Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
En esta página se describe cómo acceder al panel de monitorización de un entorno de Cloud Composer y cómo usarlo.
Para obtener más información sobre métricas específicas, consulta Monitorizar entornos con Cloud Monitoring.
Acceder al panel de control de monitorización
El panel de control de monitorización contiene métricas y gráficos para monitorizar las tendencias de las ejecuciones de DAGs en tu entorno e identificar problemas con los componentes de Airflow y los recursos de Cloud Composer.
Para acceder al panel de control de monitorización de tu entorno, sigue estos pasos:
En la Google Cloud consola, ve a la página Entornos.
En la lista de entornos, haz clic en el nombre del entorno. Se abrirá la página Detalles del entorno.
Vaya a la pestaña Monitorización.
Configurar alertas de métricas
Para configurar alertas de una métrica, haz clic en el icono de campana situado en la esquina de la tarjeta de monitorización.
Ver una métrica en Monitoring
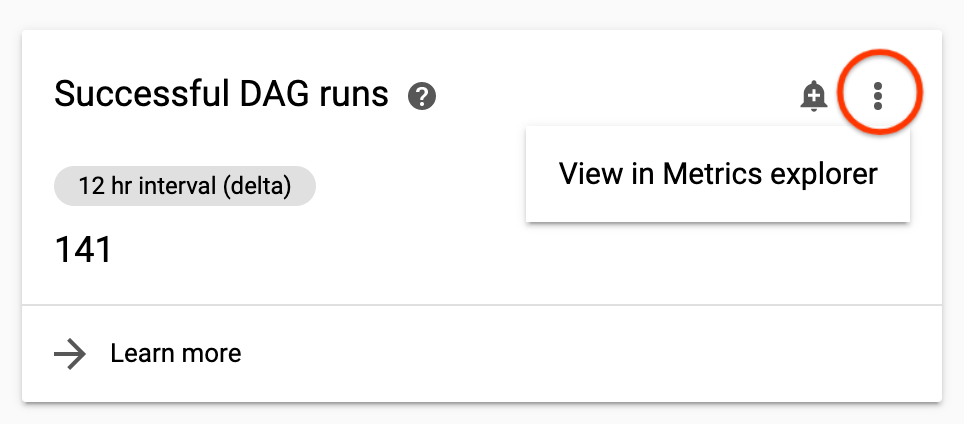
Para ver una métrica con más detalle, puedes consultarla en Monitorización.
Para ir a esa página desde el panel de control de monitorización de Cloud Composer, haz clic en los tres puntos de la esquina superior derecha de una tarjeta de métrica y selecciona Ver en Explorador de métricas.
Descripciones de las métricas
Cada entorno de Cloud Composer tiene su propio panel de control de monitorización. Las métricas que se muestran en un panel de control de monitorización de un entorno concreto solo registran las ejecuciones de DAG, los componentes de Airflow y los detalles del entorno en cuestión. Por ejemplo, si tiene dos entornos, el panel de control no agrega métricas de ambos entornos.
