Intégration à Meta
Cette page décrit les configurations requises pour importer des données à partir de Meta (Facebook et Instagram Ads) en tant que source de données de la charge de travail marketing de Cortex Framework Data Foundation.
Meta est une entreprise technologique qui possède plusieurs plates-formes en ligne populaires. Cortex Framework intègre les données Ads d'Instagram et de Facebook pour les analyser, les combiner à d'autres sources de données et utiliser l'IA pour obtenir des insights plus précis et optimiser votre stratégie marketing.
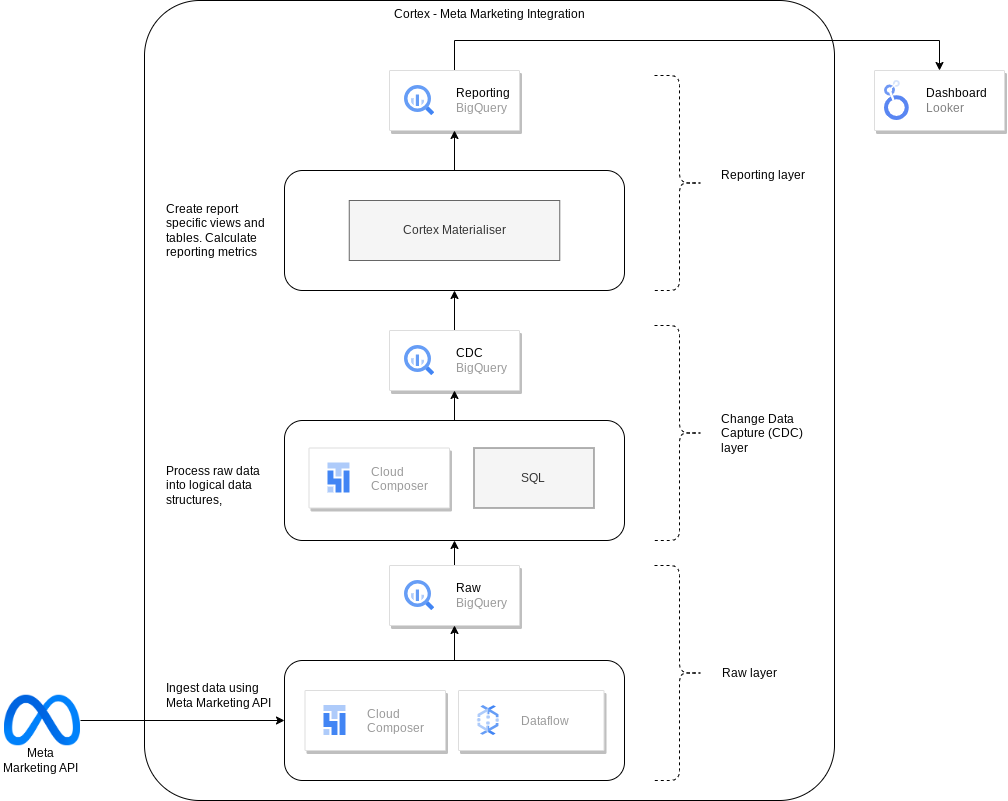
Le diagramme suivant décrit comment les données marketing Meta sont disponibles via la charge de travail marketing de Cortex Framework Data Foundation:
Fichier de configuration
Le fichier config.json configure les paramètres requis pour se connecter aux sources de données afin de transférer des données à partir de diverses charges de travail. Ce fichier contient les paramètres suivants pour Meta:
"marketing": {
"deployMeta": true,
"Meta": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_Meta"
}
}
}
Le tableau suivant décrit la valeur de chaque paramètre marketing:
| Paramètre | Signification | Valeur par défaut | Description |
marketing.deployMeta
|
Métadonnées de déploiement | true
|
Exécutez le déploiement pour la source de données de Meta. |
marketing.Meta.deployCDC
|
Déployer des scripts CDC pour Meta | true
|
Générez des scripts de traitement Meta CDC à exécuter en tant que DAG dans Cloud Composer. |
marketing.Meta.datasets.cdc
|
Ensemble de données CDC pour Meta | Ensemble de données du CDC pour Meta. | |
marketing.Meta.datasets.raw
|
Ensemble de données brut pour Meta | Ensemble de données brut pour Meta. | |
marketing.Meta.datasets.reporting
|
Ensemble de données de création de rapports pour Meta | "REPORTING_Meta"
|
Ensemble de données de reporting pour Meta. |
Modèle de données
Cette section décrit le modèle de données de Meta à l'aide du diagramme des relations entre entités (ERD).
