| title | description | author | tags | date_published |
|---|---|---|---|---|
Horizontally scale a MySQL database backend with Cloud SQL and ProxySQL |
Learn how to horizontally scale a MySQL database backend with Cloud SQL and ProxySQL. |
michaelawyu |
MySQL, Cloud SQL, Database, ProxySQL |
2018-01-12 |
Chen Yu | Developer Programs Engineer | Google
Contributed by Google employees.
This tutorial explains how to horizontally scale the MySQL database backend of your application using Cloud SQL and ProxySQL.
Cloud SQL is a fully managed database service that makes it easy to set up, maintain, manage, and administer your relational PostgreSQL and MySQL databases in the cloud. Cloud SQL offers high performance, scalability, and convenience. Hosted on Google Cloud, Cloud SQL provides a database infrastructure for applications running anywhere.
ProxySQL is an open-source, high-performance MySQL proxy capable of routing database queries in a MySQL database cluster. ProxySQL, with proper configuration, allows you to dynamically scale MySQL database backend without modifying application logic.
This tutorial assumes that you have set up an application, such as a Django or Flask app or a WordPress blog, using a MySQL database as the database backend. The application itself does not need to run on Google Cloud, though deploying both your application and the database backend in the same region of Google Cloud may greatly improve performance. For options for running your application on Google Cloud, see Cloud Compute Products.
- Create a Cloud SQL for MySQL instance.
- Install ProxySQL.
- Configure ProxySQL to connect to Cloud SQL.
- Configure your application to use ProxySQL.
- Create two read replicas for your Cloud SQL instance.
- Configure ProxySQL to distribute queries to read replicas.
This tutorial uses billable components of Google Cloud, including Cloud SQL.
Use the Pricing Calculator to generate a cost estimate based on your projected usage.
-
Select a project from the Cloud Console.
If you have never used Google Cloud before, sign up or log in with your existing Google account, then follow the on-screen instructions to start using Google Cloud.
-
Enable billing for your account.
-
(Optional) Install the Cloud SDK.
For a small scale application, it is usually fine to deploy its database backend on a single server, sometimes even the same server running the application itself. However, as the number of users continues to grow, developers often find it increasingly difficult to accommodate all the requests efficiently with one machine, for either practical or economical reasons. Consequently, instead of deploying the database backend on one powerful instance, an application of larger scale often use a cluster of less capable machines together to run the database backend, which is known as horizontal scaling of database backend. There are many advantages in scaling your database backend horizontally. It allows you to dynamically resize the database backend, so you may add or remove computational capacity as you see fit without having to take the application offline. It also largely removes the limit to how many resources you can allocate to your database backend, and saves the work of configuring the database management system to utilize additional resources. This is not saying that horizontal scaling is a perfect solution though; many challenges, such as keeping the data synchronized, protecting data integrity and making the database backend highly available, still exist and require special attention when you are scaling your database backend horizontally. Common approaches for horizontally scaling include sharding and master/slave replication. In this tutorial you will implement a database backend with master/slave replication only, though it is also possible to shard with Cloud SQL and ProxySQL.
Sharding makes horizontal scaling possible by partitioning the database into smaller, more manageable parts (shards), then deploying the parts across a cluster of machines. Data queries are routed to the corresponding server automatically, usually with rules embedded in application logic or a query router.

Master/slave replication is another common approach for scaling horizontally. In this scheme, a database server cluster consists of one master instance and a group of slave instances. Both types store the same set of data and accept read requests, however, only the master instance is capable of handling write operations. Any change to the data is directed to the master instance and later propagated to the slave instances under the supervision of the master instance.
