Integración con Campaign Manager 360
En esta página, se describen las configuraciones necesarias para incorporar datos de Campaign Manager 360 como fuente de datos de la carga de trabajo de marketing de Cortex Framework Data Foundation.
Campaign Manager 360 (CM360) es una plataforma de administración de publicidad basada en la Web que ofrece Google y que está diseñada específicamente para anunciantes y agencias. Funciona como un centro central para administrar y optimizar todas tus campañas de publicidad digital en varios canales. Cortex Framework proporciona las herramientas y la plataforma para analizar los datos de CM360, combinarlos con datos de otros canales de marketing y usar la IA para obtener estadísticas más detalladas y optimizar tu estrategia de marketing general.
En el siguiente diagrama, se describe cómo los datos de CM360 están disponibles a través de la carga de trabajo de marketing de Cortex Framework Data Foundation:
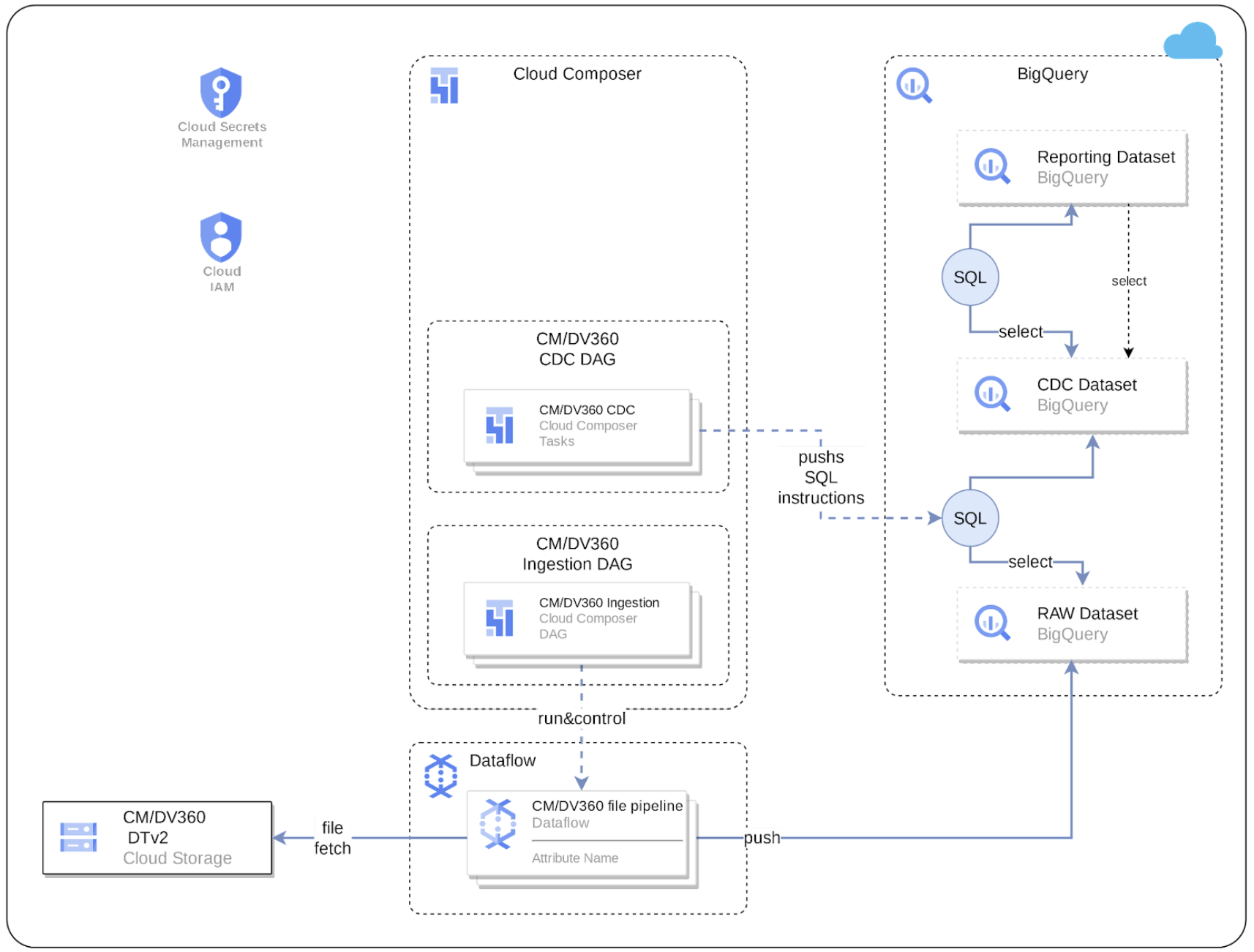
Archivo de configuración
El archivo config.json configura la configuración necesaria para conectarse a fuentes de datos y transferir datos desde varias cargas de trabajo. Este archivo contiene los siguientes parámetros para CM360:
"marketing": {
"deployCM360": true,
}
"CM360": {
"deployCDC": true,
"dataTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_CM360"
}
}
En la siguiente tabla, se describe el valor de cada parámetro de marketing:
| Parámetro | Significado | Valor predeterminado | Descripción |
marketing.deployCM360
|
Implementa CM360 | true
|
Ejecuta la implementación de la fuente de datos de CM360. |
marketing.CM360.deployCDC
|
Implementa secuencias de comandos de CDC para CM360 | true
|
Genera secuencias de comandos de procesamiento de CDC de CM360 para ejecutarlas como DAG en Cloud Composer. |
marketing.CM360.dataTransferBucket
|
Bucket con resultados del Servicio de transferencia de datos | - | Bucket en el que se almacenan los archivos DTv2. |
marketing.CM360.datasets.cdc
|
Conjunto de datos del CDC para CM360 | Conjunto de datos del CDC para CM360. | |
marketing.CM360.datasets.raw
|
Conjunto de datos sin procesar para CM360 | Es un conjunto de datos sin procesar para CM360. | |
marketing.CM360.datasets.reporting
|
Conjunto de datos de informes para CM360 | "REPORTING_CM360"
|
Es el conjunto de datos de informes de CM360. |
Modelo de datos
En esta sección, se describe el modelo de datos de CM360 con el diagrama de relaciones de entidades (ERD).
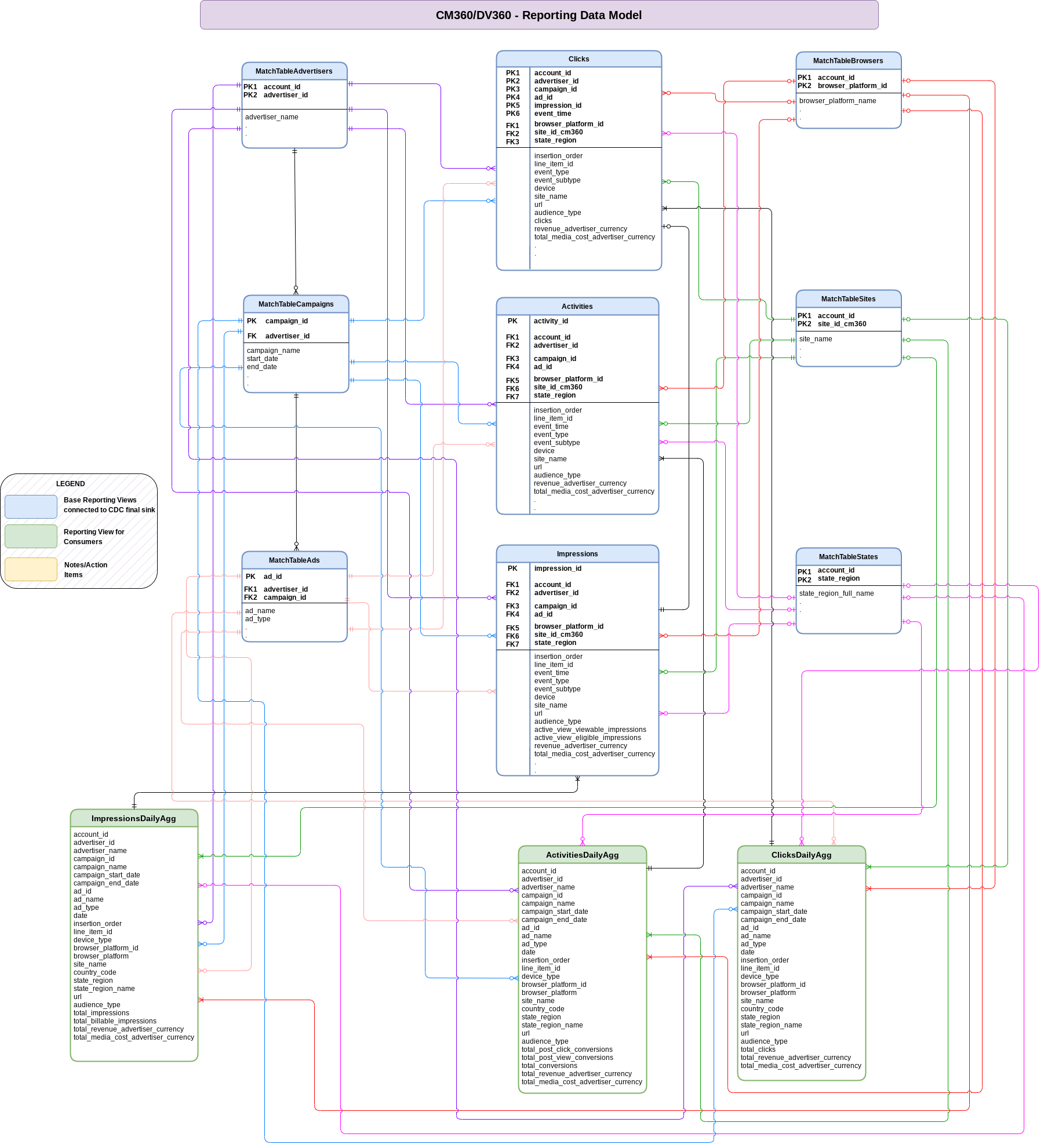
Vistas básicas
Estos son los objetos azules del ERE y son vistas en tablas de CDC sin transformaciones, excepto algunos alias de nombres de columnas. Consulta las secuencias de comandos en src/marketing/src/CM360/src/reporting/ddls.
Vistas de informes