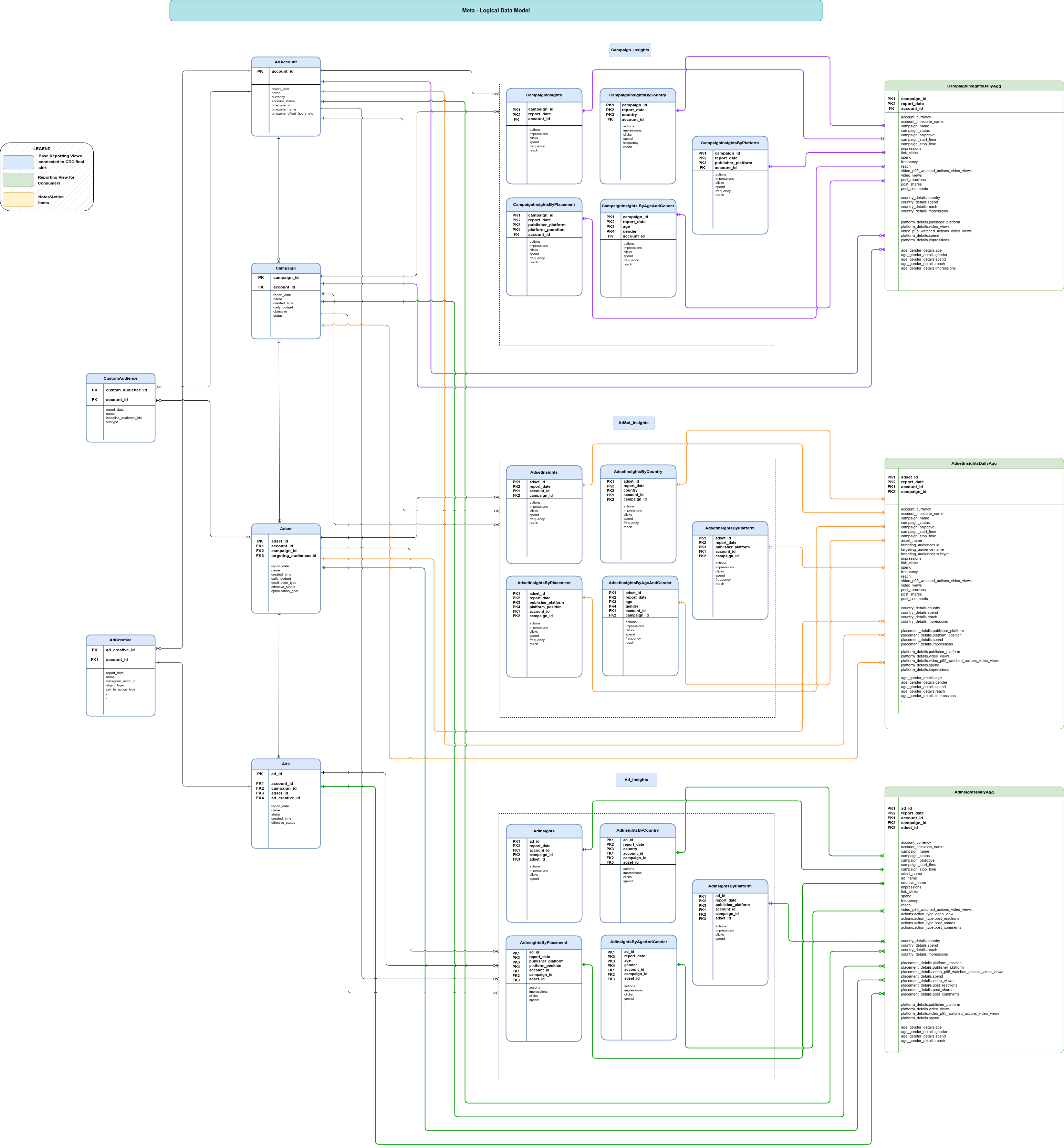
Vues de base
Il s'agit des objets bleus de l'ERD. Il s'agit de vues sur les tables CDC avec des transformations minimales pour décompresser des structures de données complexes. Consultez les scripts dans src/marketing/src/Meta/src/reporting/ddls.
Vues de rapports
Il s'agit des objets verts de l'ERD. Il s'agit de vues de rapports contenant des métriques agrégées. Consultez les scripts dans src/marketing/src/Meta/src/reporting/ddls.
Connexion à l'API
Les modèles d'ingestion de Cortex Framework pour Meta utilisent l'API Meta Marketing pour récupérer les attributs et les métriques de reporting. Les modèles actuels utilisent la version v21.0.
