Cloud Composer 1 | Cloud Composer 2 | Cloud Composer 3
Questo tutorial mostra come utilizzare Cloud Composer per creare DAG (Directed Acyclic Graph, DAG, Directed Acyclic Graph) di Apache Airflow che esegue un job di conteggio parole di Apache Hadoop su un Dataproc in un cluster Kubernetes.
Obiettivi
- Accedi al tuo ambiente Cloud Composer e utilizza l'interfaccia utente di Airflow.
- Crea e visualizza le variabili di ambiente Airflow.
- Crea ed esegui un DAG che includa le seguenti attività:
- Crea un cluster Dataproc.
- Esegue un job di conteggio parole di Apache Hadoop sul cluster.
- Restituisce i risultati del conteggio parole a un Cloud Storage di sincronizzare la directory di una VM con un bucket.
- Elimina il cluster.
Costi
In questo documento utilizzi i seguenti componenti fatturabili di Google Cloud:
- Cloud Composer
- Dataproc
- Cloud Storage
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
Assicurati che le seguenti API siano abilitate nel tuo progetto:
Console
Enable the Dataproc, Cloud Storage APIs.
gcloud
Enable the Dataproc, Cloud Storage APIs:
gcloud services enable dataproc.googleapis.com
storage-component.googleapis.com Nel tuo progetto, crea un bucket Cloud Storage di qualsiasi classe e regione di archiviazione per archiviare i risultati del job di conteggio parole di Hadoop.
Prendi nota del percorso del bucket che hai creato, ad esempio
gs://example-bucket. Definirai una variabile Airflow per questo percorso usa la variabile nel DAG di esempio più avanti in questo tutorial.Crea un ambiente Cloud Composer con impostazione predefinita parametri. Attendi il completamento della creazione dell'ambiente. Al termine, viene visualizzato il segno di spunta verde a sinistra del nome dell'ambiente.
Prendi nota della regione in cui hai creato il tuo ambiente, ad esempio
us-central. Definirai una variabile Airflow per questa regione e utilizzarlo nel DAG di esempio per eseguire un cluster Dataproc nella stessa regione.
Imposta variabili Airflow
Impostare le variabili Airflow da utilizzare in seguito nel DAG di esempio. Ad esempio, puoi impostare le variabili Airflow nell'interfaccia utente di Airflow.
| Variabile Airflow | Valore |
|---|---|
gcp_project
|
L'ID progetto del progetto
che stai utilizzando per questo tutorial, ad esempio example-project. |
gcs_bucket
|
L'URI del bucket Cloud Storage che hai creato per questo tutorial,
ad esempio gs://example-bucket |
gce_region
|
La regione in cui hai creato l'ambiente, ad esempio us-central1.
Questa è la regione in cui verrà creato il cluster Dataproc. |
Visualizza il flusso di lavoro di esempio
Un DAG Airflow è una raccolta di attività organizzate che vuoi pianificare
ed eseguirai il deployment. I DAG sono definiti in file Python standard. Il codice mostrato in
hadoop_tutorial.py è il codice del flusso di lavoro.
Flusso d'aria 2
Airflow 1
Operatori
Per orchestrare le tre attività nel flusso di lavoro di esempio, il DAG importa i seguenti tre operatori Airflow:
DataprocClusterCreateOperator: crea un cluster Dataproc.DataProcHadoopOperator: invia un job di conteggio parole di Hadoop e scrive i risultati in un bucket Cloud Storage.DataprocClusterDeleteOperator: elimina il cluster per evitare incorrere in casi gli addebiti continui per Compute Engine.
Dipendenze
Organizzi le attività che vuoi eseguire in modo che riflettano la loro relazioni e dipendenze. Le attività in questo DAG vengono eseguite in sequenza.
Flusso d'aria 2
Airflow 1
Programmazione
Il nome del DAG è composer_hadoop_tutorial e viene eseguito una volta al giorno. Poiché start_date passato a default_dag_args è impostato su yesterday, Cloud Composer pianifica il flusso di lavoro in modo che inizi immediatamente dopo il caricamento del DAG nel bucket dell'ambiente.