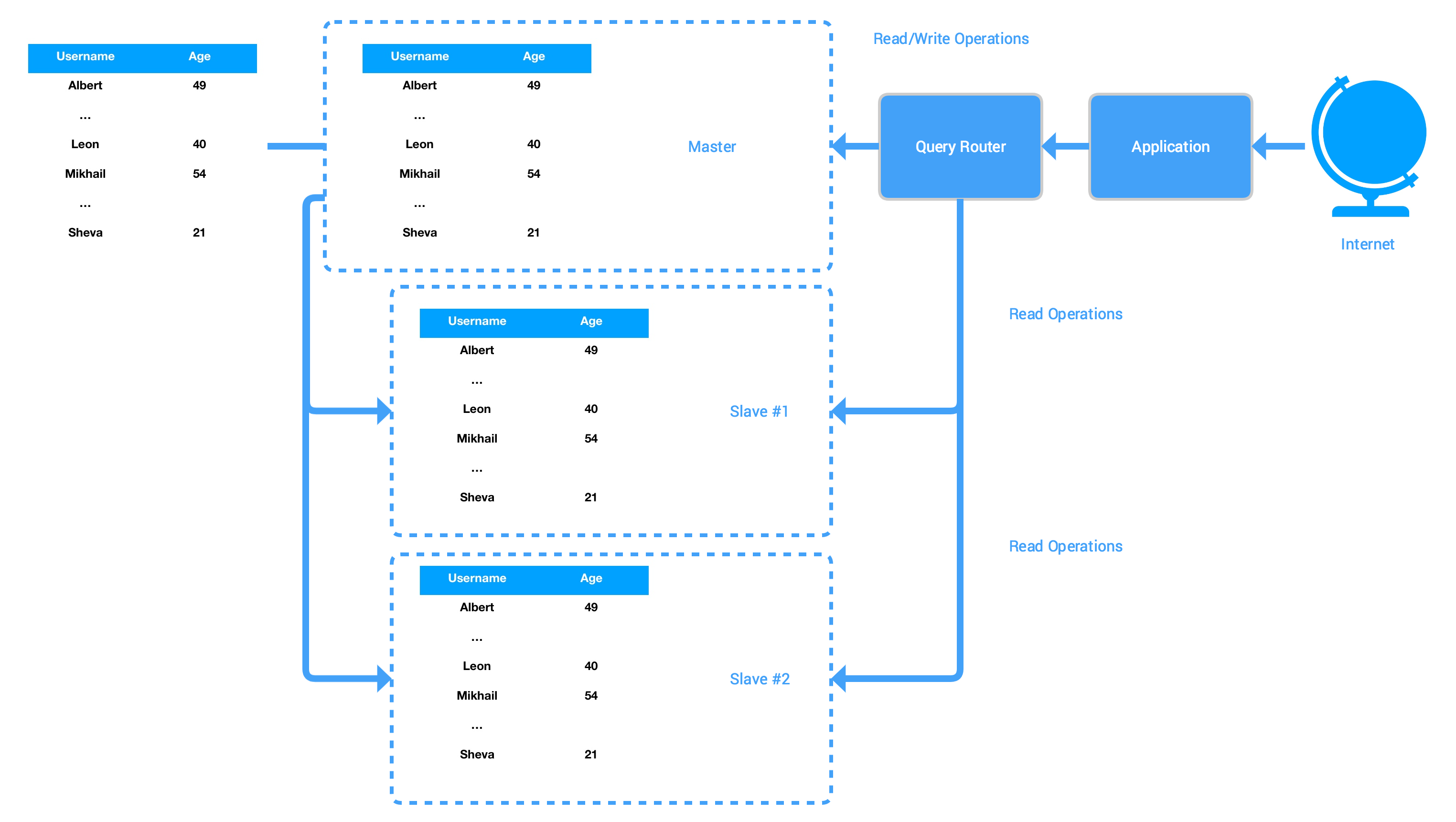
This tutorial uses Cloud SQL and ProxySQL to build a scalable database backend with master/slave replication. Properly configured, this architecture should greatly improve the performance of your database backend, especially in terms of read operations.
