Running Anthos inside Google

Bikramjeet Assal
Systems Engineer
Max Saltonstall
Developer Relations Engineer, Google
With everyone and their dog shifting to containers, and away from virtual machines (VMs), we realized that running vendor-provided software on VMs at Google was slowing us down.
So we moved.
Enter Anthos, Google Cloud's managed application platform, and its associated developer tools. Today we'll take you through our process of moving Confluence and Acrolinx from VMs running in our private data center environment over to a fully managed, containerized deployment for Google. Both Confluence and Acrolinx were deployed before on the Google Compute Engine platform and have been used within Google for content management.
In the past, Google used internal systems for allocating application resources, automating replication and providing high availability for enterprise applications, but these systems relied on customized infrastructure and they were often incompatible with enterprise software.
The many frustrations that came with running enterprise applications on VMs included:
Service turnup times in the order of days
Hard-to-manage infrastructure and workloads programmatically
Challenges with VM monoliths management (as compared to microservices)
Reliable rollback of application install/upgrade failures
Challenges with enforcing security policies at scale
… and many others
To mitigate these frustrations, we made the shift to an industry-standard, universally available managed platform: Kubernetes.
Kubernetes and Anthos
Deploying Kubernetes gave us the ability to configure, manage, and extend workloads running on containers rather than VMs. The good news was that it could handle the scale of our deployments with ease.
Anthos is Google Cloud's platform of tools and technologies designed to ease the management of containerized workloads, whether running on Google Cloud, other clouds, or on-premises. It brings configuration management, service management, telemetry, logging and cluster management tooling. In addition, it saves operational overhead for our application teams.
As our vendor-provided software became compatible with containerization, we could build on 15 years of experience running containerized workloads and enjoy the perks of using a fully managed cloud service for our applications.
Adopting Anthos gave us some big benefits right away:
Automated resource provisioning
Application lifecycle management
Security Policies Management
Config-as-code for workload state
This removed substantial manual toil from our team, freeing them up for more productive work. Using Anthos Config Connector we could express the compute, networking and storage needs through code, allowing Anthos to allocate them without manual interaction. We also relied on Anthos to administer creating Kubernetes clusters and manage a single admin cluster that would host the Config Connector. This gave us simpler orchestration when we needed to create new Kubernetes clusters to run our applications.
How we modernized operations
Our continuous integration and continuous deployment process benefitted from Anthos as well. By using Anthos Config Management (Config Sync), a multi-repository configuration sync utility, we can automate the process of applying our desired configuration to the Kubernetes clusters that we would otherwise have applied manually before via kubectl. The multi-repo Config Sync provides a consistent experience when managing both the common security policies across clusters and the workload specific configs that are namespace-scoped.
Config Sync is a Kubernetes Custom Resource Definition (CRD) resource which is installed on a user cluster by GKE Hub.
GKE Hub provides networking assistance within Anthos, and lets you logically group together similar GKE clusters. Once the clusters are registered with a GKE Hub, the same security policies can be administered on all the registered clusters. Onboarding a new application then wouldn’t incur any additional overhead, because the same security policies would be applied automatically.
