Integração com o Campaign Manager 360
Esta página descreve as configurações necessárias para trazer dados do Campaign Manager 360 como uma fonte de dados da carga de trabalho de marketing da Cortex Framework Data Foundation.
O Campaign Manager 360 (CM360) é uma plataforma de gerenciamento de publicidade com base na Web oferecida pelo Google especificamente para anunciantes e agências. Ele funciona como um hub central para gerenciar e otimizar todas as suas campanhas de publicidade digital em vários canais. O Cortex Framework fornece as ferramentas e a plataforma para analisar os dados do CM360, combiná-los com dados de outros canais de marketing e usar a IA para ter insights mais aprofundados e otimizar sua estratégia de marketing.
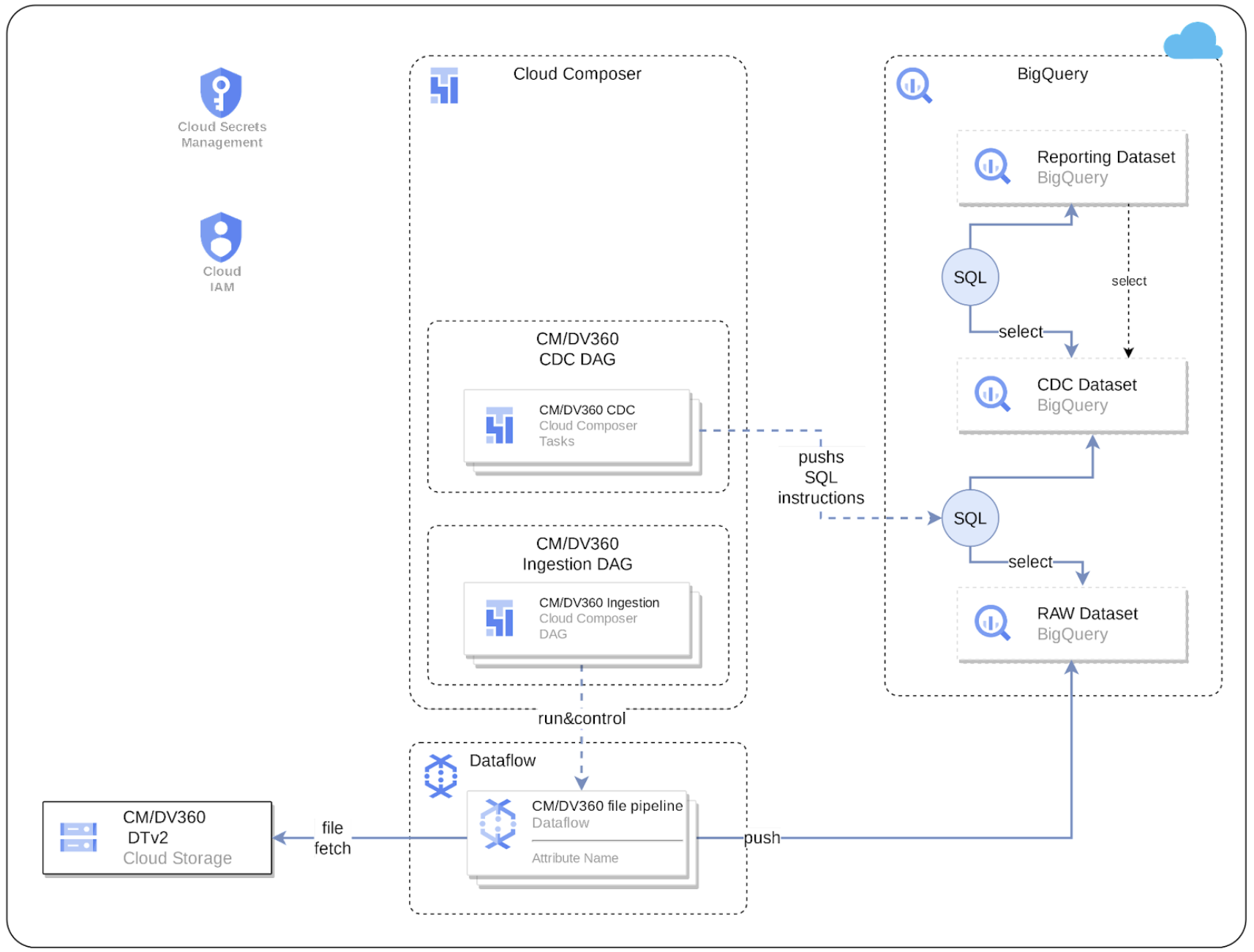
O diagrama a seguir descreve como os dados do CM360 estão disponíveis na carga de trabalho de marketing do Cortex Framework Data Foundation:
Arquivo de configuração
O arquivo config.json
configura as configurações necessárias para se conectar a fontes de dados para transferir
dados de várias cargas de trabalho. Esse arquivo contém os seguintes parâmetros do CM360:
"marketing": {
"deployCM360": true,
}
"CM360": {
"deployCDC": true,
"dataTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_CM360"
}
}
A tabela a seguir descreve o valor de cada parâmetro de marketing:
| Parâmetro | Significado | Valor padrão | Descrição |
marketing.deployCM360
|
Implantar o CM360 | true
|
Execute a implantação para a fonte de dados do CM360. |
marketing.CM360.deployCDC
|
Implantar scripts do CDC para o CM360 | true
|
Gere scripts de processamento do CDC do CM360 para serem executados como DAGs no Cloud Composer. |
marketing.CM360.dataTransferBucket
|
Bucket com resultados do serviço de transferência de dados | - | Bucket em que os arquivos DTv2 são armazenados. |
marketing.CM360.datasets.cdc
|
Conjunto de dados do CDC para o CM360 | Conjunto de dados do CDC para o CM360. | |