At a basic level, the architecture of the project looks as follows:

In this project, Cloud SQL hosts the database backend of your application, which consists of one master instance and two read replicas (slave instances). You may add or remove replicas dynamically at any time. Your application receives requests from the Internet as usual and sends read/write requests to ProxySQL as if ProxySQL is one single database server; ProxySQL stores a list of rules for routing queries and distributes the queries to the master instance and the read replicas accordingly. After the Cloud SQL instances complete the queries, the results are returned to the application via ProxySQL. All the updates are applied on the master instance and replicated to the read replicas automatically.
In this tutorial ProxySQL runs in the same server as the application; for best performance, you may want to run ProxySQL on a separate machine.
This tutorial assumes that your application is read-intensive, and it is OK that some of your users may not be able to see the latest update immediately (as it takes time to propagate changes from the master to slaves). However, if your application writes data much more frequently than it reads data, or it is critical that every user of your application should be able to see the latest changes as soon as they are available, this architecture may not be optimal.
The following steps use the Cloud Console to create a Cloud SQL for MySQL instance. You can also create an instance with the Cloud SDK or using the Cloud SQL API.
-
Go to the Cloud SQL instances page of the Cloud Console and click Create instance.
-
Choose
MySQLas the database engine andSecond Generationas the instance type. -
Enter an instance ID and set the root password.
-
Choose the location of your Cloud SQL instance.
The values set here determine where your data is stored. Though you may deploy the instance at any location you like, generally speaking it is best to pick a location as close as possible to where your application runs. For example, if your application is also running on Google Cloud, it is recommended that you deploy the Cloud SQL instance in the same region and zone as your application.
By default Cloud SQL creates an instance using one CPU core, 3.75 GB of memory, and 10 GB of SSD storage. Depending on the scale of your database backend, you may need to use a more powerful machine type and further increase the storage capacity. Click Show configuration options to update those settings. It is also possible to upgrade (or downgrade) after deployment.
-
Click Create.
See Importing data into Cloud SQL for instructions on migrating data from external sources to Cloud SQL.
Download the ProxySQL package for your environment here and use your system's package manager to install it. For example, if you are running your application on a Compute Engine instance with Debian 9, follow the steps below:
-
Connect to your Compute Engine instance.
The following steps should be executed on your Compute Engine instance.
-
Download the package:
wget https://github.com/sysown/proxysql/releases/download/v1.4.4/proxysql_1.4.4-debian9_amd64.deb -
Install the package:
dpkg -i proxysql_1.4.4-debian9_amd64.deb -
Start ProxySQL:
sudo service proxysql start -
Check the version of ProxySQL:
proxysql --versionYou should see a line of output similar to this:
ProxySQL version 1.4.4-139-ga51b040, codename Truls
Before using ProxySQL to connect to the Cloud SQL instance you just created, you have to authorize the network your application resides in with Cloud SQL:
-
Find the IP address of the system running your application.
If you are using Compute Engine, the external IP address of your instance is listed in the VM instances page of the Cloud Console.
For applications running on other cloud platforms, refer to their documentation for instructions.
Alternatively, you can use third-party websites, such as ifconfig.me, to get the IP address of your application server:
curl ifconfig.me -
Go to the Cloud SQL instances page in the Cloud Console. Click the ID of the instance you just created.
-
On the Instance details page, select the Authorization tab. Under Authorized Networks, click Add network.
-
Enter the name of the new authorized network (optional) and the IP address of your application server.
-
Click Done. Then click Save to save the changes.
ProxySQL provides a MySQL-compatible interface for configurations. After successfully installing ProxySQL on your system, log into the admin interface:
mysql -u admin -padmin -h 127.0.0.1 -P6032 --prompt='proxysql> '
You should see the proxysql> prompt after running the command.
Follow the steps below to add your Cloud SQL instance as a backend MySQL server in ProxySQL:
-
Go to the Cloud SQL instances page and click the ID of the instance you created. From the Instance details page, write down the IPv4 address listed under Connect to this instance.
