Scalable tech support via AI-augmented chat
James Clappison
Senior Corporate Operations Engineer
Max Saltonstall
Developer Relations Engineer
As Googlers transitioned to working from home during the pandemic, more and more turned to chat-based support to help them fix technical problems. Google's IT support team looked at many options to help us meet the increased demand for tech support quickly and efficiently.
More staff? Not easy during a pandemic.
Let service levels drop? Definitely not.
Outsource? Not possible with our IT requirements.
Automation? Maybe, just maybe...
How could we use AI to scale up our support operations, making our team more efficient?
The answer: Smart Reply, a technology developed by a Google Research team with expertise in machine learning, natural language understanding, and conversation modeling. This product provided us with an opportunity to improve our agents’ ability to respond to queries from Googlers by using our corpus of chat data. Smart Reply trains a model that provides suggestions to techs in real time. This reduces the cognitive load when multi-chatting and helps a tech drive sessions towards resolution.
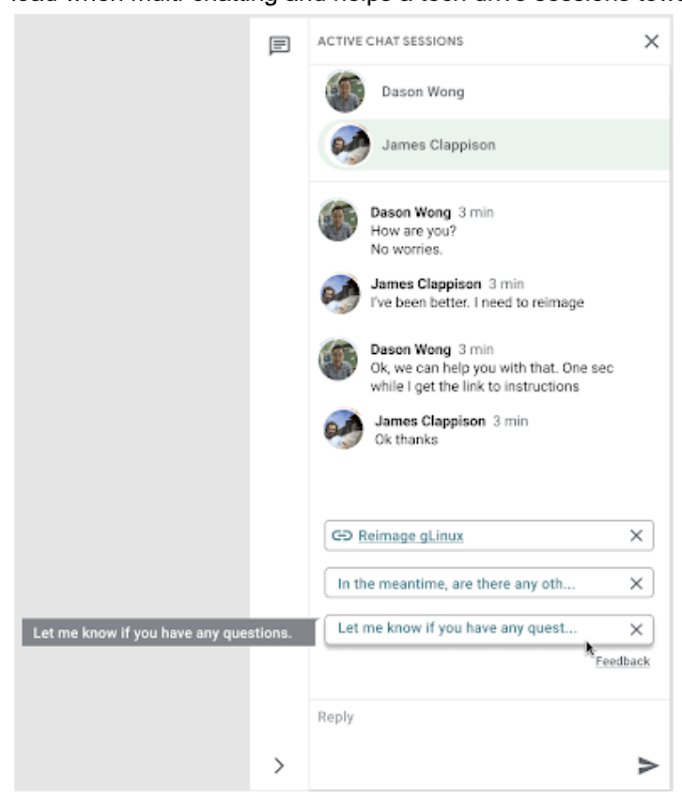
In the solution detailed below, our hope is that IT teams in a similar situation can find best practices and a few shortcuts to implementing the same kind of time saving solutions. Let's get into it!
Challenges in preparing our data
Our tech support service for Google employees—Techstop—provides a complex service, offering support for a range of products and technology stacks through chat, email, and other channels.
Techstop has a lot of data. We receive hundreds of thousands of requests for help per year. As Google has evolved we’ve used a single database for all internal support data, storing it as text, rather than as protocol buffers. Not so good for model training. To protect user privacy, we want to ensure no PII (personal identifiable information - e.g. usernames, real names, addresses, or phone numbers) makes it into the model.
To address these challenges we built a FlumeJava pipeline that takes our text and splits each message sent by agent and requester into individual lines, stored as repeated fields in a protocol buffer. As our pipe is executing this task, it also sends text to the Google Cloud DLP API, removing personal information from the session text, replacing it with a redaction that we can later use on our frontend.
With the data prepared in the correct format, we are able to begin our model training. The model provides next message suggestions for techs based on the overall context of the conversation. To train the model we implemented tokenization, encoding, and dialogue attributes.