Flusso d'aria 2
Flusso d'aria 1
Carica il DAG nel bucket dell'ambiente
Cloud Composer archivia i DAG nella cartella /dags del bucket dell'ambiente.
Per caricare il DAG:
Sul computer locale, salva
hadoop_tutorial.py.Nella console Google Cloud, vai alla pagina Ambienti.
Nell'elenco degli ambienti, nella colonna Cartella DAG per il tuo fai clic sul link DAG.
Fai clic su Carica file.
Seleziona
hadoop_tutorial.pysulla macchina locale e fai clic su Apri.
Cloud Composer aggiunge il DAG ad Airflow e pianifica il DAG automaticamente. Le modifiche ai DAG vengono applicate entro 3-5 minuti.
Esplora le esecuzioni del DAG
Visualizza lo stato dell'attività
Quando carichi il file DAG nella cartella dags/ di Cloud Storage, Cloud Composer analizza il file. Una volta completata correttamente,
del flusso di lavoro viene visualizzato nell'elenco di DAG e il flusso di lavoro è in coda per essere eseguito
immediatamente.
Per visualizzare lo stato dell'attività, vai all'interfaccia web di Airflow e fai clic su DAG nella barra degli strumenti.
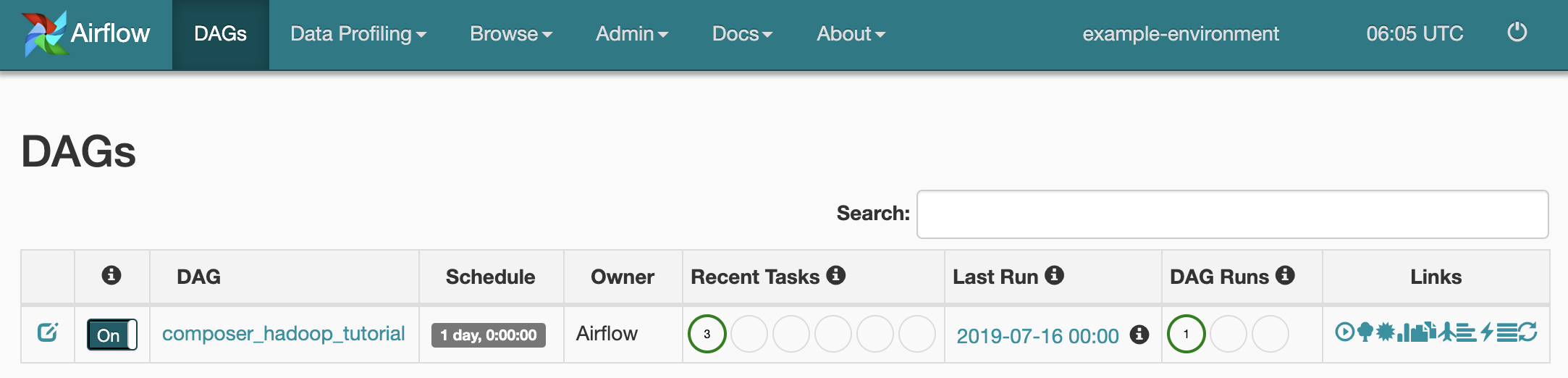
Per aprire la pagina dei dettagli del DAG, fai clic su
composer_hadoop_tutorial. Questa pagina include una rappresentazione grafica delle attività e delle dipendenze del flusso di lavoro.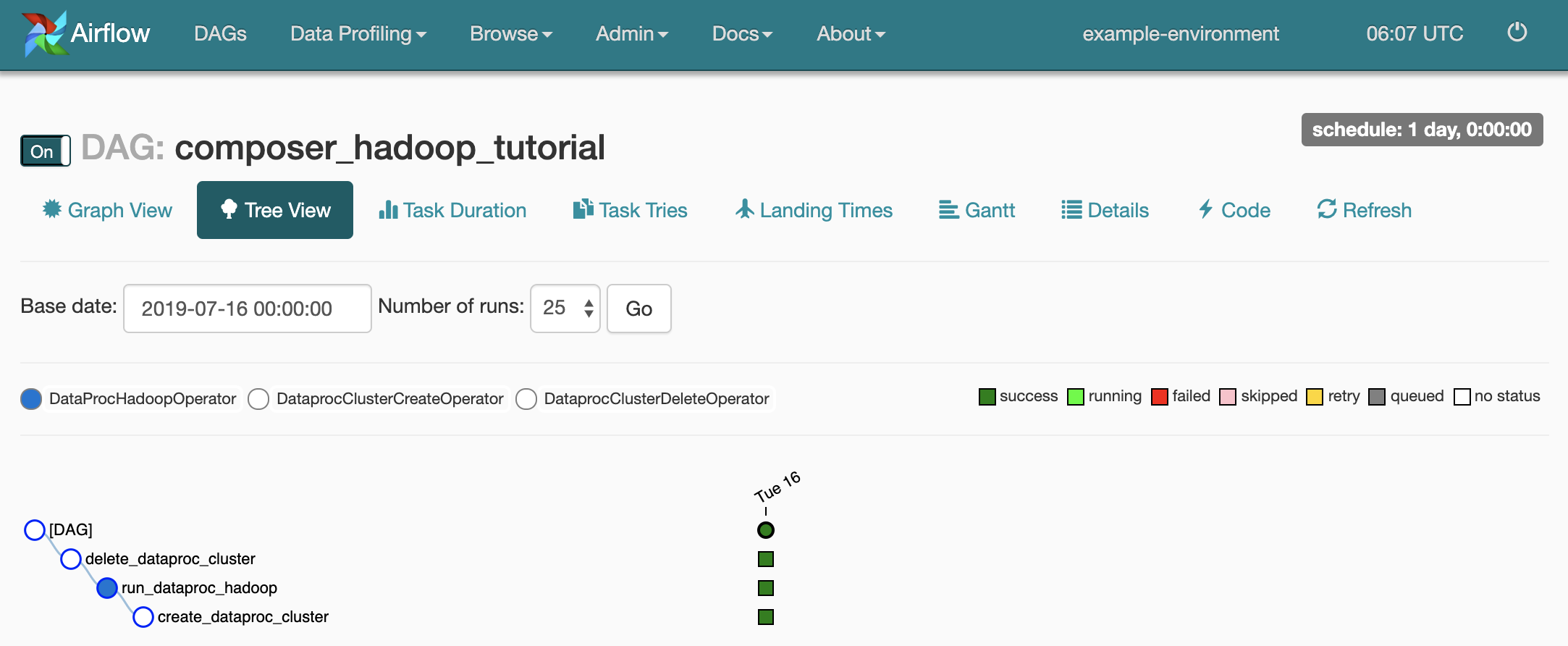
Per visualizzare lo stato di ogni attività, fai clic su Visualizzazione grafico e poi passa il mouse sopra il grafico di ogni attività.