-
In the ProxySQL admin interface, run the SQL query:
INSERT INTO mysql_servers (hostname) VALUES ('[IP_ADDRESS]');Replace
[IP_ADDRESS]with the IPv4 address of your Cloud SQL instance. -
Changes made via ProxySQL admin interface are stored in an in-memory database and do not take effect automatically. Run the commands below to bring the new changes into effect and save them to the disk:
LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; -
Add the user credentials for connecting with this SQL query:
INSERT INTO mysql_users(username, password) VALUES (‘[USERNAME]’,’[PASSWORD]’);Replace
[USERNAME]and[PASSWORD]with the username and password of your Cloud SQL instance respectively. You may use the default userrootand the root password you set when creating the Cloud SQL instance. For better security, create a new user with proper privileges and hostname restrictions. See Creating and managing MySQL users and MySQL users for more information. -
Similarly, load the new user into runtime and save it to disk:
LOAD MYSQL USERS TO RUNTIME; SAVE MYSQL USERS TO DISK;
ProxySQL periodically checks all the configured MySQL servers. To set up monitoring, create a new user in your Cloud SQL instance and update the settings in ProxySQL admin interface:
SET mysql-monitor_username = '[USERNAME]';
SET mysql-monitor_password = '[PASSWORD]';
Replace [USERNAME] and [PASSWORD] with the values of your own.
If you would like to disable monitoring, run the following command in ProxySQL admin interface:
SET mysql-monitor_enabled = 'false';
After making changes, save the settings:
LOAD MYSQL VARIABLES TO RUNTIME;
SAVE MYSQL VARIABLES TO DISK;
See ProxySQL documentation for more information on monitoring.
In this tutorial, ProxySQL is installed in the same server as your application
and accepts connection at 127.0.0.1, port 6033. Update the database
configuration of your application accordingly to start using ProxySQL as a query
router. Currently, since there is only one database server listed in ProxySQL,
all the queries are routed there.
The following steps use Cloud Console to create a Cloud SQL read replica. You can also create a read replica via Cloud SDK or using the Cloud SQL API.
- Go to the Cloud SQL Instances page in the Cloud Console. Click the ID of the instance you just created. Select the Replicas tab.
- Click Create read replica. Enter an Instance ID and pick a location for the replica. If you would like to, click Show configuration options to give the replica a different machine type and storage solution from the master instance. Settings such as authorized networks are inherited from the master instance, though you can still change them specifically for the read replica.
- Click Create. It may take a while to create the instance and replicate the data.
- After the read replica comes online, click its name and write down the IPv4 address in the Connect to this instance card of its instance details page.
- Repeat the steps once to create another read replica. Write down its IPv4 address as well.
For more information about Cloud SQL read replicas, see Replication in Cloud SQL.
In the ProxySQL admin interface, run the following SQL queries:
INSERT INTO mysql_servers (hostgroup_id, hostname) VALUES ('1', '[IP_ADDRESS_#1]'), ('1', '[IP_ADDRESS_#2]')
LOAD MYSQL SERVERS TO RUNTIME
SAVE MYSQL SERVERS TO DISK
Replace [IP_ADDRESS_#1] and [IP_ADDRESS_#2] with the IPv4 addresses of the
two read replicas you just created. Note that the replicas are assigned to a
different group (1) from the master instance (0).
The steps below set a simple list of rules that distribute all write traffic and 20% read traffic to the master instance, 40% read traffic to the first read replica and another 40% read traffic to the second read replica. It is based on the sample rules in ProxySQL wiki. Those rules are for demonstration purposes only and may not suit the performance requirements of your particular application. Allocate different weights to read replicas as you experiment with other query routing functionalities (regex, digest, etc.) provided in ProxySQL to create context-sensitive rules for better query distribution.