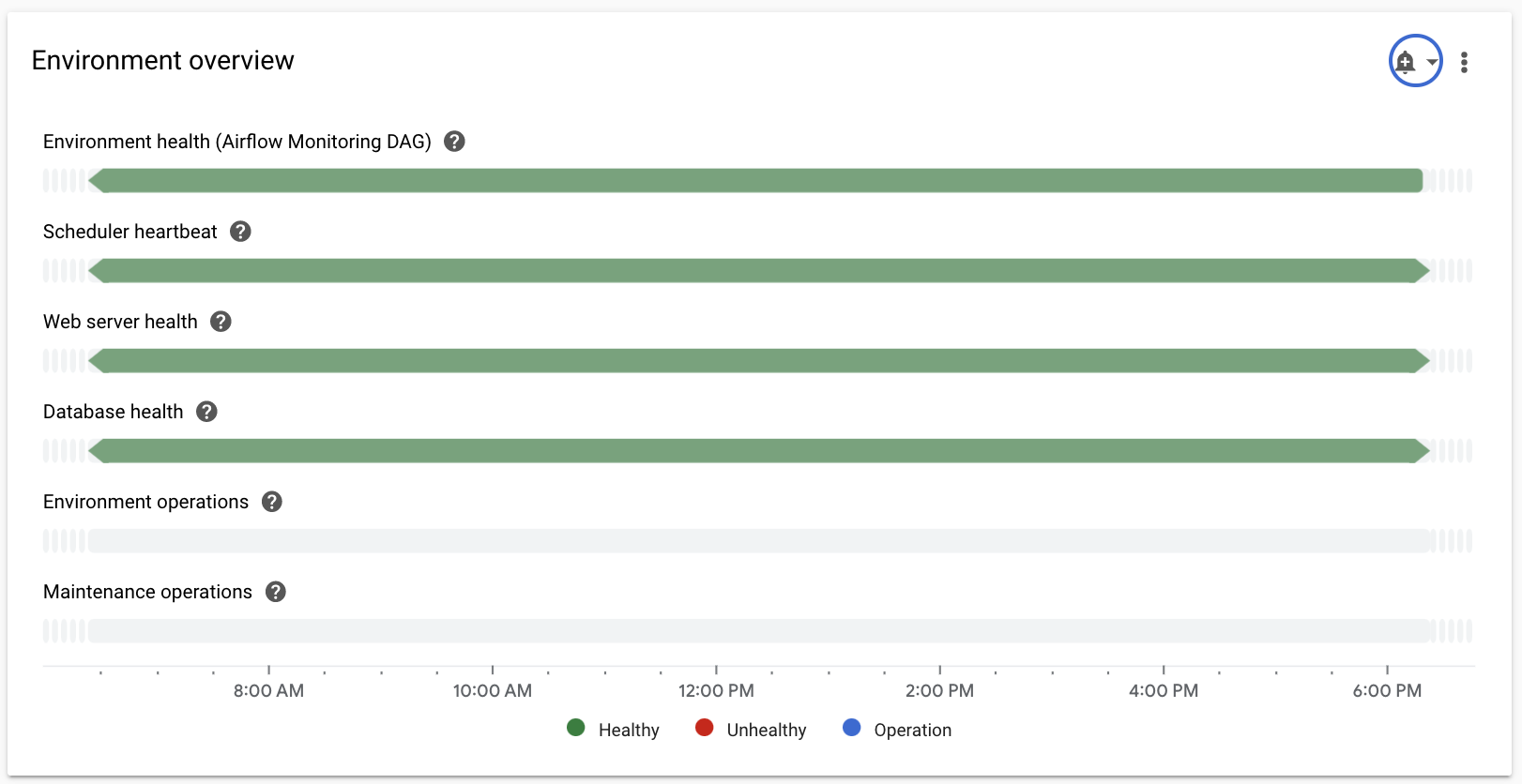
Descripción general del entorno
| Métrica de entorno | Descripción |
|---|---|
| Estado del entorno (DAG de monitorización de Airflow) | Una cronología que muestra el estado de la implementación de Composer. El estado verde solo refleja el estado de la implementación de Composer. Esto no significa que todos los componentes de Airflow estén operativos y que los DAGs se puedan ejecutar. |
| Señal de latido del programador | Una cronología que muestra la señal de latido del programador de Airflow. Comprueba si hay zonas rojas para identificar problemas del programador de Airflow. Si tu entorno tiene más de un programador, el estado de latido será correcto siempre que responda al menos uno de ellos. |
| Estado del servidor web | Una cronología que muestra el estado del servidor web de Airflow. Este estado se genera en función de los códigos de estado HTTP devueltos por el servidor web de Airflow. |
| Estado de la base de datos | Una cronología que muestra el estado de la conexión a la instancia de Cloud SQL que aloja la base de datos de Airflow. |
| Operaciones de entorno | Una cronología que muestra las operaciones que modifican el entorno, como las actualizaciones de configuración o la carga de instantáneas del entorno. |
| Operaciones de mantenimiento | Una cronología que muestra los periodos en los que se realizan operaciones de mantenimiento en el clúster del entorno. |
| Dependencias del entorno | Una cronología que muestra el estado de las comprobaciones de accesibilidad y permisos para el funcionamiento del entorno. |
Estadísticas de DAG
| Métrica de entorno | Descripción |
|---|---|
| Ejecuciones de DAGs completadas | Número total de ejecuciones correctas de todos los DAGs del entorno durante el periodo seleccionado. Si el número de ejecuciones de DAGs que se han completado es inferior al esperado, puede que haya fallos (consulta Ejecuciones de DAGs que han fallado) o un problema de programación. |
| Ejecuciones de DAGs fallidas Tareas fallidas | Número total de ejecuciones fallidas de todos los DAGs del entorno durante el periodo seleccionado. El número total de tareas que han fallado en el entorno durante el periodo seleccionado. Las tareas fallidas no siempre provocan que falle una ejecución de DAG, pero pueden ser una señal útil para solucionar problemas de DAG. |
| Ejecuciones de DAG completadas | Número de éxitos y errores de DAGs en los intervalos del periodo seleccionado. Esto puede ayudar a identificar problemas transitorios con las ejecuciones de DAG y correlacionarlos con otros eventos, como las expulsiones de pods de trabajadores. |
| Tareas completadas | Número de tareas completadas en el entorno, con un desglose de las tareas que se han completado correctamente y de las que han fallado. |
| Duración mediana de ejecución de DAG | Mediana de la duración de las ejecuciones de los DAG. Este gráfico puede ayudar a identificar problemas de rendimiento y detectar tendencias en la duración de los DAG. |
| Tareas de Airflow | Número de tareas que están en ejecución, en cola o aplazadas en un momento dado. Las tareas de Airflow son tareas que están en estado de cola en Airflow. Pueden ir a la cola de intermediación de Celery o de Kubernetes Executor. Las tareas en cola de Celery son instancias de tareas que se colocan en la cola del broker de Celery. |