Estos son los objetos verdes del ERE y son vistas de informes que contienen métricas agregadas. Consulta las secuencias de comandos en src/marketing/src/CM360/src/reporting/ddls.
Almacenamiento de archivos DTv2
Los archivos DTv2 (transferencia de datos versión 2) son un formato específico que usa CM360 para proporcionar datos de rendimiento de la campaña. Para usar CM360 con Cortex Framework, configura el proceso de transferencia de datos siguiendo la documentación de Data Transfer V2.0.
Crea o agrega un bucket de Cloud Storage para almacenar tus archivos DTv2 desde CM360. Asegúrate de que la cuenta de servicio que ejecuta los DAG en Cloud Composer pueda leer los archivos del bucket. Para obtener más información, consulta Crea depósitos de almacenamiento.
Actualización y demora de los datos
Como regla general, la actualización de los datos de las fuentes de datos de Cortex Framework se limita a lo que permite la conexión upstream, así como a la frecuencia de la ejecución de tu DAG. Ajusta la frecuencia de ejecución de tu DAG para alinearla con la frecuencia upstream, las restricciones de recursos y las necesidades de tu empresa.
Con la transferencia de datos v2 de CM360, los datos de impresiones y clics se entregan 24 veces al día (por hora). El tiempo de procesamiento puede variar según el archivo, por lo que es posible que los archivos aparezcan desordenados. Los archivos de actividad se entregan a diario.