-
Declare rules with the following SQL queries:
INSERT INTO mysql_query_rules (rule_id, active, match_digest, destination_hostgroup, apply) VALUES (1,1,'^SELECT.*FOR UPDATE',0,1), (2,1,'^SELECT',1,1); LOAD MYSQL RULES TO RUNTIME; SAVE MYSQL RULES TO DISK;The queries add two rules:
- Distribute all of the
SELECT … FOR UPDATEqueries to database servers in host group 0 - Distribute all of the
SELECTqueries to database servers in host group 1
Queries that do not match any existing rules go to database servers in host group 0 (default).
- Distribute all of the
-
Add the master instance to host group
1so that it also helps serve read traffic:INSERT INTO mysql_servers (hostgroup_id, hostname) VALUES (1, '[IP_ADDRESS]'); LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; -
Adjust the weights of servers in host group
1:UPDATE mysql_servers SET weight = 40 WHERE hostname = '[IP_ADDRESS_1]'; UPDATE mysql_servers SET weight = 40 WHERE hostname = '[IP_ADDRESS_2]'; UPDATE mysql_servers SET weight = 20 WHERE hostname = '[IP_ADDRESS]'; LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK;Replace
[IP_ADDRESS_1],[IP_ADDRESS_2], and[IP_ADDRESS]with the IP addresses of read replica #1, read replica #2, and the master instance respectively. The weights are calculated as follows:P(server # receives the query) = (weight of server #) / (total weight of the host group)
Read replica #1 has a weight of 40, so its chance of receiving a query is 40/100 = 0.4 (40%). Similarly, read replica #2 has a chance of 40% and the master instance 20%.
You can add or remove read replicas any time you want. When you are adding a
read replica, create it in Cloud SQL as instructed above, add it to the
mysql_server table, and update the rules (and/or weights) to route traffic to
it. Removing a read replica, however, takes a few additional steps:
-
Update the status of the read replica to
OFFLINE_SOFT:UPDATE mysql_servers SET status = 'OFFLINE_SOFT' WHERE hostname = '[IP_ADDRESS]'; LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK;The
OFFLINE_SOFTstatus flag instructs ProxySQL to stop sending new queries to the read replica. Existing connections still persist. Monitor the status of the read replica in the Cloud Console by going to the Cloud SQL instances page and clicking the read replica you would like to remove. The performance chart is available on the instances page. You should see that your read replica is no longer used by your application. Note that setting the read replica to offline in ProxySQL does not stop it from running in Cloud SQL; you are still being charged for the replica. See steps below to remove it from Cloud SQL. -
If you do not plan to use the read replica any more in the future, delete it from
mysql_serverstable:DELETE FROM mysql_servers WHERE hostname = '[IP_ADDRESS]'; LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK;All the traffic will be terminated immediately, so you should proceed with deletion only after you are certain that the read replica has completed all the queries sent its way. Use the performance chart (
MySQL queries,active connections, etc.) to monitor the status.Then remove it from Cloud SQL:
-
Go to the Cloud SQL instances page and click the read replica you would like to remove.
-
Click Delete. Follow the instructions on screen to delete the instance.
-
-
Update the rules and weights accordingly.
Unlike the master instance, read replicas cannot be stopped (and then restarted later) in Cloud SQL. If you plan to add a read replica after deletion, create a new one and update the ProxySQL settings. The master instance cannot be stopped or deleted until all the read replicas are deleted.
After finishing this tutorial, you can clean up the resources you created on Google Cloud so that you are not billed for them in the future. To clean up, you can delete the whole project or delete the master instance in Cloud SQL.
Visit the Manage resources menu. Select the project you used for this tutorial and click Delete. Note that once the project is deleted, the project ID cannot be reused.
If you have Cloud SDK installed in the system, you can also use the gcloud command-line to delete a project.
Go to the Cloud SQL instances page. If there are still read replicas, remove them one by one. For each one, click the kebab icon (three vertical dots) and choose Delete in the drop down menu. After all the read replicas are removed, delete the master instance in the same manner.