| Tareas fallidas | Número de tareas inertes que se han terminado en un breve periodo. Las tareas inertes suelen deberse a la finalización externa de los procesos de Airflow. El programador de Airflow termina las tareas inertes periódicamente, lo que se refleja en este gráfico. |
| Tamaño de la bolsa DAG | Número de DAGs implementados en el segmento de tu entorno y procesados por Airflow en un momento dado. Esto puede ser útil al analizar los cuellos de botella del rendimiento. Por ejemplo, un mayor número de implementaciones de DAG puede reducir el rendimiento debido a una carga excesiva. |
| Errores del procesador de DAGs | Número de errores y tiempos de espera por segundo que se han detectado al procesar archivos DAG. El valor indica la frecuencia de los errores notificados por el procesador de DAGs (es un valor diferente al número de DAGs fallidos). |
| Tiempo total de análisis de todos los DAG | Gráfico que muestra el tiempo total que tarda Airflow en procesar todos los DAGs del entorno. El aumento del tiempo de análisis puede afectar a la eficiencia de la programación. Para obtener más información, consulta Diferencia entre el tiempo de análisis y el tiempo de ejecución de un DAG. |
Estadísticas de Scheduler
| Métrica de entorno | Descripción |
|---|---|
| Señal de latido del programador | Consulta la descripción general del entorno. |
| Uso total de CPU del programador | El uso total de núcleos de vCPU por parte de los contenedores que se ejecutan en todos los pods del programador de Airflow y el límite combinado de vCPU de todos los programadores. |
| Uso total de memoria del programador | El uso total de memoria de los contenedores que se ejecutan en todos los pods del programador de Airflow y el límite combinado de vCPUs de todos los programadores. |
| Uso total del disco del programador | Uso total del espacio en disco de los contenedores que se ejecutan en todos los pods del programador de Airflow y límite combinado del espacio en disco de todos los programadores. |
| Reinicios de contenedores del programador | Número total de reinicios de contenedores de programador individuales. |
| Expulsiones de pods de programador | Número de expulsiones de pods del programador de Airflow. La expulsión de pods puede producirse cuando un pod concreto del clúster de tu entorno alcanza sus límites de recursos. |
Estadísticas de los trabajadores
| Métrica de entorno | Descripción |
|---|---|
| Uso total de CPU de los trabajadores | Uso total de los núcleos de vCPU por parte de los contenedores que se ejecutan en todos los pods de trabajador de Airflow y el límite combinado de vCPU de todos los trabajadores. |
| Uso total de memoria de los trabajadores | El uso total de memoria de los contenedores que se ejecutan en todos los pods de trabajadores de Airflow y el límite combinado de vCPUs de todos los trabajadores. |
| Uso total del disco de los trabajadores | El uso total del espacio en disco de los contenedores que se ejecutan en todos los pods de trabajadores de Airflow y el límite de espacio en disco combinado de todos los trabajadores. |
| Trabajadores activos | El número actual de trabajadores de tu entorno. En Cloud Composer 2, el entorno escala automáticamente el número de trabajadores activos. |