Meta impose une limite de débit dynamique lors de l'interrogation de l'API Marketing. Lorsque la limite de débit est atteinte, les DAG d'ingestion de la source vers le format brut peuvent ne pas aboutir. Dans ce cas, des messages d'erreur pertinents s'affichent dans le journal, et l'exécution suivante des DAG charge rétroactivement les données manquantes.
L'API Meta Marketing propose deux niveaux d'accès : de base et standard. Le niveau standard offre une limite beaucoup plus élevée et est recommandé si vous prévoyez d'utiliser l'ingestion de source à brut de manière intensive. Pour en savoir plus sur ces limites et découvrir comment accéder à un niveau d'accès supérieur, consultez la documentation de Meta.
Si vous disposez d'un accès au niveau Standard, vous pouvez réduire la valeur du paramètre next_request_delay_sec dans src/Meta/src/raw/pipelines/config.ini pour accélérer les temps de chargement.
Accès à l'API et jeton d'accès
Les étapes suivantes sont requises dans Meta Business Manager et la console pour les développeurs pour importer des données Meta dans Cortex Framework.
- Choisissez une application à utiliser. Vous pouvez créer une application associée au compte d'établissement. Assurez-vous que votre application est de type
Business. - Configurez les autorisations des applications. Vous devez être administrateur de l'application pour pouvoir créer des jetons avec elle. Consultez la documentation sur les rôles d'application. Assurez-vous d'attribuer les composants (comptes) pertinents à votre application.
Créez un jeton d'accès. Les jetons d'accès sont nécessaires pour accéder à l'API Meta Marketing. Ils sont toujours associés à une application et à un utilisateur. Vous pouvez créer le jeton avec un utilisateur système ou avec votre propre identifiant.
- Créez un utilisateur système administrateur.
- Générez un jeton. Veillez à noter votre jeton dès qu'il est généré, car vous ne pourrez plus le récupérer une fois que vous aurez quitté la page.
- Accordez les autorisations
ads_readetbusiness_managementà votre jeton pour accéder aux objets compatibles.
Suivez la documentation Cloud Composer pour activer Secret Manager dans Cloud Composer. Ensuite, créez un secret nommé
cortex_meta_access_tokenet stockez le jeton que vous avez généré à l'étape précédente en tant que contenu.
Fraîcheur des données et délai
En règle générale, la fraîcheur des données pour les sources de données Cortex Framework est limitée par ce que la connexion en amont permet, ainsi que par la fréquence d'exécution de votre DAG. Ajustez la fréquence d'exécution de votre DAG pour l'aligner sur la fréquence en amont, les contraintes de ressources et vos besoins métier.
Avec l'API Meta Marketing, la plupart des données (à l'exception des conversions) sont disponibles en temps quasi réel, bien qu'elles puissent être ajustées jusqu'à 28 jours après l'événement.
Autorisations de connexion Cloud Composer
Créez les connexions suivantes dans Cloud Composer. Pour en savoir plus, consultez la documentation sur la gestion des connexions Airflow.
| Nom de la connexion | Purpose |
meta_raw_dataflow
|
Pour l'API Meta Marketing > Ensemble de données brut BigQuery |
meta_cdc_bq
|
Pour "Ensemble de données brut" > "Transfert d'ensemble de données CDC" |
meta_reporting_bq
|
Pour l'ensemble de données CDC : > Transfert de l'ensemble de données de reporting |
Autorisations du compte de service Cloud Composer
Accordez des autorisations Dataflow au compte de service utilisé dans Cloud Composer (comme configuré dans la connexion meta_raw_dataflow).
Consultez les instructions de la documentation Dataflow. Le compte de service nécessite également l'autorisation Secret Manager Secret Accessor. Pour en savoir plus, consultez la documentation sur le contrôle des accès.
Paramètres de requête
Le répertoire src/Meta/config/request_parameters contient un fichier de spécification de requête API pour chaque entité extraite de l'API Meta Marketing. Chaque fichier de requête contient une liste de champs à extraire de l'API Meta Marketing, un champ par ligne. Pour en savoir plus, consultez la documentation de référence de l'API Meta Marketing.
Paramètres d'ingestion
Contrôlez les pipelines de données Source to Raw et Raw to CDC via les paramètres du fichier src/Meta/config/ingestion_settings.yaml.
Cette section décrit les paramètres de chaque pipeline de données.
Source des tables brutes
Cette section contient des entrées qui contrôlent les entités récupérées par les API et la manière dont elles le sont. Chaque entrée correspond à une entité de l'API Meta Marketing. Sur la base de cette configuration, Cortex Framework crée des DAG Airflow qui exécutent des pipelines Dataflow pour récupérer des données à l'aide des API Meta Marketing.
