Track, compare, manage experiments with Vertex AI Experiments
Ivan Nardini
Customer Engineer
May Hu
Product Manager, Google Cloud
Track, compare, manage experiments with Vertex AI Experiments
Managing experiments is one of the main challenges for data science teams.
Finding the best modeling approach that works for a particular problem requires both hypothesis testing and trial-and-error. Tracking development and outcomes using docs and spreadsheets is neither reliable nor easy to share. Consequently the process of ML development is severely affected.
Indeed, not having a tracking service leads to manual copy/pasting of the parameters and metrics. With an increasing number of experiments, a model builder won’t be able to reproduce the data and model configuration that was used to train models. Consequently the model’s predictive behavior and performance changes cannot be verified.
This lack of information is even more impactful when you have different teams involved in several use cases.
At scale, the steps of an ML experiment need to be orchestrated using pipelines. But how can data science teams guarantee rapid iteration of experiments and better readiness at the same time without the benefit of having a centralized location to manage and validate the results?
Bottom line is that it is much harder to turn your model into an asset for the company and its business.
To address these challenges, we are excited to announce the general availability of Vertex AI Experiments, the managed experiment tracking service on Vertex AI.
Vertex AI Experiments is designed not only for tracking but for supporting seamless experimentation. The service enables you to track parameters, visualize and compare the performance metrics of your model and pipeline experiments. At the same time, Vertex AI Experiments provides an experiment lineage you can use to represent each step involved in arriving at the best model configuration.
In this blog, we’ll dive into how Vertex AI Experiments works, showcasing the features that enable you to:
track parameters and metrics of models trained locally using the Vertex AI SDK
create experiment lineage (for example, data preprocessing, feature engineering) of experiment artifacts that others within your team can reuse
record the training configuration of several pipeline runs
But before we dive deeper, let’s clarify what a Vertex AI Experiment is.
Run, Experiment and the Metadata service
In Vertex AI Experiments, you have two main concepts : run and experiment.
Runs are associated with a particular training configuration that a data scientist took while solving a particular ML challenge. For each run you can record:
Parameters as key-value inputs of the run,
Summary and time-series metrics (the metrics recorded at the end of each epoch) as key-value outputs of the run,
Artifacts including input data, transformed datasets and trained models.
Because you may have multiple runs, you can organize them into an experiment, which is the top level container for everything that a practitioner does to solve a particular data science challenge.
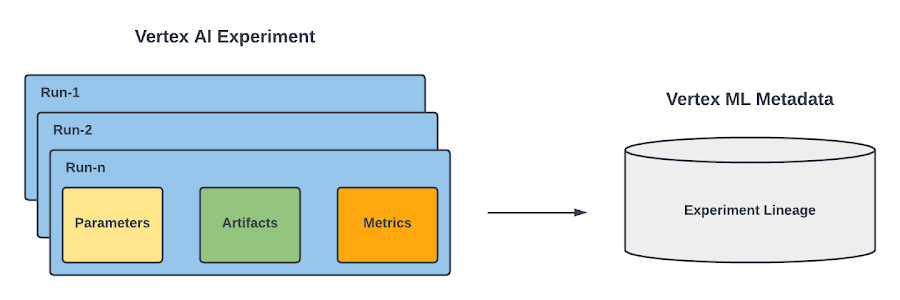
Figure 1. Run, Experiment and the Metadata service |
Notice that both runs and experiments leverages Vertex ML Metadata, which is a managed ML Metadata store based on the open source ML Metadata (MLMD) library developed by Google's TensorFlow Extended team. It lets you record, analyze, debug, and audit metadata and artifacts produced during your ML journey. In the case of Vertex AI Experiments, it allows you to visualize the ML lineage of your ML experiment.
Now that you know what a Vertex AI Experiment is, let’s see how you can leverage its capabilities to address the potential challenges of tracking and managing your experiments at scale.
Comparing models trained and evaluated locally
As a Data scientist, you probably will start training your model locally. To find the optimal modeling approach, you would like to try out different configurations.
For example, if you are building a TensorFlow model, you would want to track data parameters such as `buffer_size` or the `batch_size` of the tf.data.Dataset , and model parameters such as layer name, the `learning_rate` of the optimizer , and `metrics` you want to optimize.
As soon as you try several configurations , you will need to evaluate the resulting model by generating metrics for further analysis.
With Vertex AI Experiments, you can easily create an experiment and log both parameters, metrics, and artifacts that are associated with your experiment runs by using both the Vertex AI section of the Google Cloud console and the Vertex AI SDK for Python.
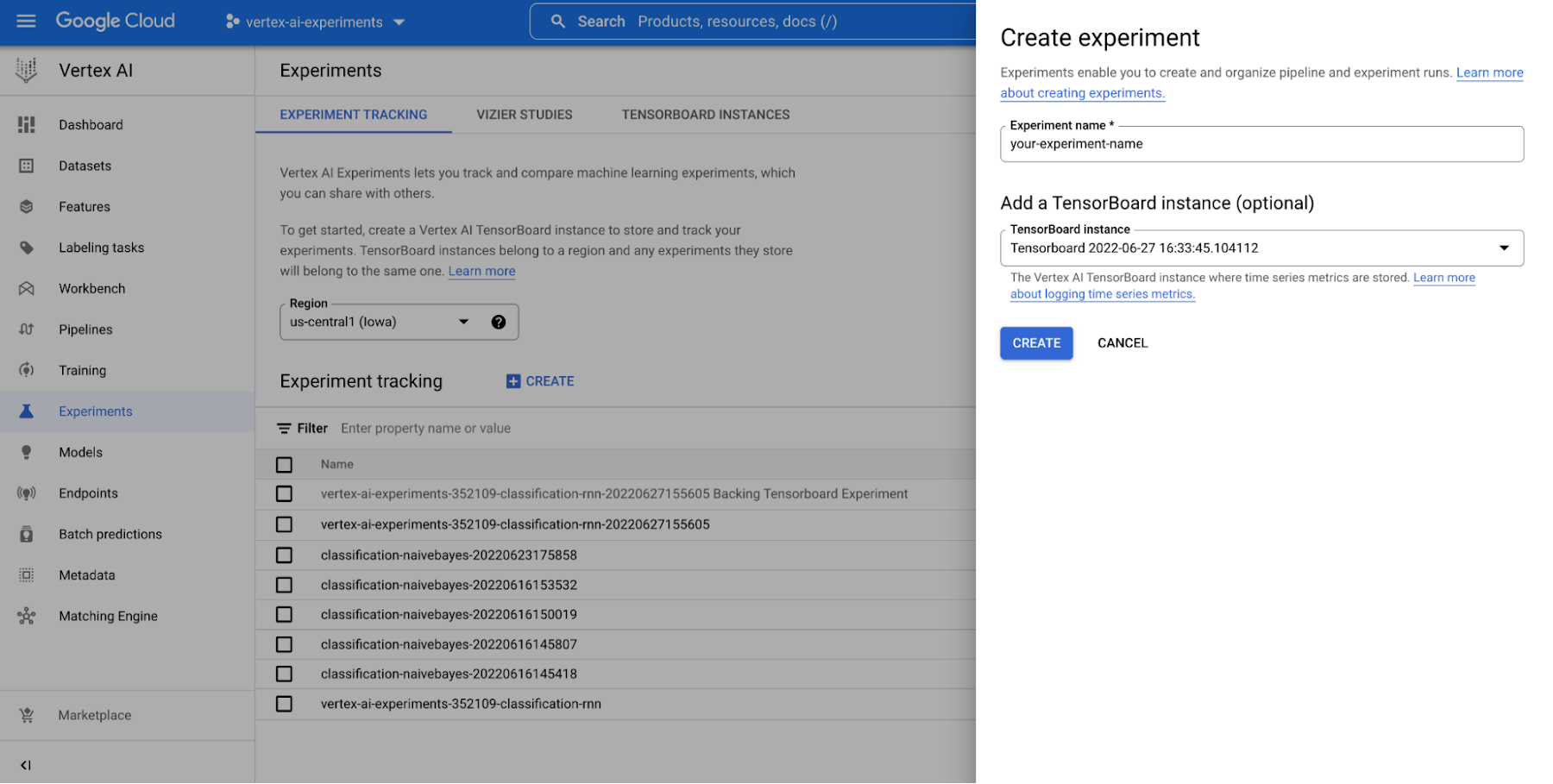
Figure 2. Create an experiment (console) |
Notice also that the SDK provides a handy initialization method that allows you to create a TensorBoard instance using Vertex AI TensorBoard for logging model time series metrics. Below you can see how to start an experiment, log model parameters and track evaluation metrics both per epoch and at the end of the training session.