The resulting clusters and administration of these applications looks like this:
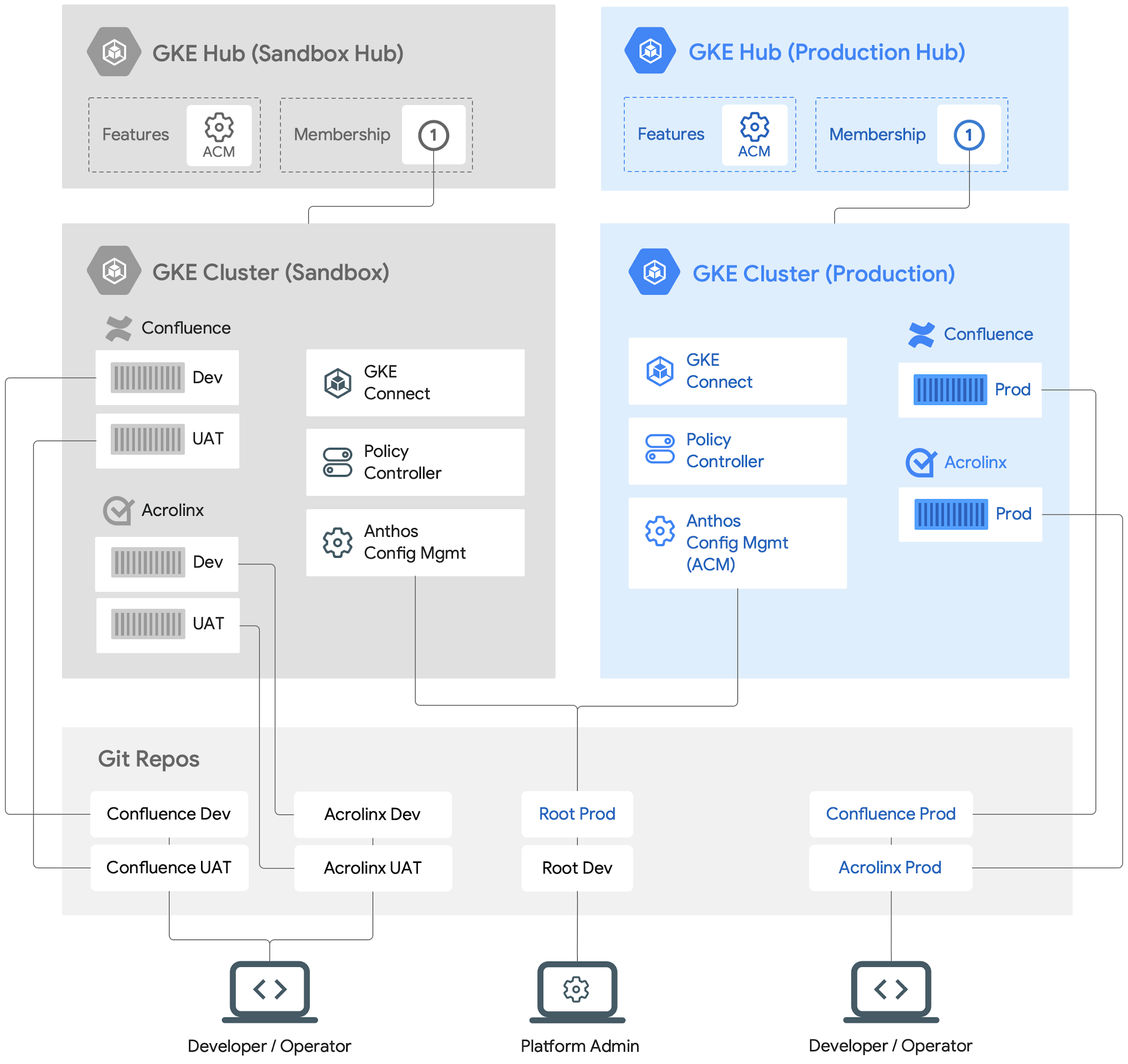
A high level view of Anthos-managed workloads running on GKE clusters
Our updated deployment process
We've deployed a variety of third-party applications on Anthos. Today, we'll walk you through how we set up Confluence and Acrolinx.
To provision and deploy, we need to:
Ensure that all the configs (both security policies and workload configs) are stored in a single source of truth (i.e Git repos). Any changes must be reviewed and approved by multiple parties to prevent unilateral changes.
Deploy and enforce our required security policies.
Express the desired state of workload configs in a Git repo.
Deploy a Continuous Integration and Continuous Deployment pipeline to ensure that changes to the configs are tested before committing them to a Git repo. Such configs will then be applied to the target clusters to ensure the desired state of both the applications.
Even though we're running multiple segmented workloads, we can apply common security policies to them all. We also delegate application deployment to the developers while maintaining security guardrails to prevent mistakes.
How we set up Anthos clusters
We know what we want to deploy, and how to protect them. Let's dig into how we can set up those clusters with Terraform and then how to make sure all our security policies are applied. Once that is complete we can let the developer or operator manage any future changes to the application, while the cluster admin retains control of any cluster policy changes.
