Cloud SQL for PostgreSQL data cache under the hood
Virender Singla
Database Engineer
Data is the lifeblood of the organization. Being able to make quick, accurate and actionable decisions based on authoritative data enables enterprises to offer differentiated services and improve customer satisfaction. The rise of generative AI has only further amplified this.
It’s therefore important that your database provides near-real-time performance when interacting with operational data. For PostgreSQL databases, we offer Cloud SQL for PostgreSQL Enterprise Plus edition, which offers improved performance out of the box, improved data protection (35 days of PITR) and improved availability (99.99% SLA and near zero downtime maintenance.)
Cloud SQL for PostgreSQL Enterprise Plus edition also includes an innovative data cache feature, which significantly improves read performance. The data cache is a read cache that uses a server-side SSD to cache data. Because it is co-located with compute in the server, data accesses have low latencies and high throughput. Workloads that are typically limited by read throughput and latency will therefore see significant benefits when using the data cache.
In this blog post, we will explore how the data cache works, its internal mechanisms, and the types of workloads that will benefit the most from it.
How does the data cache work?
Cloud SQL uses high-performance, low-latency local solid-state drives as a caching layer for data storage disks. Think of the data cache as an extension to the shared buffers in PostgreSQL. This means queries avoid unnecessary network hops and are not limited by the underlying storage. The data cache is bigger than the physical memory in the instance, which means that more of the working set fits inside the server. This helps queries to achieve a much better cache-hit ratio.
The table below gives the sense of size of different storage layers for a 32 vCPU instance.

The data cache size is fixed for an instance and is a function of the number of vCPUs configured. The table below summarizes the data cache size for different vCPU configurations:
What workloads benefit from the data cache?
Workloads that benefit from the data cache feature are read workloads where the total dataset does not fit entirely into memory. This includes but is not limited to:
-
Workloads that are sensitive to read latencies (for example, key-value lookups)
-
Workloads that are sensitive to read throughput (for example, table scans)
-
Gen AI workloads that use vectors for similarity searches
Enabling the data cache
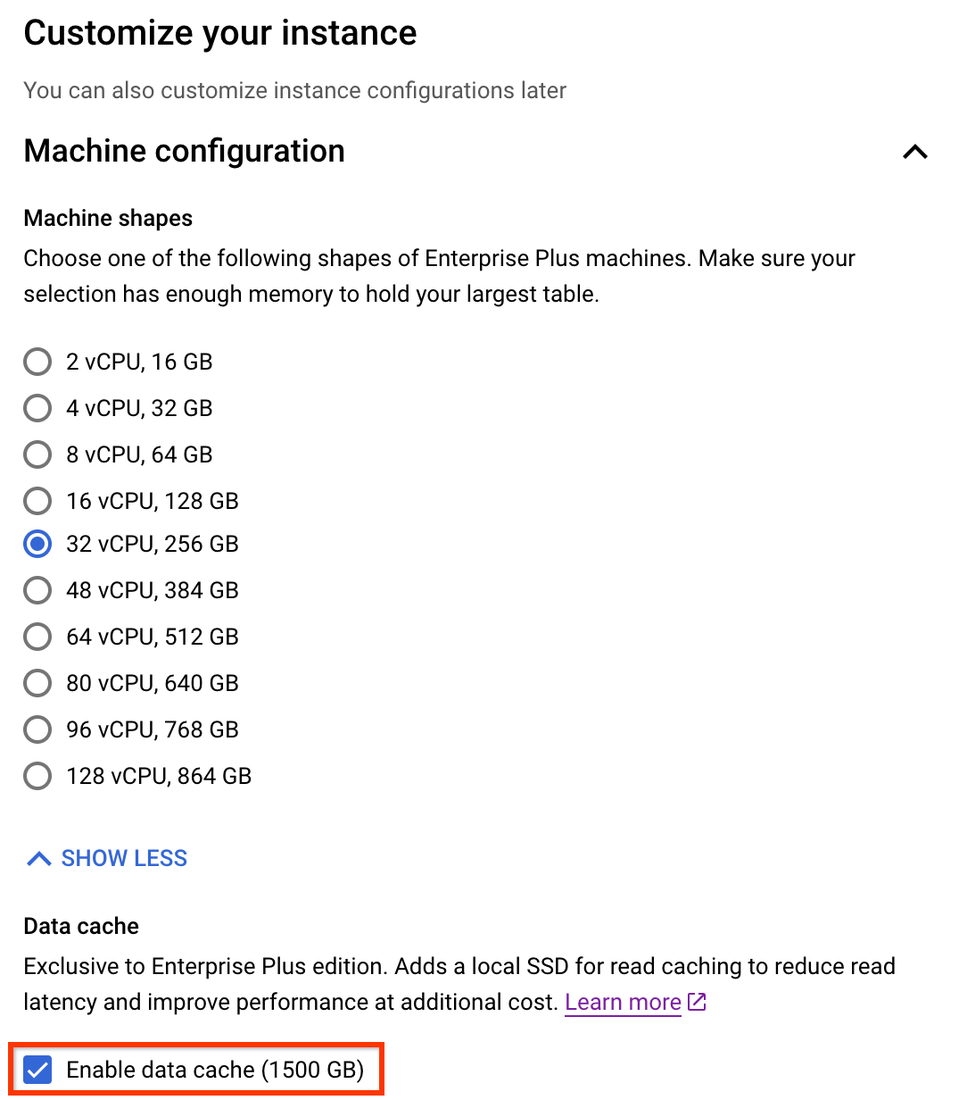
In the Cloud SQL console, go to SQL → Create Instance → Choose PostgreSQL and then choose Enable data cache. The data cache can also be enabled via gcloud and Terraform.
Monitoring
Cloud SQL for PostgreSQL also includes four new metrics for data cache observability:
-
Data cache quota: Maximum data cache size
-
Data cache used: Data cache used
-
PostgreSQL data cache hit count: Total number of data cache hits
-
PostgreSQL data cache miss count: Total number of data cache misses
Turbocharge your read-heavy workloads
In this blog we discussed how the data cache improves read performance. We also discussed how to easily monitor data cache operations. To learn more about Cloud SQL for PostgreSQL data cache, or to get started, check out the documentation.