Create an experiment (Vertex AI SDK)
Then you can analyze the result of the experiment by viewing the Vertex AI section of the Google Cloud console or by retrieving them in the notebook. This video shows what it would look like.
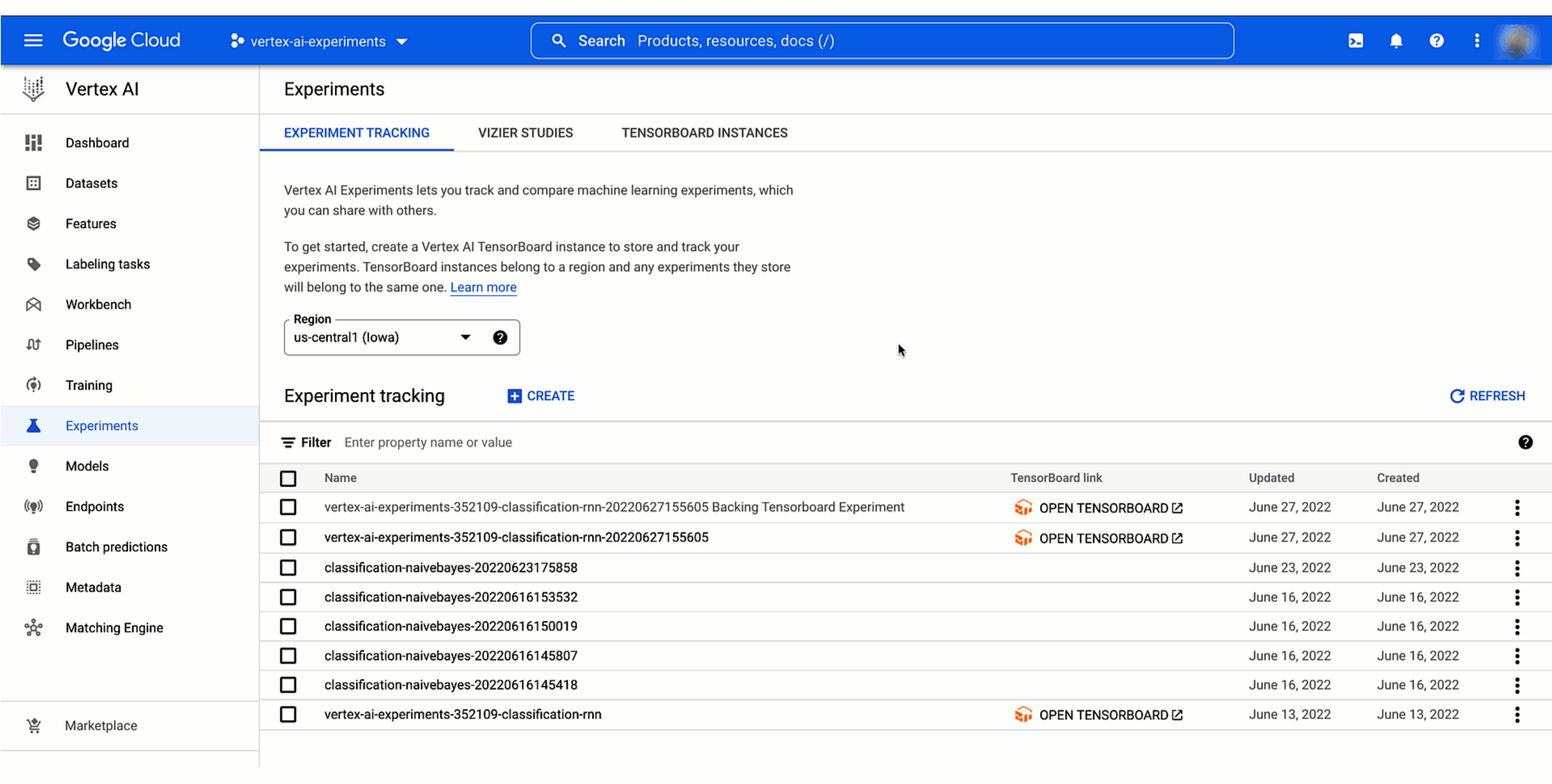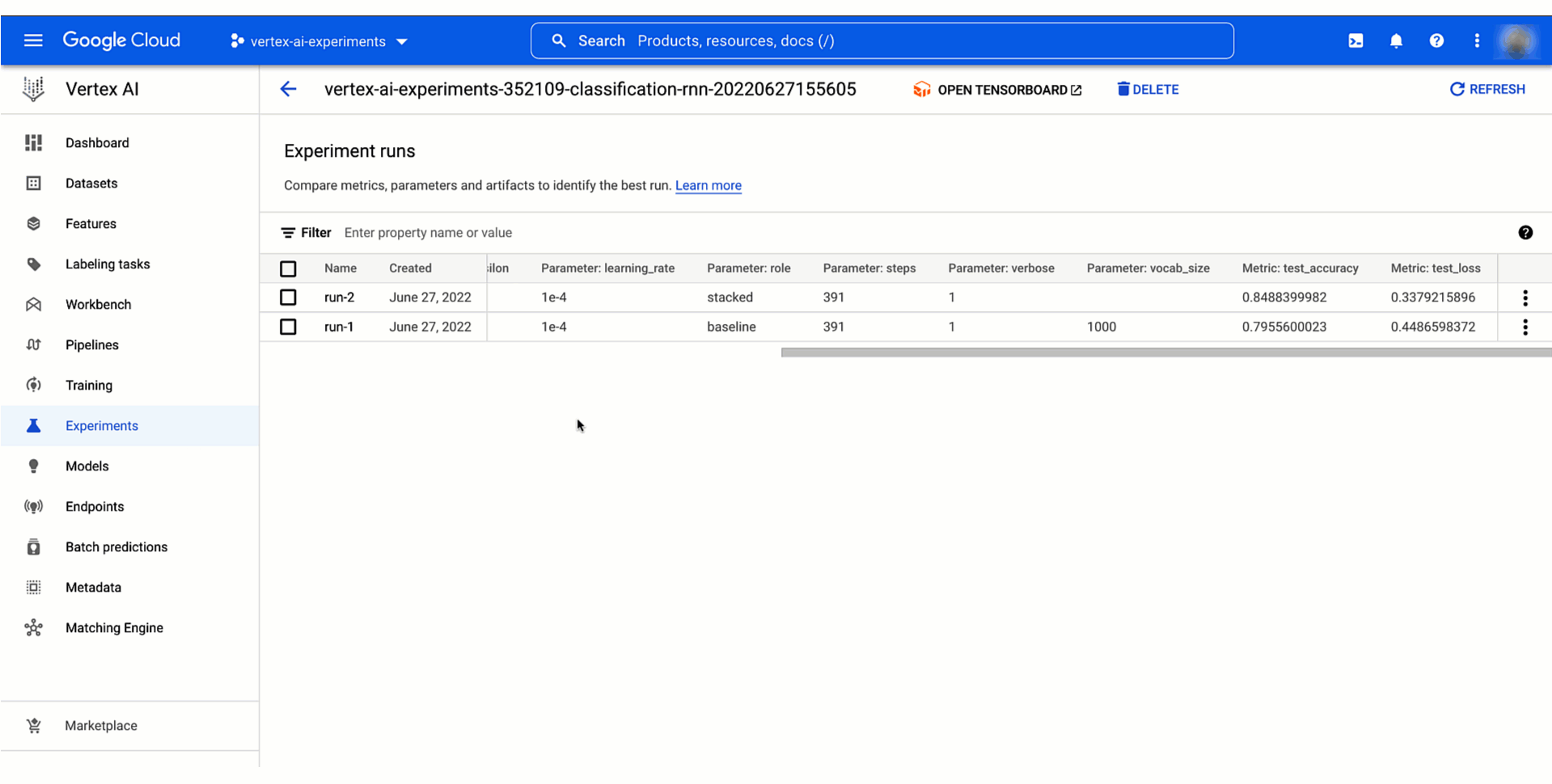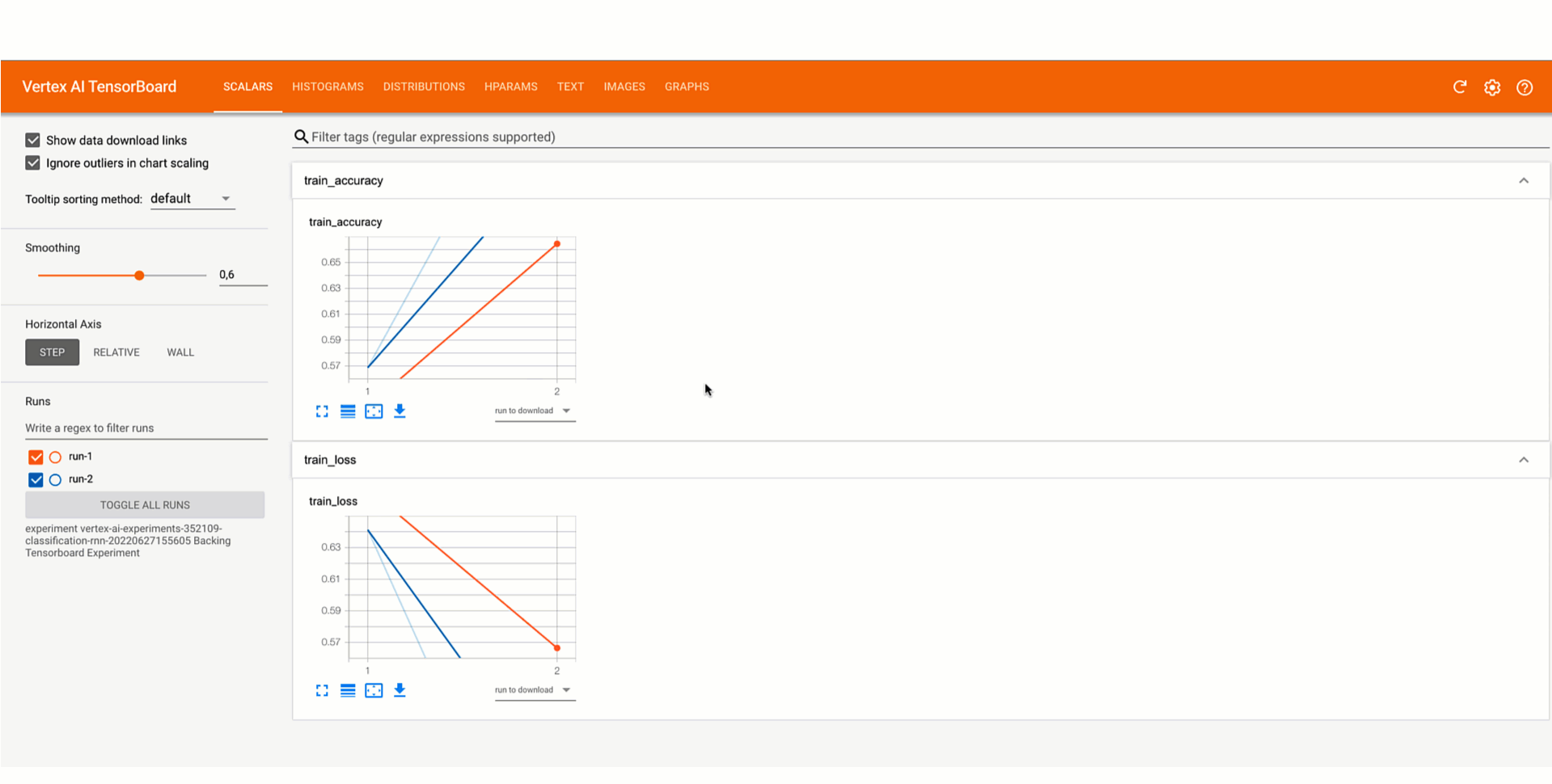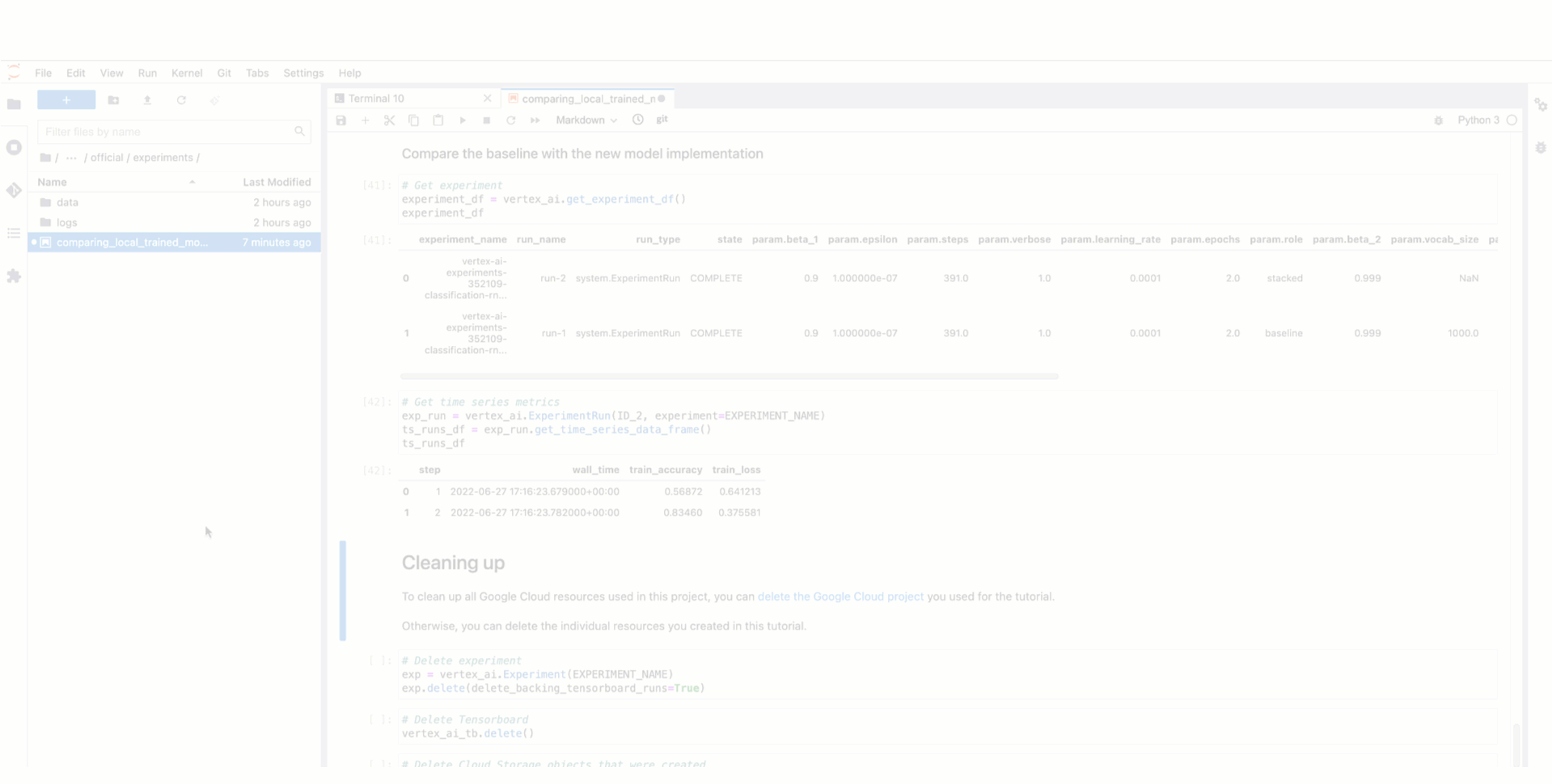
Figure 3. Compare models trained and evaluated locally with Vertex AI Experiments |
Tracking model training experiment lineage
The model training is just a single step in an experiment. Some data preprocessing is also required that others within your team may have written. For that reason, you need a way to easily integrate preprocessing steps and record the resulting dataset to reuse it along several experiment runs.
