Getting to know the Google Cloud Healthcare API: part 2

Chris von See
Staff Technical Solutions Consultant
The Google Cloud Healthcare & Life Sciences team recently introduced a set of application programming interfaces (APIs) and data stores that can be used to enable healthcare data analysis and machine learning applications, data-level integration of healthcare systems and secure storage/retrieval of various types of electronic patient healthcare information (ePHI). The first article in this series provided a brief overview of the Cloud Healthcare API and its possible use cases; in this article we’ll do a deeper dive into key concepts implemented in the API, and show how to perform a basic API implementation.
Cloud Healthcare API concepts
To get the most out of the Cloud Healthcare API, there are a few key concepts you’ll want to understand. The information below should give you a good sense of Cloud Healthcare API capabilities, but you can find more details in the documentation.
General structure of the Cloud Healthcare API
The Cloud Healthcare API exposes interfaces that enable you to perform different types of functions:
Administrative functions, such as creating or listing datasets and stores that will contain your data;
Data access functions that allow you to create, update, delete and search the data stored in Cloud Healthcare API, or to perform bulk import and export operations;
Security functions that allow you to impose access controls on data stored in Cloud Healthcare API;
De-identification functions that allow you to replace ePHI with anonymized data, or to obfuscate ePHI so that it cannot be used;
Metadata functions, such as retrieval of a FHIR capabilities statement for the FHIR API.
These functions may vary slightly depending on the modality of data (FHIR, HL7 v2 or DICOM) being operated on. For example, data retrieval operations against an FHIR data store use an API that conforms to the FHIR standard, but data retrieval operations against an HL7 v2 store use operations better suited to operating on HL7v2-structured data.
Datasets and stores
All Cloud Healthcare API usage occurs within the context of a Google Cloud Platform project. Projects form the basis for creating, enabling, and using all GCP services including managing APIs, enabling billing, adding and removing collaborators, and managing permissions for GCP resources. Cloud Healthcare API can be used in one or many GCP projects, as appropriate; this flexibility allows you to separate production from non-production usage, for example, or to segregate applications and resources in order to better manage access or accommodate different development lifecycles.
Within a project, data ingested through Cloud Healthcare API is stored in a dataset, which resides in a geographic location corresponding to a specific GCP region. You use the Cloud Healthcare API’s administrative functions to create a dataset in a particular location; doing so facilitates implementation of data location requirements for the countries in which your applications provide services. For example, you can choose to create a dataset in GCP’s “us-central1” region for US-based applications, or in an EU or UK region for applications serving those customers. This level of location control is also available in other GCP products, which can be combined with Cloud Healthcare API to create a complete application architecture. A list of generally available GCP products and the regions in which they are implemented can be found here.
Because each healthcare data modality has different structural and processing characteristics, datasets are split into modality-specific stores. A single dataset can contain one or many stores, and those stores can all service the same modality or different modalities as application needs dictate. Using multiple stores in the same dataset might be appropriate if a given application processes different types of data, for example, or if you’d like to be able to separate data according to its source hospital, clinic, department, etc. An application can access as many datasets or stores as its requirements dictate with no performance penalty, so it’s important to design your overall dataset and store architecture to meet the organization’s broad goals for locality, partitioning, access control, and so on.
The diagram below illustrates two datasets in a GCP project, each of which contains multiple stores.
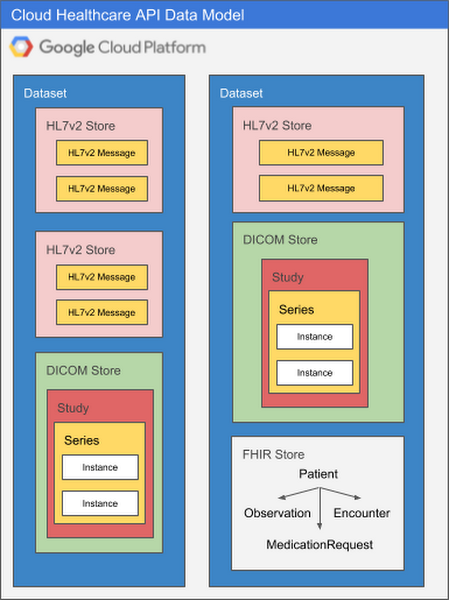
There are many ways to structure datasets and stores. As you design systems that use the Cloud Healthcare API, you may want to take the following into consideration:
Security and access control: Rules can be defined at both a dataset and store level, but you may choose to group all data for a particular application into the same dataset, and set access control rules such that only that application can access the dataset.
Application requirements: An application processing different types of data may have all of its data for all modalities in a single dataset.
Source systems: Often, the structure of healthcare data can vary according to the source system and modality. Separating data for different source systems into their own datasets may facilitate processing.
