Intégration à LiveRamp
Cette page décrit les configurations requises pour importer des données à partir de LiveRamp en tant que source de données de la charge de travail marketing de Cortex Framework Data Foundation.
LiveRamp est une plate-forme de collaboration sur les données qui aide les entreprises à connecter, contrôler et activer leurs données pour améliorer l'expérience client et générer de meilleurs résultats commerciaux. Cortex Framework offre les outils et la plate-forme nécessaires pour l'analyser, le combiner à d'autres sources de données et utiliser l'IA pour obtenir des insights plus détaillés et optimiser votre stratégie marketing.
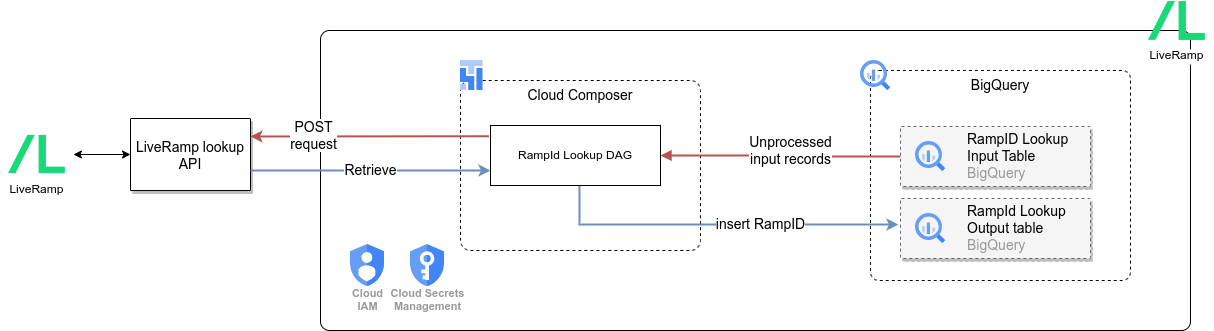
Le diagramme suivant décrit comment la source de données LiveRamp est disponible via la charge de travail marketing de Cortex Framework Data Foundation:
Fichier de configuration
Le fichier config.json configure les paramètres requis pour se connecter aux sources de données afin de transférer des données à partir de diverses charges de travail. Ce fichier contient les paramètres suivants pour LiveRamp:
"marketing": {
"deployLiveRamp": true,
"LiveRamp": {
"datasets": {
"cdc": ""
}
}
}
Le tableau suivant décrit la valeur de chaque paramètre LiveRamp:
| Paramètre | Signification | Valeur par défaut | Description |
marketing.LiveRamp
|
Déployer LiveRamp | true
|
Exécutez le déploiement pour la source de données LiveRamp. |
marketing.LiveRamp.datasets.cdc
|
Ensemble de données CDC pour LiveRamp | Ensemble de données CDC pour LiveRamp |
Connexion à l'API
L'infrastructure de données Cortex Framework permet la résolution d'identité en s'intégrant à LiveRamp.Les frameworks Cortex peuvent effectuer une recherche RampID, ce qui permet aux entreprises d'identifier des audiences ou des segments de clients connus à partir de leurs systèmes CRM.
Le RampID est un identifiant généré par l'API de LiveRamp à l'aide d'informations permettant d'identifier personnellement l'utilisateur (PII), telles que l'adresse e-mail, le numéro de téléphone et le nom. Ce RampID permet aux entreprises d'identifier et de consolider les enregistrements dans plusieurs systèmes, tels que les audiences de différentes campagnes. En s'intégrant à LiveRamp, les entreprises peuvent améliorer leur capacité à identifier et à cibler leurs audiences, ce qui génère des campagnes marketing plus efficaces et personnalisées.
L'API de récupération de la résolution d'identité LiveRamp permet aux entreprises de résoudre de manière programmatique les données permettant d'identifier personnellement les individus. Cortex Framework utilise le point de terminaison de recherche de LiveRamp en envoyant des données d'identité personnelle hachées via l'appel d'API.
Tables d'entrée et de sortie
Après avoir déployé Cortex Framework, le système crée les deux tables BigQuery suivantes dans l'ensemble de données approprié fourni dans config.json.
rampid_lookup_input table
La table rampid_lookup_input est l'entrée du processus de recherche de RampID.
| Colonne | Type de données | Description | Exemple | Clé primaire |
| id | STRING | Identifiant unique de cet enregistrement. | "123" | Oui |
| segment_name | STRING | Nom de l'audience/du CRM/du segment de clients. | "Forte valeur" | Non |
| source_system_name | STRING | Système source d'où provient l'enregistrement. | "Salesforce" | Non |
| nom | STRING | Nom du client | "John Doe" | Non |
| STRING | Adresse e-mail du client | "example@example.com" | Non | |
| phone_number | STRING | Numéro de téléphone du client | "1234567890" | Non |
| postal_code | STRING | Code postal du client | "12345" | Non |
| is_processed | BOOL |
Indique si un enregistrement est déjà traité.