Splitting it up
The messages between the agent and customer are tokenized: broken up into discrete chunks for easier use. This splitting of text into tokens must be carefully considered for several reasons:
- Tokenization determines the size of the vocabulary needed to cover the text.
- Tokens should attempt to split along logical boundaries, aiming to extract the meaning of the text.
- Tradeoffs can be made between the size of each token, with smaller tokens increasing processing requirements but enabling easier correlation between different spans of text.
There are many ways to tokenize text (SAFT, splitting on white spaces, etc.), here we chose sentence piece tokenization, with each token referring to a word segment.
Prediction with encoders
Training the neural network with tokenized values has gone through several iterations. The team used an Encoder-Decoder architecture that took a given vector along with a token and used a softmax function to predict the probability that the token was likely to be the next token in the sentence/conversation. Below, a diagram represents this method using LSTM-based recurrent networks. The power of this type of encoding comes from the ability of the encoder to effectively predict not just the next token, but the next series of tokens.
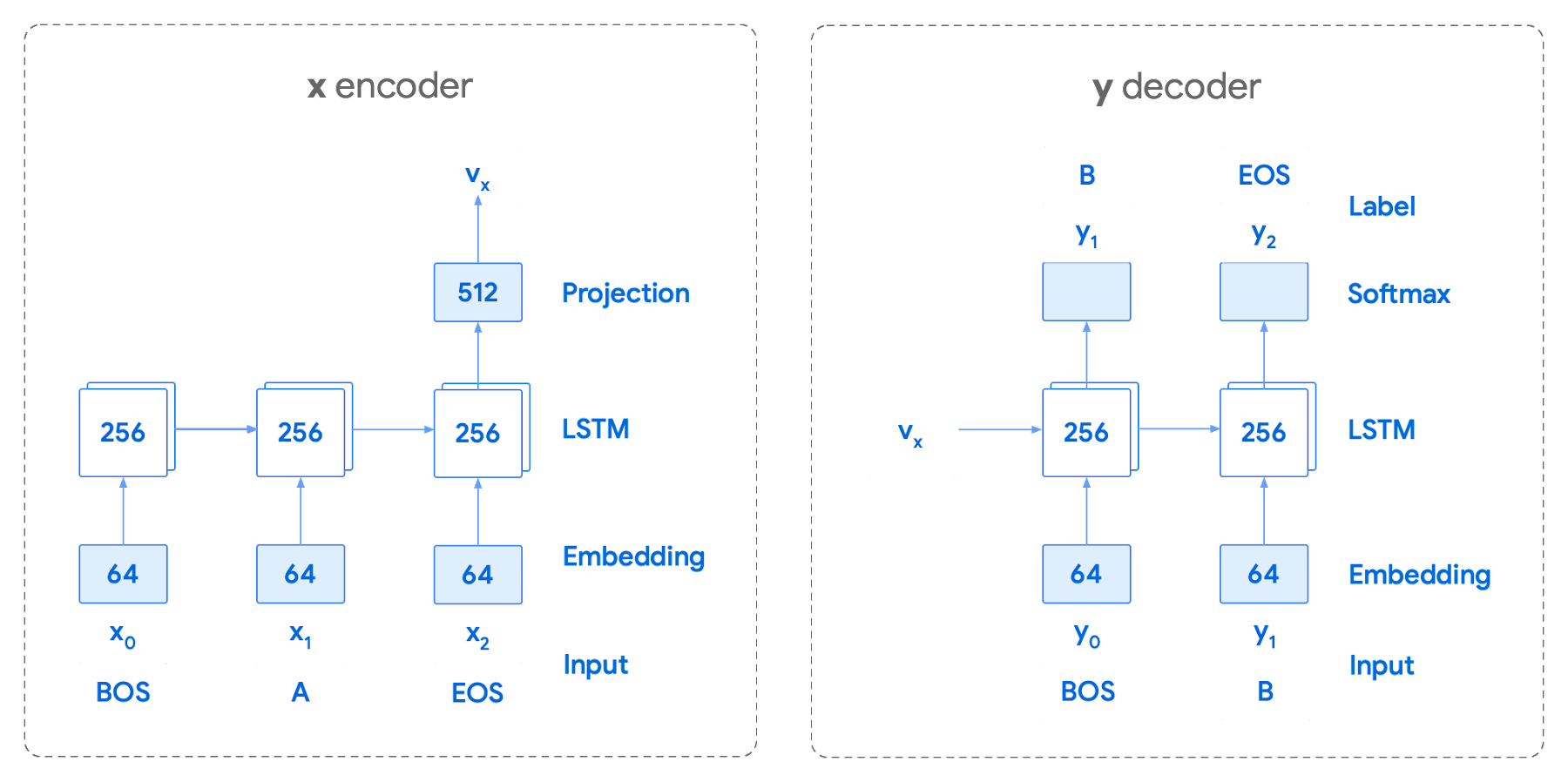