Intended use: Data from different systems can have different intended uses, such as research, analytics or machine learning predictions. Grouping data by intended use may facilitate ingestion into the target system.
Separating ePHI from de-identified data: Cloud Healthcare API data de-identification functions read from a source dataset and write the output into a new dataset that you specify. If you are preparing data to be used by researchers, for example, this approach to de-identifying data may be a consideration in how you use datasets to segregate data.
API structure
Data in Cloud Healthcare API datasets and stores can be accessed and managed using a REST API that identifies each store using its project, location, dataset, store type and store name. This API implements modality-specific standards for access that are consistent with industry standards for that modality. For example, the Cloud Healthcare DICOM API natively provides operations for reading DICOM studies and series that are consistent with the DICOMweb standard, and supports the DICOM DIMSE C-STORE protocol via an open-source adapter. Similarly, the FHIR API provides operations for accessing or searching FHIR entity types that is based on the FHIR standard, and the HL7 v2 API provides operations for reading and searching HL7 v2 messages based on HL7 v2 message or segment criteria.
Operations that access a modality-specific store use a request path that is comprised of two pieces: a base path, and a modality-specific request path. Administrative operations—which generally operate only on locations, datasets and stores—may only use the base path, but data modality-specific retrieval operations use both the base path (for identifying the store to be accessed) and request path (for identifying the actual data to be retrieved).
To reference a particular store within a Cloud Healthcare API dataset, you would use a base path structured like this:
which references a Cloud Healthcare HL7 v2 store in the GCP project “myProj”, in the “us-central1” region, in a dataset called “central-ds1”, and with a name of “clinical-store1”. We know this is an HL7 v2 store because of the “hl7V2Stores” type; if we had wanted to access a FHIR store in the same dataset we could have used the “fhirStores” type, and if the store contained DICOM data we could have used the “dicomStores” type.
To access a specific piece of data, the base path is used in combination with a request path that is formatted according to the appropriate modality standard. For example, a request to read a specific FHIR “Patient” entity using the entity ID might look like this:
with “/Patient/{patient_id}” being a path—structured according to the FHIR standard—for the Patient resource whose identifier is specified by “{patient_id}”. Similarly, DICOMweb requests to a DICOM store might look like this:
where “{study_id} identifies a particular DICOM study, and the patient’s name is specified by “{patient_name}”. In this example, the path specification is consistent with the DICOMweb standard path structure.
Enabling the Cloud Healthcare API
Enabling the Cloud Healthcare API for your project is very straightforward. First, go to the Cloud Console and select “APIs and Services” from the drop-down menu at the top left corner.
Click the “Add APIs and Services” button, then type “Cloud Healthcare API” into the search box.

When the “Enable” operation completes, your project will have access to the Cloud Healthcare API.
Securing access
Once the Cloud Healthcare API has been enabled for your project, you will be able to use Cloud Identity and Access Management (IAM) to assign Cloud Healthcare API roles and permissions. Generally speaking, you will create IAM service accounts for applications to use when authenticating to GCP. Consistent with the “principle of least privilege", service accounts should only have the minimum permissions necessary to do their intended job.
In IAM, Cloud Healthcare API roles and permissions are grouped by function and modality in much the same way as the API itself. Cloud Healthcare API roles and permissions can be assigned along with other GCP access rights to provide unique combinations that match specific requirements. For example, the following list of roles—which represent common groupings of Cloud Healthcare API permissions—might be appropriate for an application that creates a FHIR store, reads Cloud Storage and inserts data into the created FHIR store:
Healthcare FHIR Resource Editor
Healthcare FHIR Resource Reader
Healthcare FHIR Administrator
Healthcare FHIR Store Viewer
Storage Object Viewer
As you can see, Cloud Healthcare API roles make it easy to identify what’s needed for different types of access. If your application’s needs are more specific, it’s often useful to assign groups of permissions to your own custom IAM roles, and then to assign those roles to service accounts. You can see the complete set of roles and permissions by reviewing the Cloud Healthcare API access control documentation.
Once the appropriate roles and permissions are assigned to your service account, you can download the key to your service account and use it in either interactive or non-interactive sessions. For interactive sessions, you can use the “gcloud auth active-service-account” command to make the service account the currently-active account for authentication purposes. For non-interactive accounts, you can use the service account key in conjunction with tools such as the “oauth2l” token generation utility to generate OAuth 2 access tokens. Check the IAM documentation for more information on obtaining access tokens.
With your new service account key and token set to go, you can begin creating datasets and stores using the administrative functions of the Cloud Healthcare API.