marketing.CM360.datasets.raw
|
Conjunto de dados brutos para o CM360 | Conjunto de dados brutos do CM360. | |
marketing.CM360.datasets.reporting
|
Conjunto de dados de relatórios do CM360 | "REPORTING_CM360"
|
Conjunto de dados de relatórios do CM360. |
Modelo de dados
Esta seção descreve o modelo de dados do CM360 usando o diagrama de relacionamento de entidades (ERD, na sigla em inglês).

Visualizações básicas
Esses são os objetos azuis no ERD e são visualizações em tabelas de CDC sem
transformações, exceto alguns aliases de nome de coluna. Consulte os scripts em
src/marketing/src/CM360/src/reporting/ddls.
Visualizações de relatórios
Esses são os objetos verdes no ERD e são visualizações de relatórios que contêm métricas agregadas. Consulte os scripts em
src/marketing/src/CM360/src/reporting/ddls.
Armazenamento de arquivos DTv2
Os arquivos DTv2 (Data Transfer Version 2) são um formato específico usado pelo CM360 para enviar dados de performance da campanha. Configure o processo de transferência de dados seguindo a documentação do Data Transfer V2.0 para usar o CM360 com o Cortex Framework.
Crie ou adicione um bucket do Cloud Storage para armazenar seus arquivos DTv2 do CM360. Verifique se os arquivos no bucket podem ser lidos pela conta de serviço que executa DAGs no Cloud Composer. Para mais informações, consulte Criar buckets de armazenamento.
Atualização e atraso de dados
Como regra geral, a atualidade dos dados para fontes de dados do Cortex Framework é limitada pelo que a conexão upstream permite, bem como pela frequência da execução da DAG. Ajuste a frequência de execução do DAG para alinhá-la à frequência upstream, às restrições de recursos e às necessidades da sua empresa.
Com a Transferência de dados v2 do CM360, os dados de impressões e cliques são enviados 24 vezes por dia (a cada hora). O tempo de processamento pode variar de acordo com o arquivo, então eles podem aparecer fora de ordem. Os arquivos de atividade são enviados diariamente.