We'll register the cluster with the right GKE Hub, then apply our desired configuration to that cluster, and finally deploy the applications to their namespaces.
Let’s start with the prod GKE cluster. We can create it using these Terraform templates,then cluster with GKE Hub using:Next, we will enable the ACM/Config Sync feature for the GKE Hub, hub-prod, using the gcloud command-line:
As shown above, this will configure Config Sync on the prod GKE cluster with the relevant root Git repo (root-prod).
After creating the GKE clusters, we will set up cluster namespaces to deploy Confluence and Acrolinx:
Here's one way the root and namespace repos can be organized in a root-prod structured repo.
All the cluster-scoped resources will be kept in the cluster directory while all the namespace scoped resources for the given applications will be kept in each of the namespaces sub-directories. This separation allows us to define the common cluster scoped security policies at a higher level while still defining application configs at each application namespace level. The cluster admins can own the security policies while delegating namespace ownership to the developers.
We now have a GKE cluster prod that is registered with a GKE Hub. Since the cluster is registered with the GKE Hub with Config Sync enabled, the security policies now can be applied on this cluster.
Deploying changes to applications
In order for Config Sync to apply config changes to resources of Confluence and Acrolinx applications, each of the Namespace resources and Namespace repos must first be configured.
Looking at an example of a root-prod Git repo as shown above and the respective Namespaces repos, RepoSync resources and how Confluence and Acrolinx application resources will be managed by Config Sync in the prod GKE cluster.
The following is an example of a Namespace and RepoSync resource in the confluence-prod directory.
Config Sync will read the Namespace config file and create confluence-prod Namespace in the same prod GKE cluster.
The RepoSync resource sets up a process to connect to the Git repo to find configuration information that will be used by the Confluence application.
We are now ready to create Kubernetes resources for Confluence from its namespace Git repo.
Next, we can deploy a StatefulSet resource that defines the container’s spec (CPU, RAM, etc.) for running Confluence app in the confluence-prod namespace repo:
After submission to the repo, Config Sync will read the StatefulSet and deploy the image based on the resources listed.
Our security practice
Every organization has a requirement to ensure that the workloads are made secure without any additional efforts from the developers and that there is a central governing process that enforces such security policies across all the workloads. This ensures that everyone follows best practices when deploying workloads. It also reduces much of the burden and cognitive load from the developers when ensuring that workloads follow such security principles and policies.
Historically, when running applications on VMs, it has been traditionally difficult to micro-segment applications, apply a different set of policies to the micro-segmented applications and/or based on workload identities. Some examples of such policies are: whether an application is built and deployed in a verifiable manner; preventing privilege escalation (e.g setuid binaries) and applying that config for a group of workloads etc.
With the advent of Kubernetes and standards such as OPA (Open Policy Agent), it is possible now to micro-segment workloads, define a set of policies that can enforce certain constraints and rules at the workload identity level for a group of similar workload resources. This is one such library of OPA Constraints that can be used to enforce policy across Cluster workloads.
Policy Controller enables the enforcement of fully programmable policies. You can use these policies to actively block non-compliant API requests, or simply to audit the configuration of your clusters and report violations. Policy Controller is based on the open source Open Policy Agent Gatekeeper project and comes with a full library of pre-built policies for common security and compliance controls.This will allow the developers to focus on just the application lifecycle management while the platform admins will ensure that such security policies are enforced on all the registered clusters and workloads.
Conclusion
In the end we got to a much better place by deploying our applications with Anthos, backed by Kubernetes.
Our security policies were enforced automatically, we scale up and down with demand, and new versions could be deployed smoothly. Our developers enjoyed faster workflows, whether spinning up a new environment or testing out an update for stability. Provisioning got easier too, with less overhead for the team, especially as deployments grew to service the whole of Google.
Overall we're quite happy with how we improved developer productivity with faster application turnup times, going from days to just hours for a new application. At the same time we’re better able to reliably enforce policies that ensure that applications are hosted in a secure and reliable environment.
We're glad we can share some of our journey with you; if you want to try it out yourself, get started with Anthos today.