NOTE: Before storing personally-identifiable healthcare data on GCP, be sure to implement appropriate compliance, security, and auditing controls to protect this data. For more information about Google’s adherence to the standards, regulations and certifications governing privacy, see our compliance page.
Creating a dataset and store
In order to create a dataset and store, first select the GCP projects and locations you wish to use to store and manage your data. Then, you can create a dataset by issuing an API request similar to the one shown below.
This command will create a dataset in the project and region specified by “PROJECT_ID” and “LOCATION”, respectively. The dataset will have the name specified in the “DATASET_ID” parameter in the POST body.
NOTE: The example above and the ones that follow use the “curl” command-line tool, but any API client can be used. They also take advantage of a feature of the “gcloud” command-line tool that allows a command to retrieve an access token for the currently authenticated session. While this option may be appropriate for interactive sessions, you may also choose other methods, such as the “oauth2l” tool available on Github, that better suit your needs.
Once the dataset is created you can create one or more modality-specific stores in that dataset. The process is essentially the same regardless of modality. To create an FHIR store in a dataset, for example, you can use a command similar to the following:
This command will create an FHIR store with the name specified by “FHIR_STORE_ID” in the dataset identified by “DATASET_ID”, in the project and region specified by “PROJECT_ID” and “LOCATION”. Note the addition of the modality type “fhirStores” to the end of the URL.
To create a DICOM store, the command is very similar:
In this command we create a DICOM store with the name specified by “DICOM_STORE_ID” in the dataset identified by “DATASET_ID”, in the project and region specified by “PROJECT_ID” and “LOCATION”. To indicate that we want a DICOM store, we specified the DICOM modality type “dicomStores” at the end of the URL.
When you create a modality-specific store, it’s possible to associate the store with a Cloud Pub/Sub topic. This is particularly valuable when you have applications that need to be notified when operations are performed on data in the store. Other options are available when creating modality specific stores, such as enabling or disabling FHIR referential integrity checks, or enabling or disabling message updates.
For more information on creating datasets and stores, see the “How To” section of the Cloud Healthcare API documentation. The REST Reference section of the documentation has more information on the available options for each modality-specific store type.
Enabling additional dataset- or store-level access control
After a dataset or modality-specific store is created, you can set additional restrictions to identify specific IAM members that can have access. Using the “setIamPolicy” API request on the dataset or store enables you to identify specific members that will have specific roles for that dataset or store.
The request below, for example, assigns the “owner” role to a service account for a particular dataset:
You can also retrieve and test the IAM policies for a particular dataset or store. For more information, see the REST reference.
Apigee-based security
For applications that leverage mobile or Web technologies, Apigee Edge can provide an additional layer of security and control over which applications can have access to what data, when, and how. Apigee also provides significant functionality to enable you to mitigate threats, manage and monitor traffic, obtain usage statistics, manage application developers and their applications, and other critical tasks.
Google and Apigee have created open-source tools for use with Apigee that allow you to use a small number of service accounts to manage access for a large number of applications, to easily manage those service accounts, and to hide Cloud Healthcare API implementation details from consuming applications. You can find this tooling in the healthcare-api-token-generator repository on Github.
More information on Apigee’s capabilities can be found on their web site.
Reading, writing, updating and deleting data
As mentioned earlier, each modality-specific data store has its own API for creating, reading, updating and deleting data. To read FHIR data from an FHIR store, for example, you’d use an HTTP GET operation against a path that identifies both the FHIR store to be read and the specific data you’re looking for:
Requests against stores of other modalities in the same dataset may look very similar. A “get” operation against an HL7v2 store in the same dataset as the request above might look like this:
Comparing the two requests, you can see that while most of the base path identifying the dataset to be read is the same (“/projects/myProj/locations/us-central1/datasets/central-ds1”), the store type, store name and request path are different (“/fhirStores/fhir-store1/fhir/Patient/{patient-id}“ for the FHIR request, vs “/hl7V2Stores/hl7v2-store2/messages/{message-id}” for the HL7v2 request). This pattern is very similar for other operations that create, update or delete data.
The details of each request type can be found in the documentation.
Auditing access
GCP provides two types of auditing logs: admin access logs and data access logs. Admin access logs (for API calls or other administrative actions that modify the configuration or metadata of resources) is on all of the time by default. However, because of the large volume of log data generated, data access logging (API calls that create, modify, or read user-provided data) must be explicitly activated. You can view audit logs using Google Cloud’s Stackdriver hybrid monitoring system
The Google Cloud documentation has more information on audit logging.
What’s next?
In the final installment of this series, we’ll provide some specific examples of how you can leverage the Cloud Healthcare API. Watch this space for more information about how you can use the Cloud Healthcare API to better analyze your data and deliver innovative new healthcare applications.