| Reinicios de contenedores de trabajo | Número total de reinicios de contenedores de trabajadores individuales. |
| Pods de trabajadores expulsados | Número de expulsiones de pods de trabajadores de Airflow. La expulsión de pods puede producirse cuando un pod concreto del clúster de tu entorno alcanza sus límites de recursos. Si se expulsa un pod de trabajador de Airflow, se interrumpirán todas las instancias de tareas que se estén ejecutando en ese pod y, más adelante, Airflow las marcará como fallidas. |
| Tareas de Airflow | Consulta la descripción general del entorno. |
| Tareas de Celery no confirmadas |
Número de tareas no confirmadas en la cola del broker de Celery. Las tareas no confirmadas incluyen instancias de tareas de Airflow en los estados de tarea queued y running. Ambos estados son normales en la ejecución de las tareas de Airflow. El gráfico de tareas de Celery no confirmadas mostrará las tareas en estos estados como no confirmadas mientras Airflow las procesa. Si una instancia de tarea de Airflow se interrumpe de forma anormal (por ejemplo, se detecta como zombi), también permanecerá sin confirmar hasta que se alcance el valor de visibility_timeout. En este caso, el gráfico mostrará una tarea que permanece sin confirmar durante mucho tiempo. El valor de tiempo de espera de visibilidad se ha definido en 7 días en Cloud Composer. Transcurrido ese periodo, la tarea se volverá a enviar y se podrá confirmar. Si vuelve a fallar, es posible que no se confirme durante otros 7 días. |
| Tiempos de espera de publicación del broker de Celery |
Número total de errores de AirflowTaskTimeout que se han producido al publicar tareas en Celery Brokers. Esta métrica se corresponde con la métrica celery.task_timeout_error de Airflow. |
| Errores de ejecución de comandos de Celery |
Número total de códigos de salida distintos de cero de las tareas de Celery. Esta métrica se corresponde con la métrica celery.execute_command.failure de Airflow. |
| Tareas finalizadas por el sistema | Número de tareas de flujo de trabajo en las que se ha terminado el ejecutor de tareas con SIGKILL (por ejemplo, debido a problemas de memoria o de latido de los trabajadores). |
Estadísticas de activadores
| Métrica de entorno | Descripción |
|---|---|
| Tareas aplazadas | Número de tareas que están en el estado Aplazada en un momento dado. Para obtener más información sobre las tareas diferidas, consulta Usar operadores diferibles. |
| Activadores completados | Número de activadores completados en todos los pods de activadores. |
| Ejecutar activadores | Número de activadores que se ejecutan por instancia de activador. En este gráfico se muestran líneas independientes para cada activador. |
| Activadores de bloqueo | Número de activadores que han bloqueado el hilo principal (probablemente porque no son totalmente asíncronos). |
| Uso total de CPU de los activadores | El uso total de los núcleos de vCPU por parte de los contenedores que se ejecutan en todos los pods de activadores de Airflow y el límite combinado de vCPU de todos los activadores. |
| Uso de memoria total de los activadores | El uso total de memoria de los contenedores que se ejecutan en todos los pods de activadores de Airflow y el límite combinado de vCPUs de todos los activadores. |