By leveraging the integration with Vertex ML Metadata, Vertex AI Experiments allows you to track the data preprocessing as part of the experiment lineage by running an Vertex ML Metadata execution in your experiment context. Here you can see how to use execution to integrate preprocessing code in a Vertex AI Experiments.
Integrate data preprocessing code in Vertex AI Experiment
Once the execution is instantiated, you start recording the data preprocessing step. You can assign the dataset as input artifact, consume the dataset in the preprocessing code and pass the preprocessed dataset as output artifact of the execution. Then, that preprocessing step and its dataset, are automatically recorded as part of the experiment lineage and they are ready to be consumed as input artifacts of different training run executions associated with the same experiment. This is how the training execution would look like with the resulting model uploaded as an model artifact after training successfully finished.
Tracking model training lineage in Vertex AI Experiment |
Below you can see how to access data and model artifacts of an experiment run from the Vertex AI Experiments view and how the resulting experiment lineage would look like in the Vertex ML Metadata.
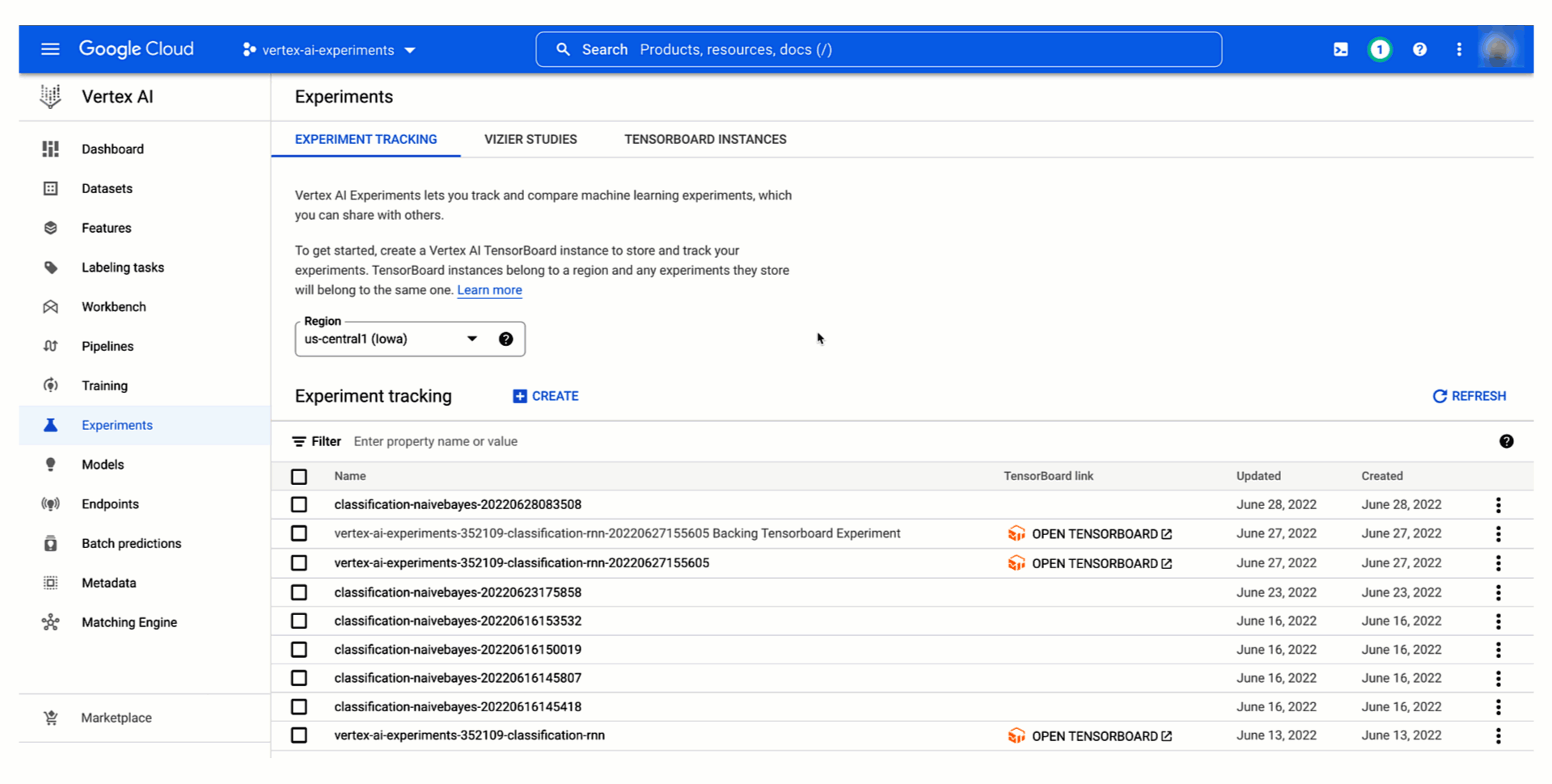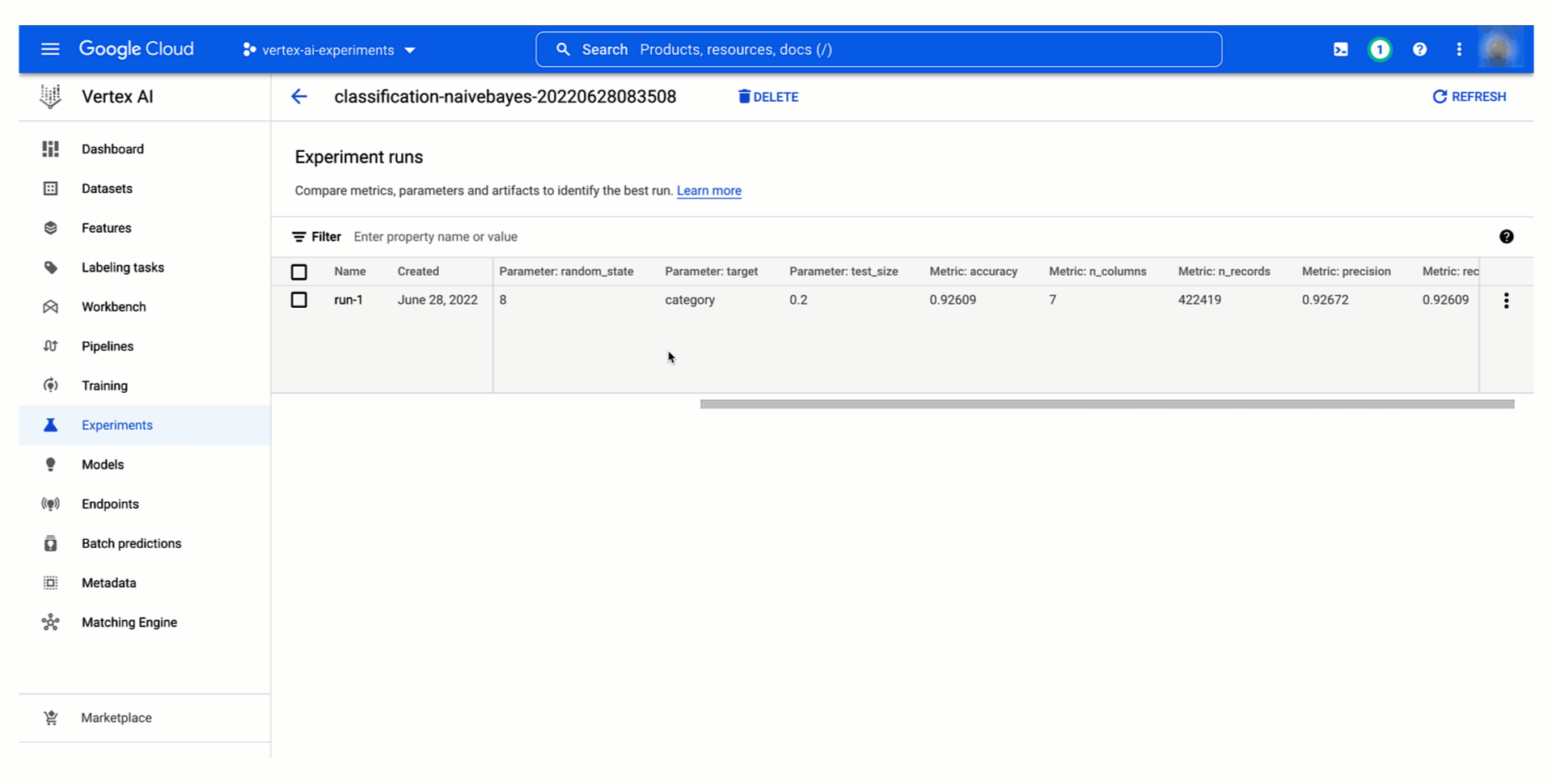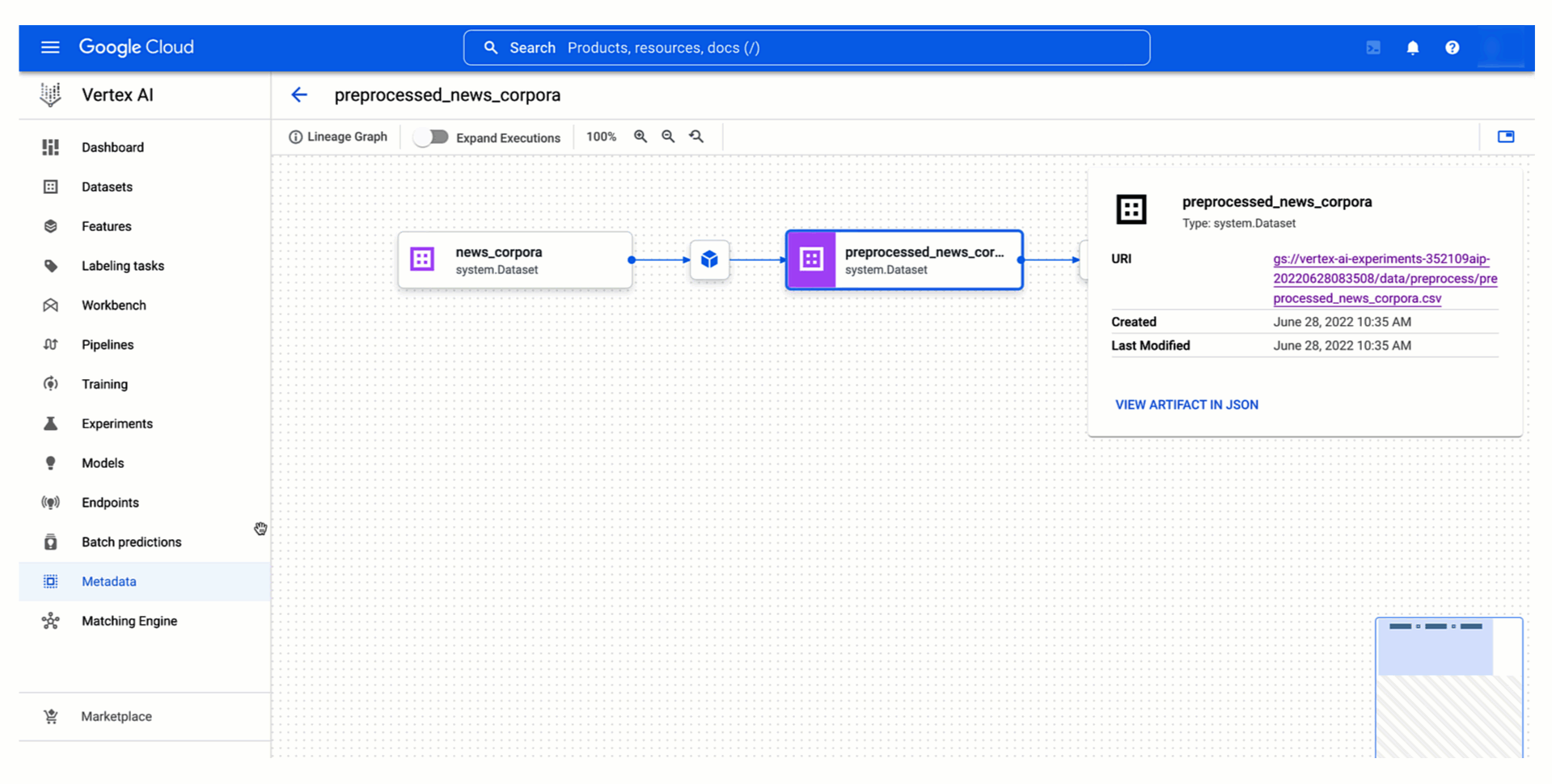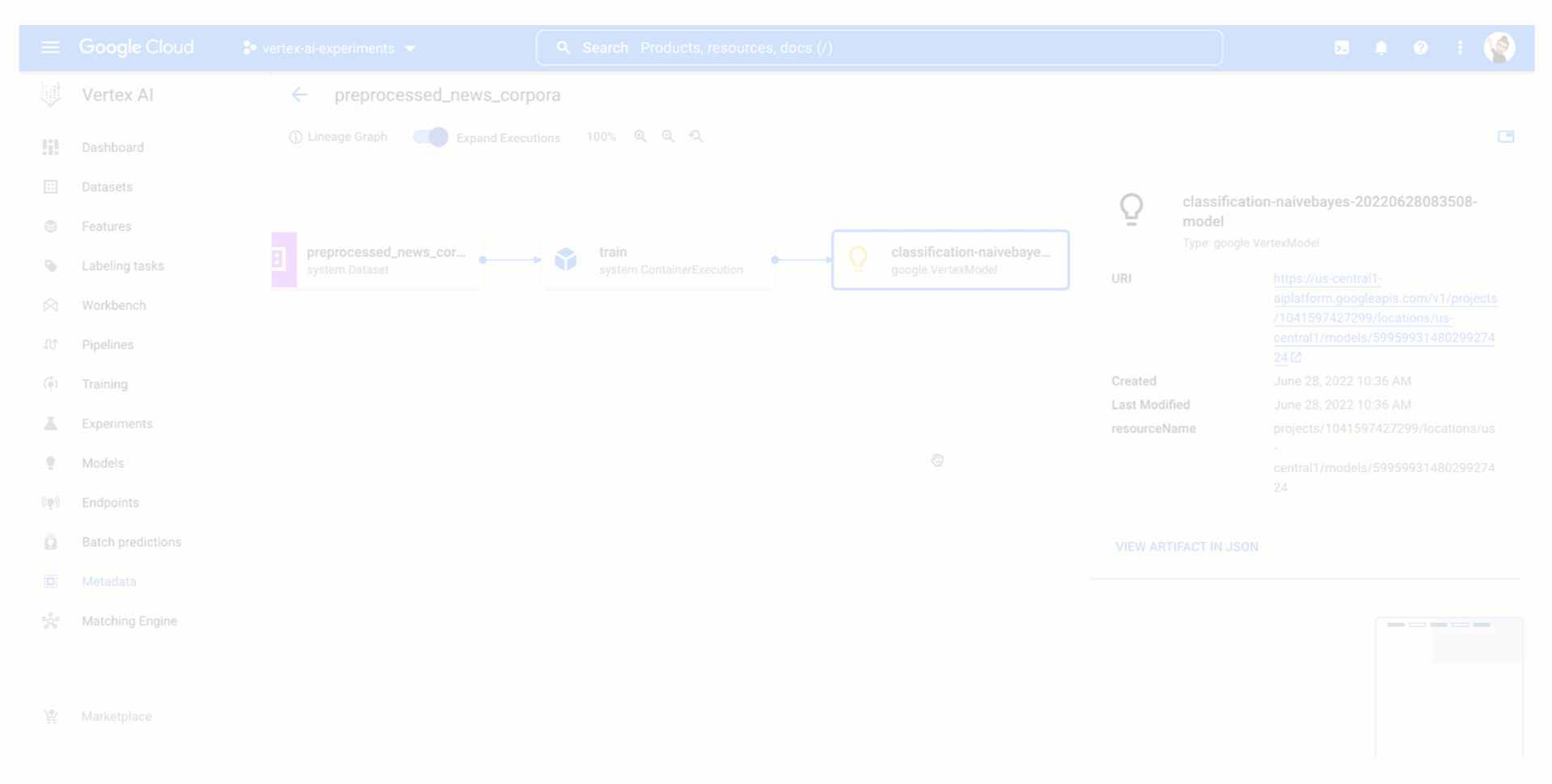
Figure 4. Tracking model training experiment lineage |
Comparing model training pipeline runs
Automating experimentation of a pipeline run is essential when you need to retrain your models frequently. The sooner you formalize your experiments in pipelines, the easier and faster it will be to move them to production. The diagram depicts a high level view of a rapid experimentation process.

As a data scientist, you formalize your experiment in a pipeline which will take in a number of parameters to train your model. Once you have your pipeline, you need a way to track and evaluate pipeline runs at scale to determine which parameters configuration generates the best performing model.
By leveraging the integration with Vertex AI Pipelines, Vertex AI Experiments lets you to track pipeline parameters, artifacts and metrics and compare pipeline runs.
All you need to do is declare the experiment name before submitting the pipeline job on Vertex AI.
Track model training pipeline runs |
Then, as demonstrated below, you will be able to see your pipeline experiment run and its parameters and metrics in Vertex AI Experiments and compare it with previous runs to then promote the best training configuration to production. You can also see the relationship with your experiment run and monitor your pipeline run in Vertex AI Pipelines. And because each run is mapped to a resource in Vertex ML Metadata, you will be able to explain your choice to others by showing the lineage automatically created on Vertex AI.
