与 Meta 集成
本页介绍了将 Meta(Facebook 和 Instagram Ads)中的数据作为 Cortex Framework Data Foundation 营销工作负载的数据源所需的配置。
Meta 是一家拥有多个热门在线平台的科技公司。Cortex Framework 可集成来自 Instagram 和 Facebook 的广告数据,对其进行分析,将其与其他数据源相结合,并利用 AI 技术获得更深入的数据洞见,优化您的营销策略。
下图描述了如何通过 Cortex Framework Data Foundation 的营销工作负载获取 Meta 营销数据:
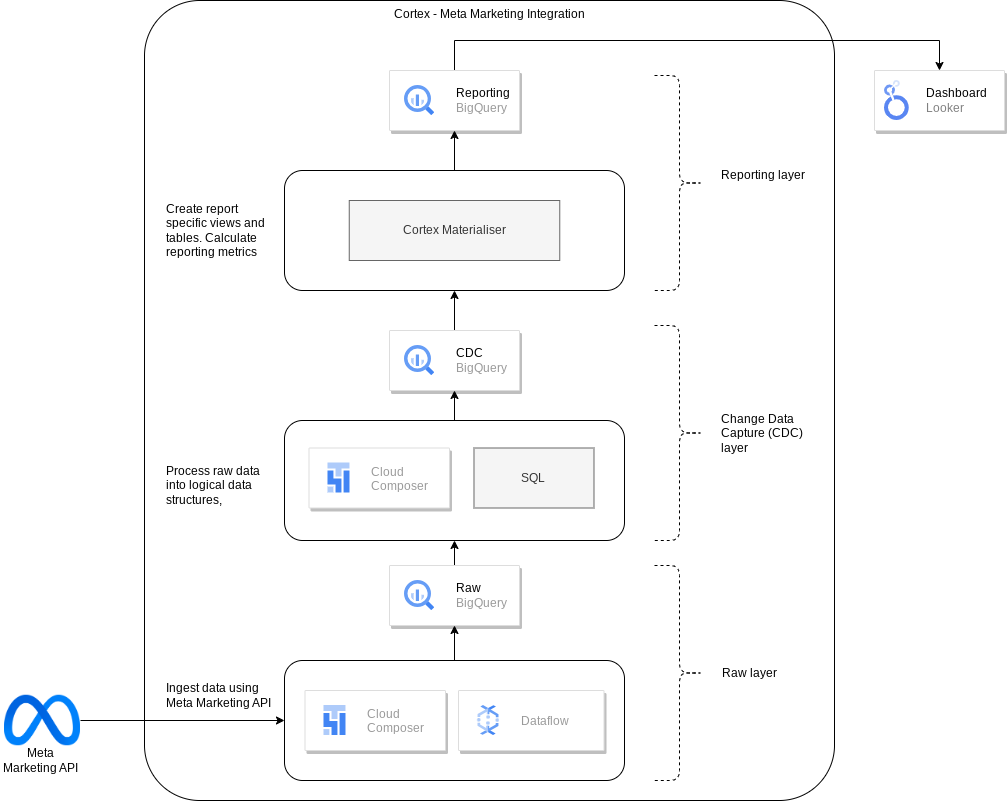
配置文件
config.json 文件用于配置连接到数据源以从各种工作负载传输数据所需的设置。此文件包含 Meta 的以下参数:
"marketing": {
"deployMeta": true,
"Meta": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_Meta"
}
}
}
下表介绍了每项营销参数的值:
| 参数 | 含义 | 默认值 | 说明 |
marketing.deployMeta
|
部署元数据 | true
|
为 Meta 的数据源执行部署。 |
marketing.Meta.deployCDC
|
为 Meta 部署 CDC 脚本 | true
|
生成 Meta CDC 处理脚本,以便在 Cloud Composer 中作为 DAG 运行。 |
marketing.Meta.datasets.cdc
|
适用于 Meta 的 CDC 数据集 | Meta 的 CDC 数据集。 | |
marketing.Meta.datasets.raw
|
Meta 的原始数据集 | Meta 的原始数据集。 | |
marketing.Meta.datasets.reporting
|
Meta 的报告数据集 | "REPORTING_Meta"
|
Meta 的报告数据集。 |
数据模型
本部分使用实体关系图 (ERD) 介绍了 Meta 的数据模型。
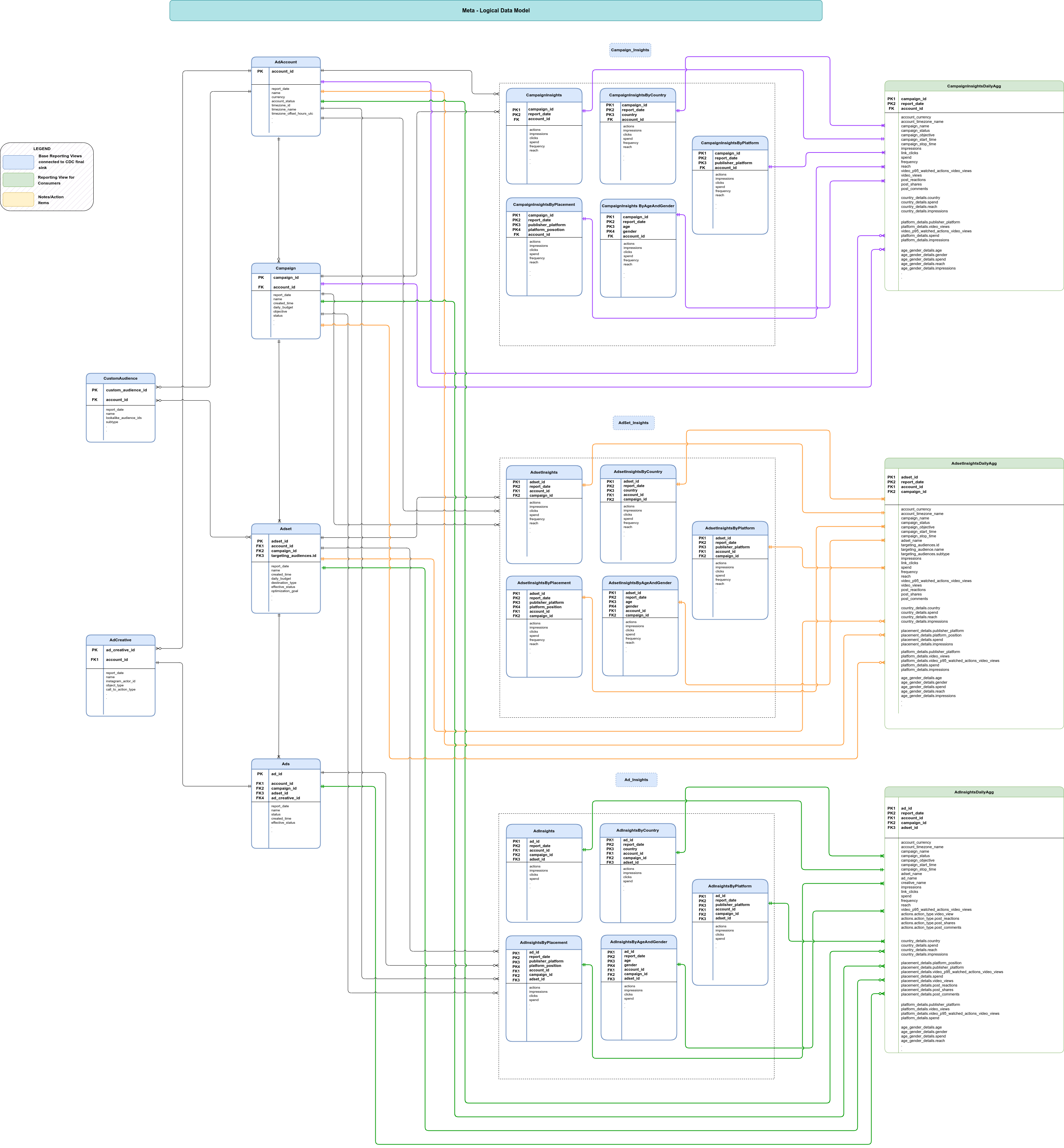
基本视图
这些是 ERD 中的蓝色对象,是 CDC 表上的视图,只需进行最少的转换即可解压缩复杂的数据结构。请参阅 src/marketing/src/Meta/src/reporting/ddls 中的脚本。
报告数据视图
这些是 ERD 中的绿色对象,是包含汇总指标的报告视图。请参阅 src/marketing/src/Meta/src/reporting/ddls 中的脚本。