| Uso del disco de los activadores totales | Uso total del espacio en disco de los contenedores que se ejecutan en todos los pods de activadores de Airflow y límite combinado del espacio en disco de todos los activadores. |
| Activadores activos | Número de instancias de activador activas. |
| Reinicios de contenedores de activadores | Número de reinicios del contenedor activador. |
Estadísticas del servidor web
| Métrica de entorno | Descripción |
|---|---|
| Estado del servidor web | Consulta la descripción general del entorno. |
| Uso de CPU del servidor web | El uso total de núcleos de vCPU por parte de los contenedores que se ejecutan en todos los pods del servidor web de Airflow y el límite combinado de vCPU de todos los servidores web. |
| Uso de memoria del servidor web | El uso total de memoria de los contenedores que se ejecutan en todos los pods del servidor web de Airflow y el límite combinado de vCPUs de todos los servidores web. |
| Uso total del espacio en disco del servidor web | Uso total del espacio en disco de los contenedores que se ejecutan en todos los pods del servidor web de Airflow y límite combinado del espacio en disco de todos los servidores web. |
Estadísticas de bases de datos SQL
| Métrica de entorno | Descripción |
|---|---|
| Estado de la base de datos | Consulta la descripción general del entorno. |
| Uso de CPU de la base de datos | El uso de núcleos de CPU por parte de las instancias de base de datos de Cloud SQL de tu entorno. |
| Uso de memoria de la base de datos | El uso total de memoria de las instancias de base de datos de Cloud SQL de tu entorno. |
| Uso del disco de la base de datos | El uso total del espacio en disco de las instancias de base de datos de Cloud SQL de tu entorno. Esta métrica se aplica a la propia instancia de base de datos de Cloud SQL, por lo que no disminuye cuando se reduce el tamaño de la base de datos de Airflow. Para ver una métrica que muestre el tamaño del contenido de la base de datos de Airflow, consulta Tamaño de la base de datos de metadatos de Airflow. |
| Tamaño de la base de datos de metadatos de Airflow | Tamaño de la base de datos de metadatos de Airflow. Esta métrica se aplica al componente Airflow de tu entorno y muestra la cantidad de espacio en disco que ocupa la base de datos de metadatos de Airflow en la instancia de base de datos de Cloud SQL. Esta métrica disminuye cuando se reduce el tamaño de la base de datos de metadatos de Airflow (por ejemplo, después del mantenimiento de la base de datos de Airflow) y determina si es posible crear instantáneas y actualizar entornos. Esta métrica es diferente de la métrica Uso de disco de la base de datos, que muestra la cantidad de espacio en disco que usan las instancias de base de datos de Cloud SQL. |
| Conexiones de bases de datos | El número total de conexiones activas a la base de datos y el límite total de conexiones. |
Diferencia entre el tiempo de análisis de DAG y el tiempo de ejecución de DAG
En el panel de control de monitorización de un entorno se muestra el tiempo total necesario para analizar todos los DAG de tu entorno de Cloud Composer y el tiempo medio que se tarda en ejecutar un DAG.
El programador de Airflow realiza dos operaciones independientes: analizar un DAG y programar tareas de un DAG para su ejecución.