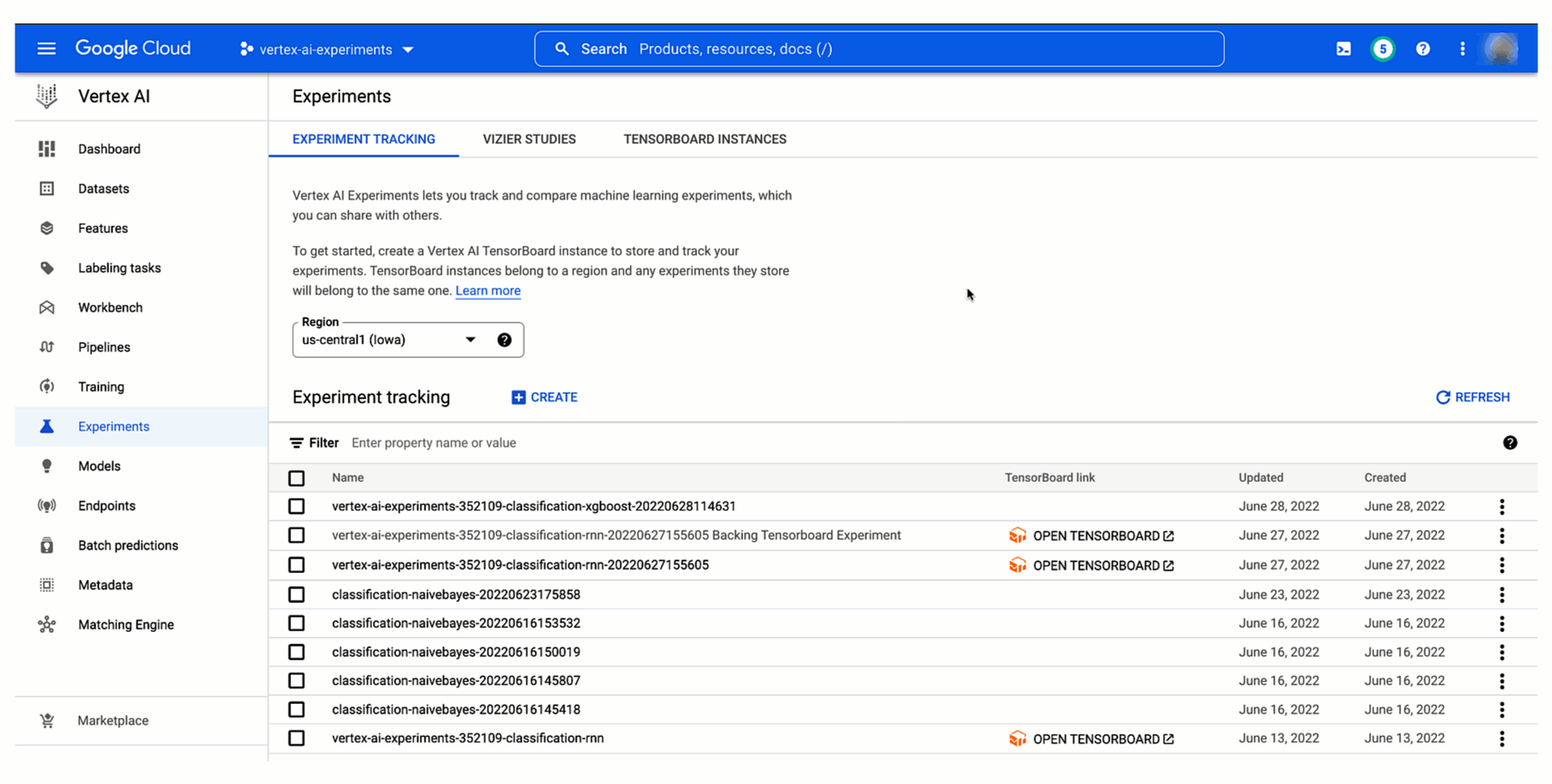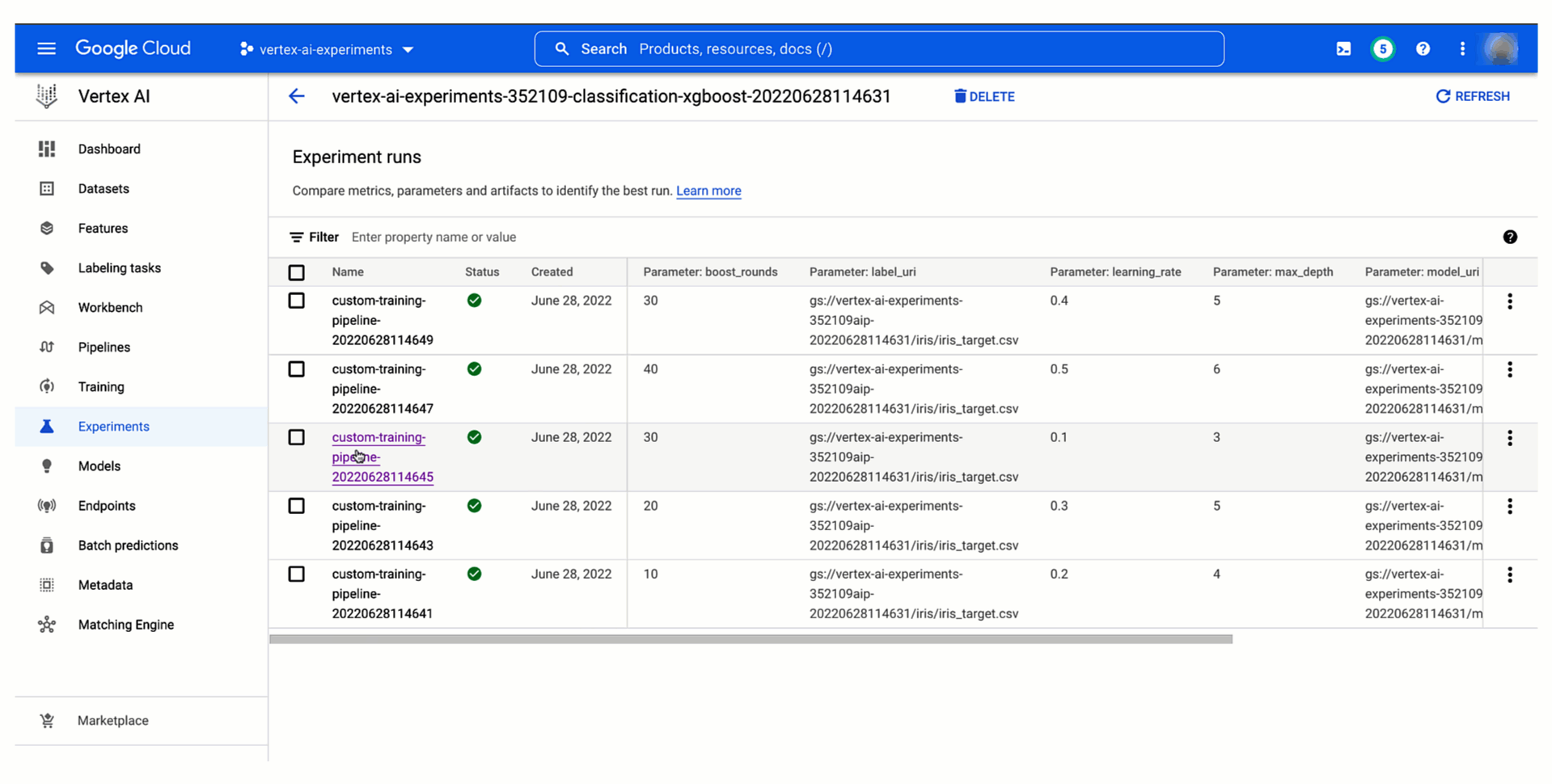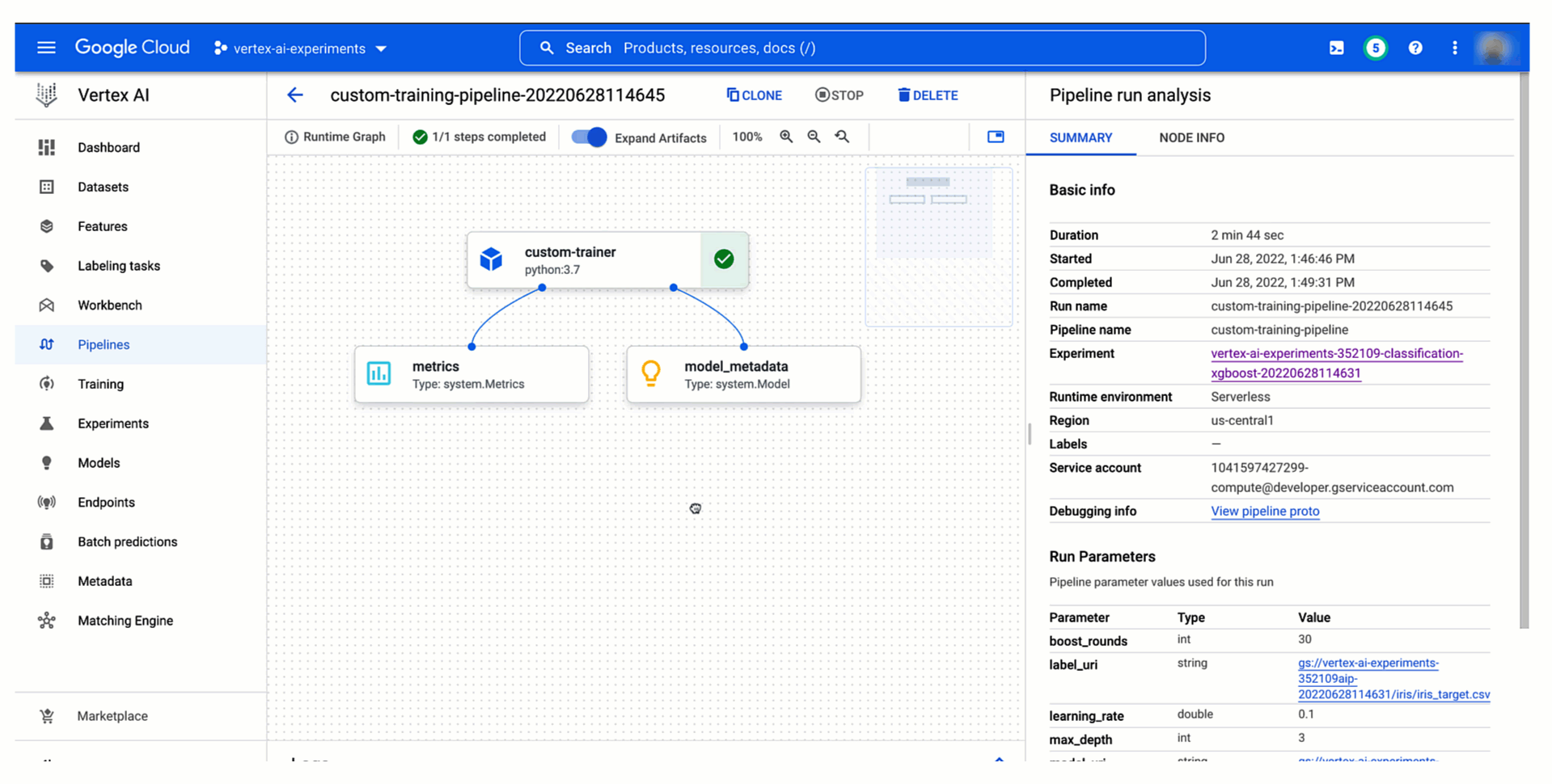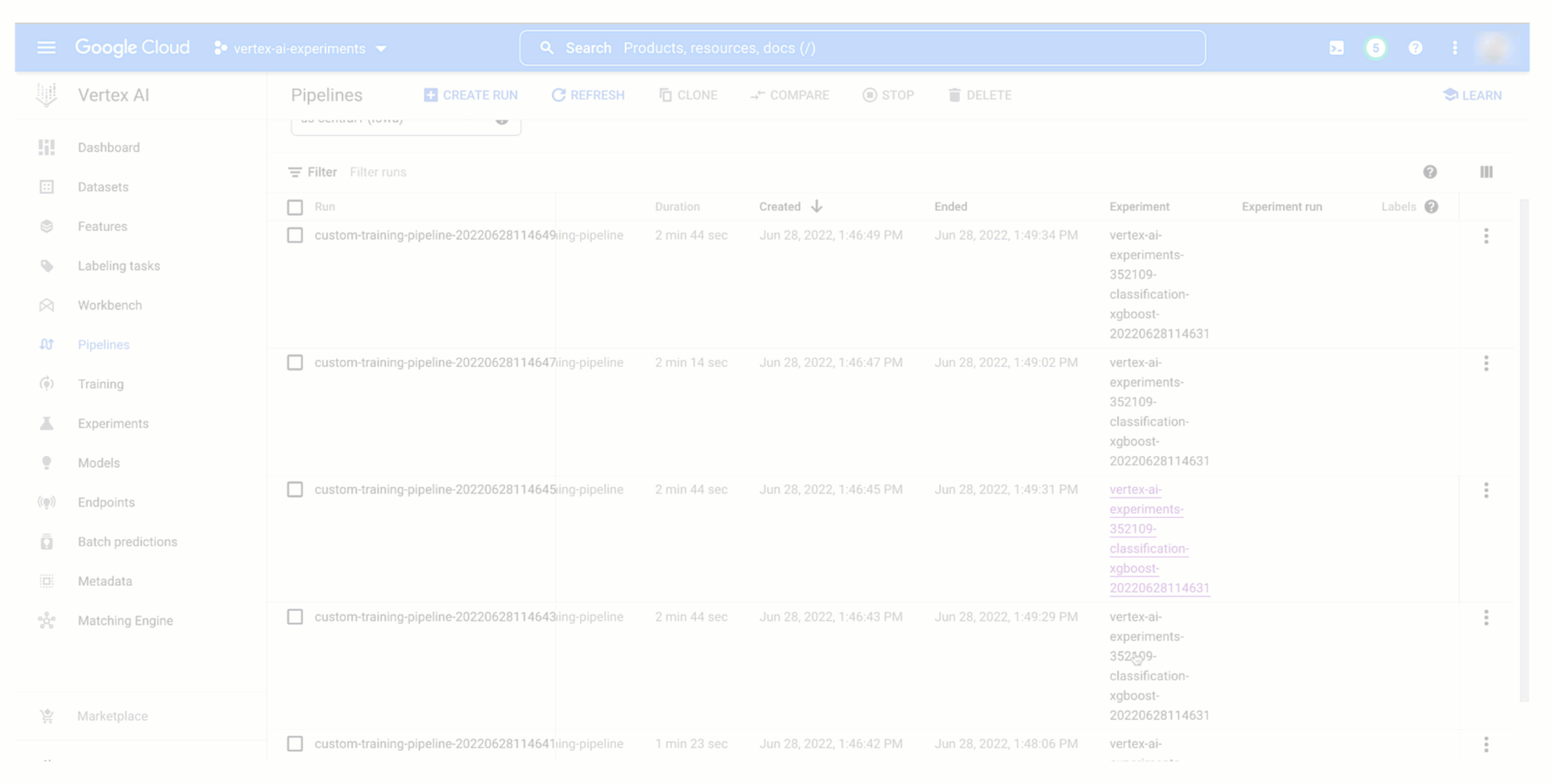
Figure 6. Track and comparing model training pipeline experiment runs |
Conclusion
With Vertex AI Experiments you will be able not only to track parameters, visualize and compare performance metrics of your models, you will be able to build managed experiments that are ready to go to production quickly because of the ML pipeline and the metadata lineage integration capabilities of Vertex AI.
Now it's your turn. While I'm thinking about the next blog post, check out notebooks in the official Github repo and the resources below to start getting your hands dirty. And remember...Always have fun!
Want to learn more?
Documentation
Learn more about Vertex AI Workbench
Learn more about Vertex AI Experiments
Learn more about Vertex AI Tensorboard
Learn more about Vertex ML Metadata
Learn more about Vertex AI Pipelines
Samples