Conexões do Cloud Composer
Crie as seguintes conexões no Cloud Composer. Para mais detalhes, consulte a documentação sobre como gerenciar conexões do Airflow.
| Nome da conexão | Purpose |
cm360_raw_dataflow
|
Para arquivos CM360 DTv2 > BigQuery Conjunto de dados bruto |
cm360_cdc_bq
|
Para o conjunto de dados brutos > Transferência de conjunto de dados da CDC |
cm360_reporting_bq
|
Para o conjunto de dados do CDC > Transferência de conjunto de dados de relatórios |
Permissões da conta de serviço do Cloud Composer
Conceda permissões do Dataflow à conta de serviço usada no
Cloud Composer (conforme configurado na conexão cm360_raw_dataflow).
Consulte as instruções na documentação do Dataflow.
Configurações de transferência
Controle os pipelines de dados Source to Raw e Raw to CDC pelas configurações no
arquivo src/CM360/config/ingestion_settings.yaml. Esta seção descreve os parâmetros de cada pipeline de dados.
Origem para tabelas brutas
Esta seção descreve como as entradas que controlam quais arquivos do DTv2 são processados. Cada entrada corresponde a arquivos associados a uma entidade. Com base nessa configuração, o Cortex Framework cria DAGs do Airflow que executam pipelines do Dataflow para processar dados dos arquivos DTv2.
Os parâmetros a seguir controlam as configurações de Source to Raw
para cada entrada:
| Parâmetro | Descrição |
base_table
|
Tabela no conjunto de dados brutos em que os dados de uma entidade são armazenados (por exemplo, dados de "Cliques"). |
load_frequency
|
Com que frequência um DAG dessa entidade é executado para preencher a tabela CDC. Para mais informações sobre os valores possíveis, consulte a documentação do Airflow. |
file_pattern
|
Com base em padrões de nome de arquivo que correspondem a uma entidade. |
schema_file
|
Arquivo de esquema no diretório src/table_schema
que mapeia os campos DTv2 para os nomes das colunas e os tipos de dados da tabela de destino.
|
partition_details
|
Opcional:se você quiser que essa tabela seja particionada por motivos de performance. Para mais informações, consulte Particionamento de tabelas. |
cluster_details
|
Opcional:se você quiser agrupar essa tabela para considerar a performance. Para mais informações, consulte Configurações do cluster. |
De bruto para tabelas de CDC
Esta seção tem entradas que controlam como os dados são movidos de tabelas brutas para tabelas CDC. Cada entrada corresponde a uma tabela bruta, que, por sua vez, corresponde à entidade DTv2, conforme mencionado acima.
Os parâmetros a seguir controlam as configurações de Raw to CDC para cada entrada:
| Parâmetro | Descrição |
base_table
|
Tabela no conjunto de dados da CDC em que os dados brutos
são armazenados após a transformação da CDC (por exemplo, customer).
|
load_frequency
|
Com que frequência um DAG dessa entidade é executado para preencher a tabela CDC. Para mais informações sobre os valores possíveis, consulte a documentação do Airflow. |
row_identifiers
|
Lista de colunas (separadas por vírgulas) que formam um registro exclusivo para essa tabela. |
partition_details
|
Opcional:se você quiser que essa tabela seja particionada por motivos de performance. Para mais informações, consulte Particionamento de tabelas. |
cluster_details
|
Opcional:se você quiser agrupar essa tabela para considerar a performance. Para mais informações, consulte Configurações do cluster. |
Configurações de relatórios
É possível configurar e controlar como o Cortex Framework gera dados
para a camada de relatórios final do CM360 usando o arquivo de configurações de relatórios (src/CM360/config/reporting_settings.yaml).
Esse arquivo controla como os objetos do BigQuery da camada de relatórios
(tabelas, visualizações, funções ou procedimentos armazenados) são gerados.
Para mais informações, consulte Como personalizar o arquivo de configurações de relatórios.
A seguir
- Para mais informações sobre outras fontes de dados e cargas de trabalho, consulte Fontes de dados e cargas de trabalho.
- Para mais informações sobre as etapas de implantação em ambientes de produção, consulte Pré-requisitos de implantação da base de dados do Cortex Framework.