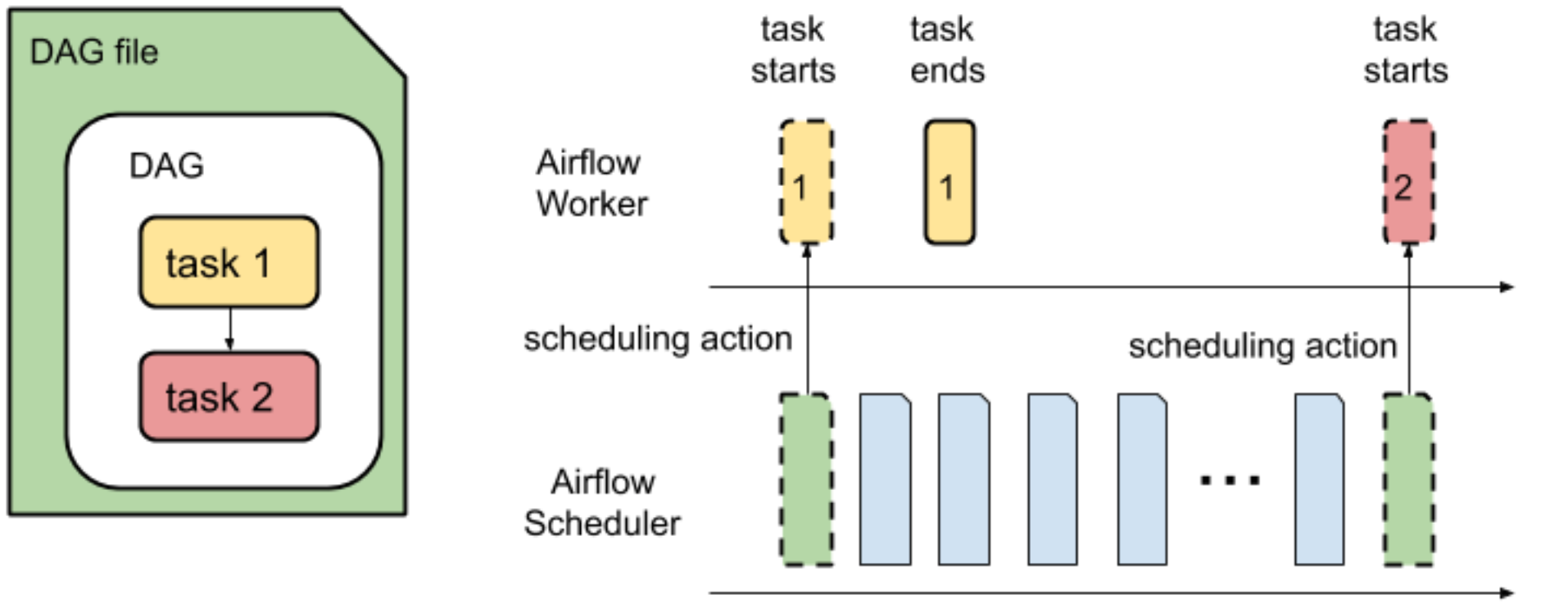
El tiempo de análisis de DAG es el tiempo que tarda el programador de Airflow en leer y analizar un archivo DAG.
Para que el programador de Airflow pueda programar cualquier tarea de un DAG, debe analizar el archivo de DAG para descubrir la estructura del DAG y las tareas definidas. Una vez analizado el archivo DAG, el programador puede empezar a programar tareas del DAG.
El tiempo de ejecución de un DAG es la suma de los tiempos de ejecución de todas las tareas de un DAG.
Para ver cuánto tiempo tarda en ejecutarse una tarea de Airflow concreta de un DAG, en la interfaz web de Airflow, selecciona un DAG y abre la pestaña Duración de la tarea. En esta pestaña se muestran los tiempos de ejecución de las tareas de los últimos DAGs.