API 连接
Cortex Framework for Meta 中的提取模板使用 Meta Marketing API 检索报告属性和指标。当前模板使用 v21.0 版。
Meta 在查询 Marketing API 时会强制执行动态速率限制。达到速率限制后,“从来源到原始数据”提取 DAG 可能无法成功完成。在这种情况下,您可以在日志中看到相关错误消息,并且 DAG 的下次执行会回溯加载所有缺失的数据。
Meta Marketing API 有两种访问权限级别,即基本级别和标准级别。标准层级提供的限制要高得多,如果您计划大量使用“从来源提取到原始”提取功能,建议您使用标准层级。如需详细了解这些限制以及如何获得更高的访问权限层级,请参阅 Meta 文档。
如果您有标准层级的访问权限,则可以降低 src/Meta/src/raw/pipelines/config.ini 中的 next_request_delay_sec 设置的值,以缩短加载时间。
API 访问权限和访问令牌
若要成功将 Meta 中的数据导入 Cortex Framework,您必须在 Meta 商家管理工具和开发者控制台中完成以下步骤。
- 确定要使用的应用。您可以创建一个新的应用,并将其与商家账号相关联。确保您的应用是
Business类型。 - 设置应用权限。您必须先被分配为应用的管理员,然后才能使用该应用创建令牌。请参阅应用角色文档。请务必为您的应用分配相关素材资源(账号)。
创建访问令牌。您必须使用访问令牌才能访问 Meta Marketing API,并且访问令牌始终与应用和用户相关联。您可以使用系统用户或自己的登录信息创建令牌。
按照 Cloud Composer 文档中的说明在 Cloud Composer 中启用 Secret Manager。然后,创建一个名为
cortex_meta_access_token的 Secret,并将您在上一步中生成的令牌存储为内容。
数据新鲜度和延迟
一般而言,Cortex Framework 数据源的数据新鲜度受上游连接允许的程度以及 DAG 执行频率的限制。调整 DAG 执行频率,使其与上游频率、资源限制和业务需求保持一致。
借助 Meta Marketing API,大多数数据(转化除外)可近乎实时获取,但最晚会在事件发生后的 28 天内进行调整。
Cloud Composer 连接权限
在 Cloud Composer 中创建以下连接。如需了解详情,请参阅“管理 Airflow 连接”文档。
| 连接名称 | 目的 |
meta_raw_dataflow
|
对于 Meta Marketing API > BigQuery 原始数据集 |
meta_cdc_bq
|
对于原始数据集 > CDC 数据集传输 |