Conexiones de Cloud Composer
Crea las siguientes conexiones en Cloud Composer. Para obtener más detalles, consulta la documentación sobre cómo administrar las conexiones de Airflow.
| Nombre de la conexión | Purpose |
cm360_raw_dataflow
|
Para archivos DTv2 de CM360, > Conjunto de datos sin procesar de BigQuery |
cm360_cdc_bq
|
Para Conjunto de datos sin procesar > Transferencia de conjuntos de datos de CDC |
cm360_reporting_bq
|
Para el conjunto de datos de los CDC > Transferencia de conjuntos de datos de informes |
Permisos de la cuenta de servicio de Cloud Composer
Otorga permisos de Dataflow a la cuenta de servicio que se usa en
Cloud Composer (como se configuró en la conexión cm360_raw_dataflow).
Consulta las instrucciones en la documentación de Dataflow.
Configuración de transferencia
Controla las canalizaciones de datos de Source to Raw y Raw to CDC a través de la configuración del archivo src/CM360/config/ingestion_settings.yaml. En esta sección, se describen los parámetros de cada canalización de datos.
De fuente a tablas sin procesar
En esta sección, se describe cómo funcionan las entradas que controlan qué archivos de DTv2 se procesan. Cada entrada corresponde a los archivos asociados con una entidad. En función de esta configuración, Cortex Framework crea DAG de Airflow que ejecutan canalizaciones de Dataflow para procesar datos de los archivos DTv2.
Los siguientes parámetros controlan la configuración de Source to Raw para cada entrada:
| Parámetro | Descripción |
base_table
|
Es la tabla del conjunto de datos sin procesar en la que se almacenan los datos de una entidad (por ejemplo, los datos de "Clicks"). |
load_frequency
|
La frecuencia con la que se ejecuta un DAG para esta entidad para propagar la tabla de CDC Para obtener más información sobre los valores posibles, consulta la documentación de Airflow. |
file_pattern
|
Patrones de nombres de archivo basados en entidades |
schema_file
|
Es un archivo de esquema en el directorio src/table_schema que asigna los campos de DTv2 a los nombres de columna y los tipos de datos de la tabla de destino.
|
partition_details
|
Opcional: Si deseas que esta tabla se particione por motivos de rendimiento. Para obtener más información, consulta Partición de tablas. |
cluster_details
|
Opcional: Si deseas que esta tabla se agrupe por motivos de rendimiento. Para obtener más información, consulta Configuración del clúster. |
De tablas sin procesar a tablas de CDC
Esta sección tiene entradas que controlan cómo se mueven los datos de las tablas sin procesar a las tablas de CDC. Cada entrada corresponde a una tabla sin procesar (que, a su vez, corresponde a la entidad DTv2 como se mencionó anteriormente).
Los siguientes parámetros controlan la configuración de Raw to CDC para cada entrada:
| Parámetro | Descripción |
base_table
|
Es la tabla del conjunto de datos de CDC en la que se almacenan los datos sin procesar después de la transformación de CDC (por ejemplo, customer).
|
load_frequency
|
La frecuencia con la que se ejecuta un DAG para esta entidad para propagar la tabla de CDC. Para obtener más información sobre los valores posibles, consulta la documentación de Airflow. |
row_identifiers
|
Es una lista de columnas (separadas por comas) que forman un registro único para esta tabla. |
partition_details
|
Opcional: Si deseas que esta tabla se particione por motivos de rendimiento. Para obtener más información, consulta Partición de tablas. |
cluster_details
|
Opcional: Si deseas que esta tabla se agrupe por motivos de rendimiento. Para obtener más información, consulta Configuración del clúster. |
Configuración de informes
Puedes configurar y controlar cómo Cortex Framework genera datos para la capa de informes final de CM360 con el archivo de configuración de informes (src/CM360/config/reporting_settings.yaml). Este archivo controla cómo se generan los objetos de BigQuery de la capa de informes (tablas, vistas, funciones o procedimientos almacenados).
Para obtener más información, consulta Cómo personalizar el archivo de configuración de informes.
Próximos pasos
- Para obtener más información sobre otras fuentes de datos y cargas de trabajo, consulta Fuentes de datos y cargas de trabajo.
- Para obtener más información sobre los pasos para la implementación en entornos de producción, consulta los requisitos previos para la implementación de Data Foundation de Cortex Framework.