQL 查询。该查询需要选择与上一步中数据扩展程序中定义的实体相关的所有字段。
- 选择正确的数据扩展程序作为目标。
- 选择覆盖作为数据操作。
- 请参阅以下示例查询:
SELECT AccountID, OYBAccountID, JobID, ListID, BatchID, SubscriberID, SubscriberKey, EventDate, IsUnique, Domain FROM _Unsubscribe创建数据提取 activity。如需了解如何为每个实体创建数据提取活动 ,请参阅 Salesforce 文档。此 activity 会从 Salesforce 数据扩展程序获取数据,并将其提取到 CSV 文件。在此步骤中:
- 使用正确的命名模式。它应与设置中定义的模式匹配。例如,对于
Unsubscribe实体,文件名可以是unsubscribe_%%Year%%_%%Month%%_%%Day%% %%Hour%%.csv之类的名称。 - 将提取类型设置为
Data Extension Extract。 - 选择包含列标题和文本符合条件选项。
- 使用正确的命名模式。它应与设置中定义的模式匹配。例如,对于
创建文件转换 activity 以将格式从 UTF-16 转换为 UTF-8。默认情况下,Salesforce 会以 UTF-16 格式导出 CSV 文件。在此步骤中,您需要将其转换为 UTF-8 格式。为每个实体创建另一个数据提取 activity,以进行文件转换。在此步骤中:
- 使用与“数据提取 activity”上一步中所用的文件名格式相同的格式。
- 将提取类型设置为
File Convert - 从
Convert To下拉菜单中选择UTF8。
创建文件传输 activity。为每个实体创建一个文件传输 activity。这些 activity 会将提取的 CSV 文件从 Salesforce Safehouse 移至 Cloud Storage 存储分区。在此步骤中:
- 使用与前面步骤中相同的文件名格式。
- 选择在流程前面部分设置的 Cloud Storage 存储分区作为目标位置。
安排执行作业。完成所有活动后,设置自动时间表以运行这些活动。
数据新鲜度和延迟
一般而言,Cortex Framework 数据源的数据新鲜度受上游连接允许的程度以及 DAG 执行频率的限制。调整 DAG 执行频率,使其与上游频率、资源限制和业务需求保持一致。
使用 SFMC Automation Studio 时,数据新鲜度延迟取决于设置数据导出时的时间安排延迟。
Cloud Composer 连接权限
在 Cloud Composer 中创建以下连接。如需了解详情,请参阅“管理 Airflow 连接”文档。
| 连接名称 | 目的 |
sfmc_raw_dataflow
|
对于 SFMC 提取的文件,请选择“BigQueryRaw”数据集。 |
sfmc_cdc_bq
|
对于“原始数据集”>“CDC 数据集”转移。 |
sfmc_reporting_bq
|
对于 CDC 数据集,请依次选择“CDC 数据集”>“报告数据集转移”。 |
Cloud Composer 服务账号权限
Cloud Composer 中使用的服务账号(如 sfmc_raw_dataflow 连接中所配置)需要具有与 Dataflow 相关的权限。请参阅 Dataflow 文档中的说明
提取设置
通过 src/SFMC/config/ingestion_settings.yaml 文件中的设置控制 Source to Raw 和 Raw to CDC 数据流水线。本部分介绍了每个数据流水线的参数。
来源到原始表
此部分包含用于控制如何使用从 Automation Studio 中提取的文件的条目。每个条目都对应一个 SFMC 实体。根据此配置,Cortex Framework 会创建 Airflow DAG,用于运行 Dataflow 流水线,以将从导出文件中加载的数据加载到原始数据集中的 BigQuery 表中。
目录 src/SFMC/config/table_schema 包含从 SFMC 中提取的每个实体的架构文件。每份文件都介绍了如何读取从 Automaton Studio 中提取的 CSV 文件,以便将其成功加载到 BigQueryraw 数据集中。
每个架构文件包含三列:
SourceField:CSV 文件的字段名称。TargetField:此实体在原始表中的列名称。DataType:每个原始表字段的数据类型。
以下参数用于控制每个条目的 Source to Raw 设置:
| 参数 | 说明 |
base_table
|
用于加载 SFMC 实体提取的数据的原始表名称。 |
load_frequency
|
此实体的 DAG 运行以从提取的文件加载数据的频率。如需详细了解可能的值,请参阅 Airflow 文档。 |
file_pattern
|
从 Automation Studio 导出到 Cloud Storage 存储分区的此表的文件模式。 仅当您选择的名称与提取的文件的建议名称不同时,才应更改此设置。 |
partition_details
|
原始表的分区方式(出于性能方面的考虑)。如需了解详情,请参阅表分区。 |
cluster_details
|
可选:如果您希望出于性能考虑对原始表进行分片。如需了解详情,请参阅集群设置。 |
将原始表转换为 CDC 表
本部分介绍了哪些条目控制数据从原始表迁移到 CDC 表的方式。每个条目对应一个原始表。
以下参数用于控制每个条目的 Raw to CDC 设置:
| 参数 | 说明 |
base_table
|
CDC 数据集中的表,用于存储 CDC 转换后的原始数据。 |
load_frequency
|
此实体的 DAG 用于填充 CDC 表的运行频率。如需详细了解可能的值,请参阅 Airflow 文档。 |
raw_table
|
原始数据集中的源表。 |
row_identifiers
|
用于构成此表的唯一记录的列(以英文逗号分隔)。 |
partition_details
|
CDC 表的分区方式(出于性能方面的考虑)。如需了解详情,请参阅表分区。 |
cluster_details
|
可选:如果您希望出于性能考虑对此表进行分片。如需了解详情,请参阅集群设置。 |
报告设置
您可以使用报告设置文件 (src/SFMC/config/reporting_settings.yaml) 配置和控制 Cortex Framework 如何为 SFMC 最终报告层生成数据。此文件控制报告层 BigQuery 对象(表、视图、函数或存储过程)的生成方式。如需了解详情,请参阅自定义报告设置文件。
后续步骤
- 如需详细了解其他数据源和工作负载,请参阅数据源和工作负载。
- 如需详细了解在生产环境中部署的步骤,请参阅 Cortex Framework Data Foundation 部署前提条件。