Pour les nouveaux enregistrements, renseignez cette valeur avec "FALSE". Le système définit cette valeur sur "TRUE" une fois le traitement effectué. |
FALSE | Non |
| load_timestamp | TIMESTAMP | Code temporel de l'insertion de l'enregistrement dans le système. Cette information est fournie à des fins d'audit uniquement. | "2020-01-01 00:00:00 UTC" | Non |
| processed_timestamp | TIMESTAMP | Code temporel lorsque le système a effectué une recherche d'API pour cet enregistrement. Cette valeur est toujours renseignée par le système. | "2020-01-01 00:00:00 UTC" | Non |
La table rampid_lookup_input doit être renseignée régulièrement (en fonction de vos besoins commerciaux) avec les informations d'identification personnelle de vos clients, par exemple :
Cortex Framework ne fournit pas de méthode automatisée pour ce faire, mais il fournit un exemple de script ddls/samples/populate_rampid_lookup_input.sql qui montre comment remplir cette table à l'aide des données de votre système Salesforce déjà déployé avec Cortex Framework. Vous pouvez utiliser ce fichier comme guide si vos données proviennent d'un autre système.
Assurez-vous qu'il n'y a pas d'entrées en double dans le tableau rampid_lookup_input (par exemple, la même personne est présente plusieurs fois avec les mêmes informations permettant d'identifier personnellement l'utilisateur, même si son ID peut être différent). Le DAG de recherche Cortex Framework échouerait si un segment contient de nombreuses entrées en double. Cette règle est appliquée par les API LiveRamp.
La table rampid_lookup
La table rampid_lookup est une table de sortie contenant des ID de rampe pour chaque segment de l'enregistrement d'entrée. De par sa conception, LiveRamp ne permet pas de mapper RampID à un enregistrement individuel.
| Colonne | Type de données | Description |
| segment_name | STRING | Nom du segment de la table d'entrée. |
| ramp_id | STRING | RampID LiveRamp |
| code temporel | TIMESTAMP | Code temporel de la recherche de RampID. |
Les RampID LiveRamp peuvent changer au fil du temps pour une même personne. Par conséquent, vous devez effectuer une nouvelle recherche des données déjà traitées de temps en temps. Cortex Framework fournit un exemple de script ddls/samples/clean_up_segment_matching.sql qui montre comment procéder au niveau d'un segment. Vous pouvez ainsi réinitialiser un segment entier. Le système effectuera une recherche pour ce segment et vous fournira les RampID à jour.
rampid_lookup (table de sortie) peut contenir un nombre légèrement inférieur d'enregistrements par rapport à la table d'entrée. Il s'agit d'une conception, car Cortex Framework tente de déboguer les enregistrements d'entrée à l'aide d'informations personnelles pour s'assurer que la recherche dans l'API LiveRamp ne échoue pas.
Authentification du compte
- Contactez LiveRamp pour obtenir des identifiants d'authentification. Cela doit inclure l'ID client et le code secret du client.
Créez un secret à l'aide de Secret Manager avec le nom
cortex-framework-liverampet utilisez la valeur suivante. Consultez les instructions dans la documentation Secret Manager.{ 'client_id':'CLIENT_ID', 'client_secret':'CLIENT_SECRET', 'grant_type':'client_credentials' }Remplacez les éléments suivants :
- CLIENT_ID par l'ID client obtenu à l'étape 1.
- CLIENT_SECRET par le code secret du client obtenu à l'étape 1.
Connexions Cloud Composer
Créez les connexions suivantes dans Cloud Composer. Pour en savoir plus, consultez la documentation sur la gestion des connexions Airflow.
| Nom de la connexion | Purpose |
liveramp_cdc_bq
|
Pour l'API LiveRamp > Transfert d'ensembles de données CDC |
Configuration
Le fichier config.ini contrôle certains comportements du DAG Cloud Composer, ainsi que la façon dont les API LiveRamp sont consommées. Configurez le fichier LiveRamp/src/pipelines/config.ini en fonction de vos besoins. Bien que ces paramètres soient déjà décrits dans le fichier, prêtez attention à liveramp_api_base_url. Par défaut, ce paramètre pointe vers l'URL de l'API de production de LiveRamp. À des fins de test, vous devrez peut-être le rediriger vers la version de préproduction, en fonction de votre configuration.
Étape suivante
- Pour en savoir plus sur les autres sources de données et charges de travail, consultez la page Sources de données et charges de travail.
- Pour en savoir plus sur les étapes de déploiement dans les environnements de production, consultez la section Conditions préalables au déploiement de Cortex Framework Data Foundation.