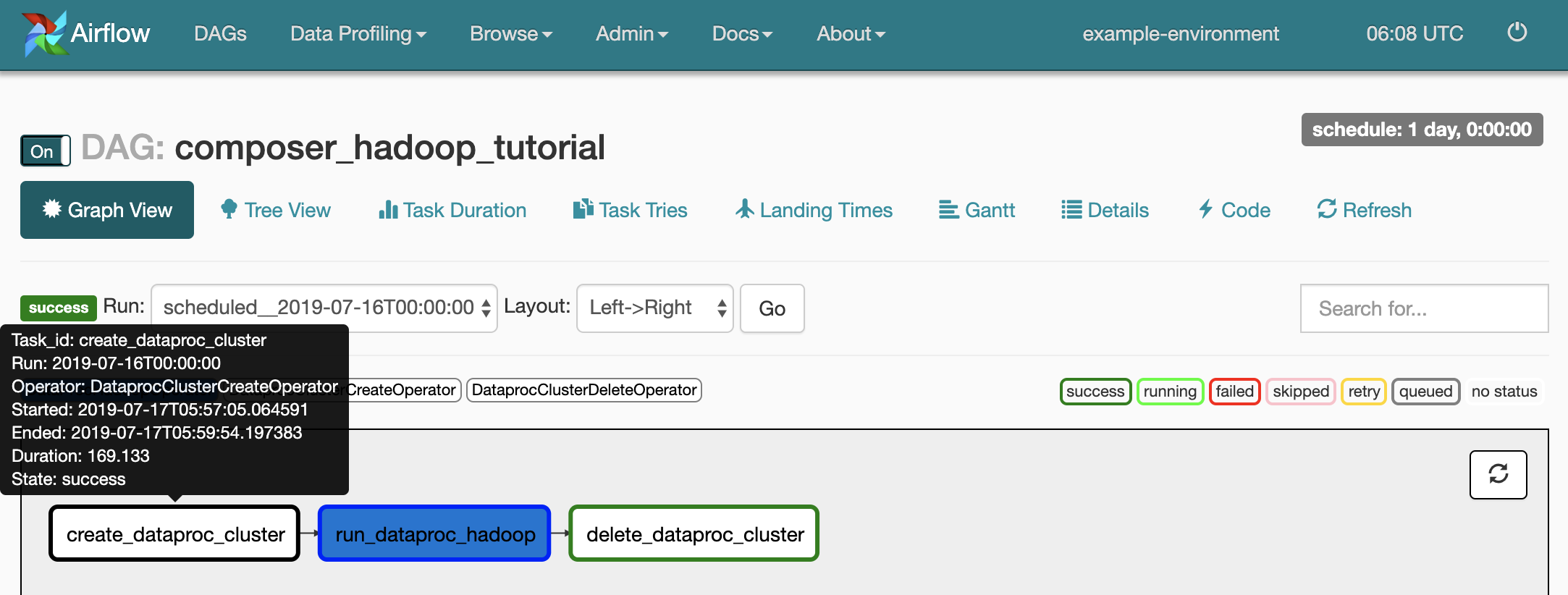
Aggiungi di nuovo il flusso di lavoro in coda
Per eseguire di nuovo il flusso di lavoro dalla visualizzazione Grafico:
- Nella visualizzazione del grafico della UI di Airflow, fai clic sull'immagine
create_dataproc_cluster. - Per reimpostare le tre attività, fai clic su Cancella e poi su OK per confermare.
- Fai di nuovo clic su
create_dataproc_clusterin Visualizzazione grafico. - Per inserire nuovamente il flusso di lavoro in coda, fai clic su Esegui.
Visualizzare i risultati delle attività
Puoi anche controllare lo stato e i risultati del composer_hadoop_tutorial
flusso di lavoro visitando le seguenti pagine della console Google Cloud:
Cluster Dataproc: per monitorare la creazione e l'eliminazione del cluster. Tieni presente che il cluster creato dal flusso di lavoro è temporaneo: esiste solo per la durata del flusso di lavoro e viene eliminato come parte del l'ultima attività di flusso di lavoro.
Job Dataproc: per visualizzare o monitorare il job di conteggio parole di Apache Hadoop. Fai clic sull'ID job per visualizzarne l'output del log.
Browser Cloud Storage: per vedere i risultati del conteggio parole in nella cartella
wordcountnel bucket Cloud Storage che hai creato per questo tutorial.
Esegui la pulizia
Elimina le risorse utilizzate in questo tutorial:
Elimina l'ambiente Cloud Composer, inclusa l'eliminazione manuale del bucket dell'ambiente.
Elimina il bucket Cloud Storage che immagazzina i risultati del job di conteggio parole di Hadoop.