Le fichier src/Meta/src/raw/pipelines/config.ini contrôle certains comportements du DAG Cloud Composer et la façon dont les API Meta Marketing sont consommées.
Recherchez les descriptions de chaque paramètre dans le fichier.
Les paramètres suivants contrôlent les paramètres de Source to Raw pour chaque entrée:
| Paramètre | Description |
base_table
|
Table de l'ensemble de données brut où les données extraites sont stockées (par exemple, customer).
|
load_frequency
|
Fréquence à laquelle un DAG s'exécute pour extraire des données de Meta. Pour en savoir plus sur les valeurs possibles, consultez la documentation Airflow. |
object_endpoint
|
Chemin d'accès au point de terminaison de l'API (par exemple, campaigns pour le point de terminaison /{account_id}/campaigns).
|
entity_type
|
Type de table (doit être fact, dimension ou addaccount))
|
object_id_column
|
Colonnes (séparées par une virgule) qui forment un enregistrement unique pour cette table. Obligatoire uniquement lorsque entity_type est fact.
|
breakdowns
|
Facultatif:colonnes de répartition (séparées par une virgule) pour les points de terminaison d'insights. Ne s'applique que lorsque entity_type est défini sur fact.
|
action_breakdowns
|
Facultatif:colonnes de répartition des actions (séparées par une virgule) pour les points de terminaison d'insights. Ne s'applique que lorsque entity_type est défini sur fact.
|
partition_details
|
Facultatif:indiquez si vous souhaitez que cette table soit partitionnée pour des raisons de performances. Pour en savoir plus, consultez la section Partitionnement de table. |
cluster_details
|
Facultatif:si vous souhaitez que ce tableau soit regroupé pour des raisons de performances. Pour en savoir plus, consultez la section Paramètres du cluster. |
Tables brutes vers CDC
Cette section décrit les entrées qui contrôlent le transfert de données des tables brutes vers les tables CDC. Chaque entrée correspond à une table brute (qui correspond à l'entité de l'API Meta, comme indiqué).
Les paramètres suivants contrôlent les paramètres de Raw to CDC pour chaque entrée:
| Paramètre | Description |
base_table
|
Table sur laquelle les données brutes ont été répliquées. Une table portant le même nom dans l'ensemble de données CDC stocke les données brutes après la transformation CDC (par exemple, campaign_insights).
|
row_identifiers
|
Colonnes (séparées par une virgule) qui forment un enregistrement unique pour cette table. |
load_frequency
|
Fréquence d'exécution d'un DAG pour cette entité afin de renseigner la table CDC. Pour en savoir plus sur les valeurs possibles, consultez la documentation Airflow. |
partition_details
|
Facultatif:indiquez si vous souhaitez que cette table soit partitionnée pour des raisons de performances. Pour en savoir plus, consultez la section Partitionnement de table. |
cluster_details
|
Facultatif:indiquez si vous souhaitez que ce tableau soit regroupé pour des raisons de performances. Pour en savoir plus, consultez la section Paramètres du cluster. |
Schéma de la table CDC
Pour Meta, tous les champs sont stockés au format chaîne dans la couche brute. Dans la couche CDC, les types primitifs sont convertis en types de données métier pertinents, et tous les types complexes sont stockés au format JSON BigQuery.
Pour activer cette conversion, le répertoire src/Meta/config/table_schema contient un fichier de schéma pour chaque entité spécifiée dans la section raw_to_cdc_tables, qui explique comment traduire correctement chaque table BigQuery brute en table CDC.
Chaque fichier de schéma contient trois colonnes:
SourceField: nom du champ de la table brute de cette entité.TargetField: nom de la colonne dans la table CDC pour cette entité.DataType: type de données de chaque champ de la table cdc.
Paramètres de création de rapports
Vous pouvez configurer et contrôler la façon dont Cortex génère des données pour la couche de reporting finale Meta à l'aide du fichier de paramètres de reporting (src/Meta/config/reporting_settings.yaml). Ce fichier contrôle la génération des objets BigQuery de la couche de reporting (tables, vues, fonctions ou procédures stockées).
Pour en savoir plus, consultez Personnaliser le fichier de paramètres de création de rapports.
Étape suivante
- Pour en savoir plus sur les autres sources de données et charges de travail, consultez la page Sources de données et charges de travail.
- Pour en savoir plus sur les étapes de déploiement dans les environnements de production, consultez la section Conditions préalables au déploiement de Cortex Framework Data Foundation.