meta_reporting_bq
|
对于 CDC 数据集 > 报告数据集传输 |
Cloud Composer 服务账号权限
向 Cloud Composer 中使用的服务账号(如 meta_raw_dataflow 连接中所配置)授予 Dataflow 权限。请参阅 Dataflow 文档中的说明。服务账号还需要具有 Secret Manager Secret Accessor 权限。如需了解详情,请参阅访问权限控制文档。
请求参数
目录 src/Meta/config/request_parameters 包含从 Meta Marketing API 中提取的每个实体的 API 请求规范文件。每个请求文件包含要从 Meta Marketing API 提取的字段列表,每行一个字段。如需了解详情,请参阅 Meta Marketing API 参考文档。
提取设置
通过 src/Meta/config/ingestion_settings.yaml 文件中的设置控制 Source to Raw 和 Raw to CDC 数据流水线。本部分介绍了每个数据流水线的参数。
来源到原始表
此部分包含用于控制 API 提取哪些实体以及如何提取的实体条目。每个条目都对应一个 Meta Marketing API 实体。根据此配置,Cortex Framework 会创建 Airflow DAG,以运行 Dataflow 流水线,以使用 Meta Marketing API 提取数据。
文件 src/Meta/src/raw/pipelines/config.ini 用于控制 Cloud Composer DAG 的某些行为以及 Meta Marketing API 的使用方式。查找文件中每个参数的说明。
以下参数用于控制每个条目的 Source to Raw 设置:
| 参数 | 说明 |
base_table
|
原始数据集中用于存储提取数据的表(例如 customer)。
|
load_frequency
|
用于从 Meta 提取数据的 DAG 的运行频率。如需详细了解可能的值,请参阅 Airflow 文档。 |
object_endpoint
|
API 端点路径(例如,campaigns 表示 /{account_id}/campaigns 端点)。
|
entity_type
|
表的类型(应为 fact、dimension 或 addaccount) 之一。
|
object_id_column
|
用于构成此表的唯一记录的列(以英文逗号分隔)。仅当 entity_type 为 fact 时才需要。
|
breakdowns
|
可选:数据分析端点的细分列(以英文逗号分隔)。仅在 entity_type 为 fact 时适用。