This has proven very useful for Smart Reply. In order to find the optimal sequence, an exponential search over each tree of possible future tokens is required. For this we opted to use beam search over a fixed-size list of best candidates, aiming to avoid increasing the overall memory use and run time for returning a list of suggestions. To do this we arranged tokens in a trie, and used a number of post processing techniques, as well as calculating a heuristic max score for a given candidate, to reduce the time it takes to iterate through the entire token list. While this improves the run time, the model tends to prefer shorter sequences.
In order to help reduce latency and improve control we decided to move to an Encoder-Encoder architecture. Instead of predicting a single next token and decoding a sequence of following predictions with multiple calls to the model, it instead encodes a candidate sequence with the neural network.
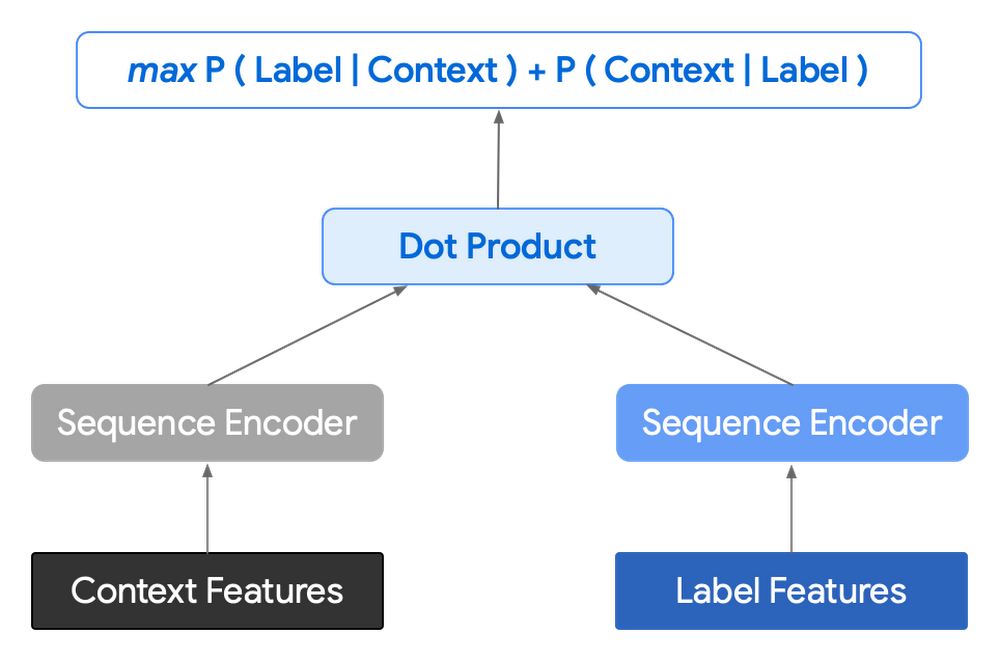
In practice, the two vectors – the context encoding and the encoding of a single candidate output – are combined with dot product to arrive at a score for the given candidate. The goal of this network is to maximize the score for true candidates – e.g. candidates that did appear in the training set – and minimize false candidates.