|
action_breakdowns
|
可选:数据分析端点的操作细分列(以英文逗号分隔)。仅在 entity_type 为 fact 时适用。
|
partition_details
|
可选:如果您希望出于性能考虑对此表进行分区。如需了解详情,请参阅表分区。 |
cluster_details
|
可选:如果您希望出于性能考虑对此表进行分片。如需了解详情,请参阅集群设置。 |
将原始表转换为 CDC 表
本部分介绍了用于控制如何将数据从原始表移至 CDC 表的条目。每个条目都对应一个原始表(该表又对应于前面提到的 Meta API 实体)。
以下参数用于控制每个条目的 Raw to CDC 设置:
| 参数 | 说明 |
base_table
|
已复制原始数据的表。CDC 数据集中同名表用于存储 CDC 转换后的原始数据(例如 campaign_insights)。
|
row_identifiers
|
用于构成此表的唯一记录的列(以英文逗号分隔)。 |
load_frequency
|
此实体的 DAG 运行以填充 CDC 表的频率。如需详细了解可能的值,请参阅 Airflow 文档。 |
partition_details
|
可选:如果您希望出于性能考虑对此表进行分区。如需了解详情,请参阅表分区。 |
cluster_details
|
可选:如果您希望出于性能考虑对此表进行分片。如需了解详情,请参阅集群设置。 |
CDC 表架构
对于 Meta,所有字段均以字符串格式存储在原始图层中。在 CDC 层中,基元类型会转换为相关的业务数据类型,并且所有复杂类型都存储为 BigQuery JSON 格式。
为了实现此转换,目录 src/Meta/config/table_schema 针对 raw_to_cdc_tables 部分中指定的每个实体包含一个架构文件,其中说明了如何正确将每个 BigQueryraw 表转换为 CDC 表。
每个架构文件包含三列:
SourceField:此实体的原始表的字段名称。TargetField:此实体在 CDC 表中的列名称。DataType:每个 CDC 表字段的数据类型。
报告设置
您可以使用报告设置文件 (src/Meta/config/reporting_settings.yaml) 配置和控制 Cortex 为 Meta 最终报告层生成数据的方式。此文件控制报告层 BigQuery 对象(表、视图、函数或存储过程)的生成方式。
如需了解详情,请参阅自定义报告设置文件。
后续步骤
- 如需详细了解其他数据源和工作负载,请参阅数据源和工作负载。
- 如需详细了解在生产环境中部署的步骤,请参阅 Cortex Framework Data Foundation 部署前提条件。