Choosing how to sample negatives affects the model training greatly. Below are some strategies that can be employed:
- Using positive labels from other training examples in the batch.
- Drawing randomly from a set of common messages. This assumes that the empirical probability of each message is sampled correctly.
- Using messages from context.
- Generating negatives from another model.
As this encoding generates a fixed list of candidates that can be precomputed and stored, each time a prediction is needed, only the context encoding needs to be computed, then multiplied by the matrix of candidate embeddings. This reduces both the time from the beam search method and the inherent bias towards shorter responses.
Dialogue Attributes
Conversations are more than simple text modeling. The overall flow of the conversation between participants provides important information, changing the attributes of each message. The context, such as who said what to whom and when, offers useful bits of input for the model when making a prediction. To that end the model uses the following attributes during its prediction:
- Local User ID’s - we set a finite number of participants for a given conversation to represent the turn taking between messages, assigning values to those participants. In most cases for support sessions there are 2 participants, requiring ID 0, and 1.
- Replies vs continuations - initially modeling focused only on replies. However, in practice conversations also include instances where participants are following up on the previously sent message. Given this, the model is trained for both same-user suggestions and “other” user suggestions.
- Timestamps - gaps in conversation can indicate a number of different things. From a support perspective, gaps may indicate that the user has disconnected. The model takes this information and focuses on the time elapsed between messages, providing different predictions based on the values.
Post processing
Suggestions can then be manipulated to get a more desirable final ranking. Such post-processing includes:
- Preferring longer suggestions by adding a token factor, generated by multiplying the number of tokens in the current candidate.
- Demoting suggestions with a high level of overlap with previously sent messages.
- Promoting more diverse suggestions based on embedding distance similarities.
To help us tune and focus on the best responses the team created a priority list. This gives us the opportunity to influence the model's output, ensuring that responses that are incorrect can be de-prioritized. Abstractly it can be thought of as a filter that can be calibrated to best suit the client’s needs.
Getting suggestions to agents
With our model ready we now needed to get it in the hands of our techs. We wanted our solution to be as agnostic to our chat platform as possible, allowing us to be agile when facing tooling changes and speeding up our ability to deploy other efficiency features. To this end we wanted an API that we could query either via gRPC or via HTTPs. We designed a Google Cloud API, responsible for logging usage as well as acting as a bridge between our model and a Chrome Extension we would be using as a frontend.
The hidden step, measurement
Once we had our model, infrastructure, and extension in place we were left with the big question for any IT project. What was our impact? One of the great things about working in IT at Google is that it’s never dull. We have constant changes, be it planned or unplanned. However, this does complicate measuring the success of a deployment like this. Did we improve our service or was it just a quiet month?
In order to be satisfied with our results we conducted an A/B experiment, with some of our techs using our extension, and the others not. The groups were chosen at random with a distribution of techs across our global team, including a mix of techs with varying levels of experience ranging from 3 to 26 months.
Our primary goal was to measure tech support efficiency when using the tool. We looked at two key metrics as proxies for tech efficiency:
- The overall length of the chat.
- The number of messages sent by the tech.
Evaluating our experiment
To evaluate our data we used a two-sample permutation test. We had a null hypothesis that techs using the extension would not have a lower time-to-resolution, or be able to send more messages, than those without the extension. The alternative hypothesis was that techs using the extension would be able to resolve sessions quicker or send more messages in approximately the same time.
We took the mid mean of our data, using pandas to trim outliers greater than 3 standard deviations away. As the distribution of our chat lengths is not normal, with significant right skew caused by a long tail of longer issues, we opted to measure the difference in means, relying on central limit theorem (CLT) to provide us with our significance values. Any result with a p-value between 1.0 and 9.0 would be rejected.
Across the entire pool we saw a decrease in chat lengths of 36 seconds.
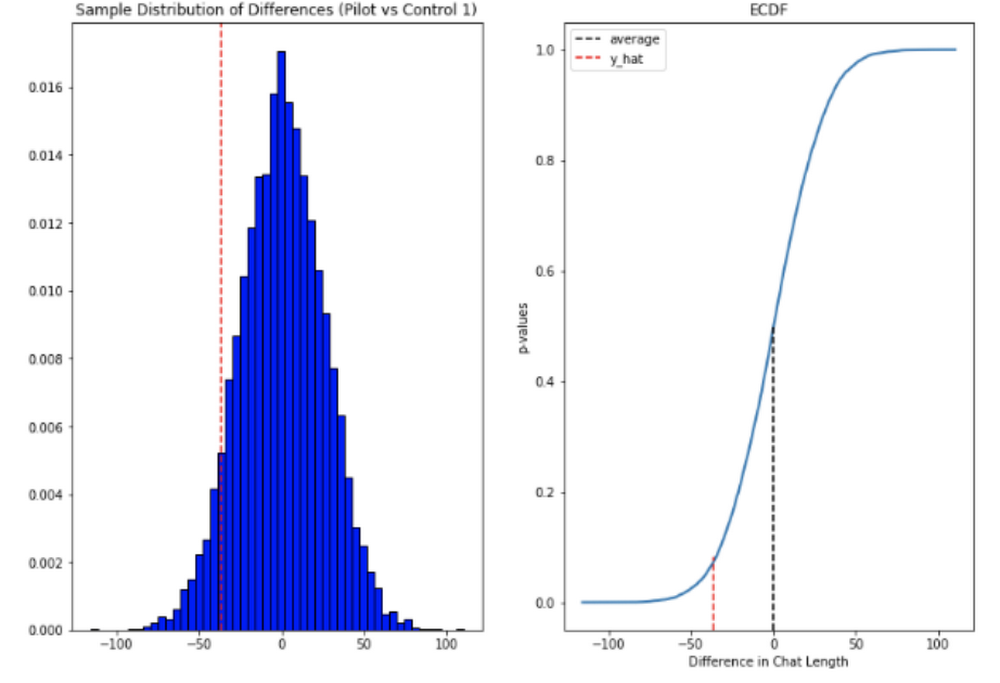
In reference to the number of chat messages we saw techs on average being able to send 5-6 messages more in less time.
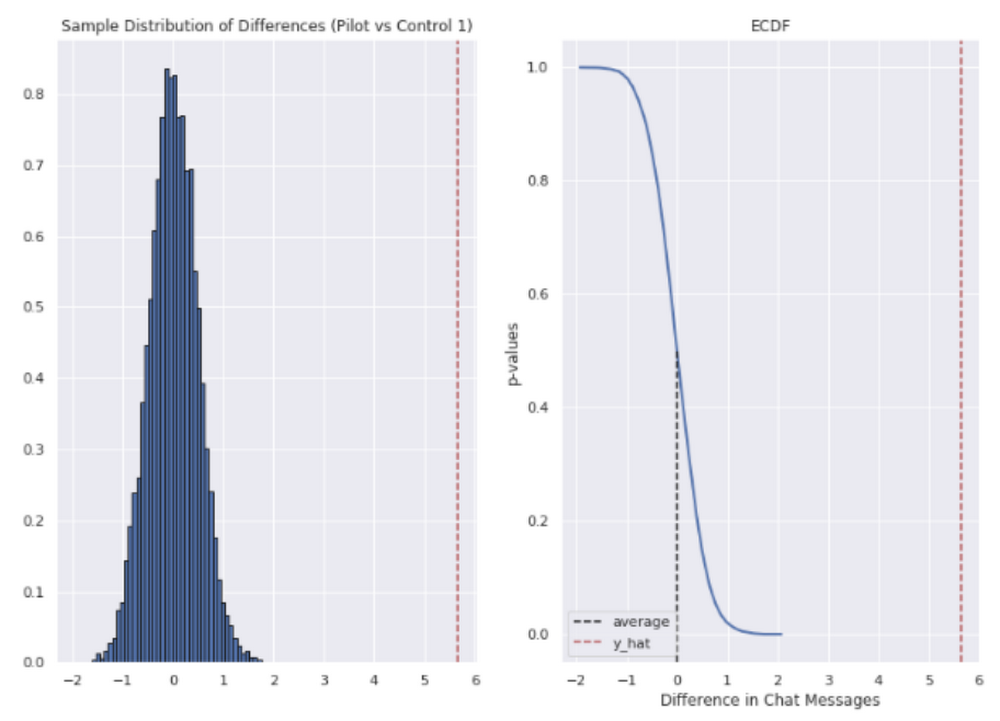
In short, we saw techs were able to send more messages in a shorter period of time. Our results also showed that these improvements increased with support agent tenure, and our more senior techs were able to save an average of ~4 minutes per support interaction.
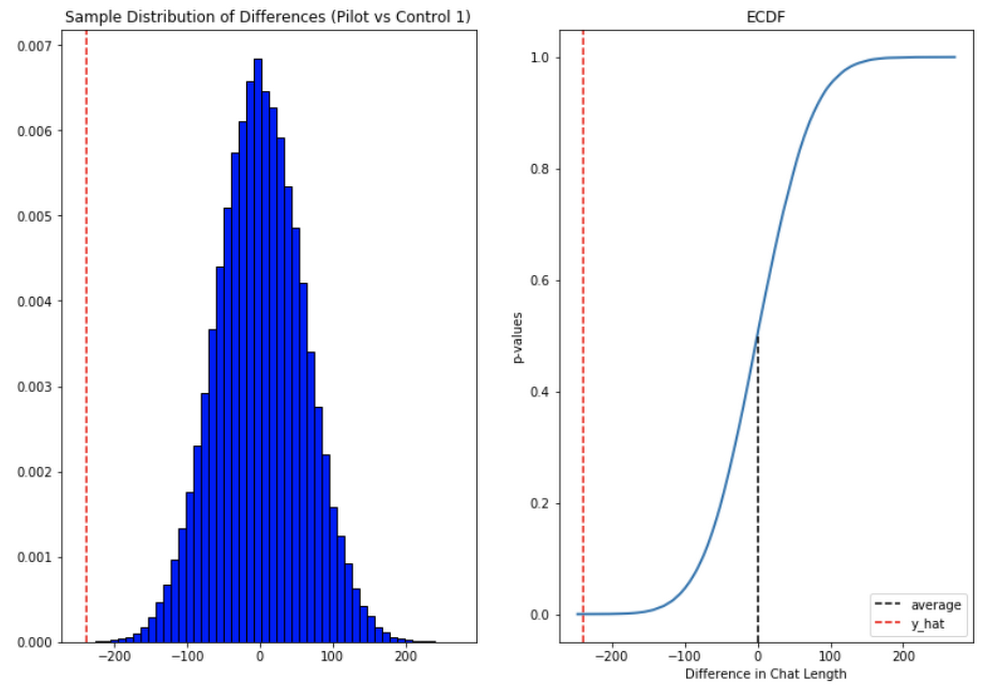
Overall we were pleased with the results. While things weren’t perfect, it looked like we were onto a good thing.
So what’s next for us?
Like any ML project, the better the data the better the result. We’ll be spending time looking into how to provide canonical suggestions to our support agents by clustering results coming from our allow list. We also want to investigate ways of making improvements to the support articles provided by the model, as anything that helps our techs, particularly the junior ones, with discoverability will be a huge win for us.
How can you do this?
A successful applied AI project always starts with data. Begin by gathering the information you have, segmenting it up, and then starting to process it. The interaction data you feed in will determine the quality of the suggestions you get, so make sure you select for the patterns you want to reinforce.
Our Contact Center AI allows tokenization, encoding and reporting, without you needing to design or train your own model, or create your own measurements. It handles all the training for you, once your data is formatted properly.
You'll still need to determine how best to integrate its suggestions to your support system's front-end. We also recommend doing statistical modeling to find out if the suggestions are making your support experience better.
As we gave our technicians ready-made replies to chat interactions, we saved time for our support team. We hope you'll try using these methods to help your support team scale.