Decommission your legacy Apache Cassandra stack and build for the future with Spanner
Nitin Sagar
Product Manager
An increasing number of customers are migrating to Spanner from legacy NoSQL environments like Apache Cassandra. The strategic drivers are evident: a markedly lower total cost of ownership (TCO), elastic scalability, and near-zero maintenance overhead.
With the general availability of the native endpoint enabling Cassandra Query Language (CQL) APIs on Spanner, your existing Cassandra applications can now leverage Spanner’s enterprise foundation, featuring strong consistency, virtually limitless scale, and 99.999% availability — all while utilizing familiar CQL.
Better yet, migrating your application to Spanner with the CQL interface typically requires only a one-line code change, as your existing CQL statements remain valid. Combined with our integrated, high performance bulk and live migration tools, your transition from Cassandra to Spanner is simple.
Beyond NoSQL: Strategic solutions for Cassandra Users
While the CQL API facilitates the move, Spanner addresses the fundamental data integrity and operational constraints inherent in traditional Cassandra architectures:
-
Global ACID transactions: Minimize concerns regarding eventual consistency. Achieve comprehensive global ACID transactions to help ensure data integrity at any scale.
-
Powerful indexing: Strongly consistent secondary indexes support complex query patterns with built-in optimization and no integrity risks.
-
Rich SQL: Utilize a sophisticated SQL interface that supports joins and aggregations.
-
High reliability: Benefit from 99.99% availability in regional setups and 99.999% in multi-regional configurations.
-
Compliance and latency: Simplify data residency compliance with geo-partitioning, delivering low-latency local reads and writes to a global user base.
-
Built-in observability: Access a suite of performance metrics and charts directly in the Google Cloud console at no additional cost.
The native CQL endpoint provides a clear pathway to decouple your existing Cassandra applications and modernize them using the full power of Spanner. Let’s look at the next steps after migrating your data and applications from Cassandra to Spanner.
Tweak Spanner for your specific workload
Following your migration, here’s how to optimize your Spanner environment for your workload.
1. Optimize costs and operational efficiency
2. Achieve low latencies
We continuously enhance Spanner's performance to support mission-critical, high-concurrency workloads.
-
Single-digit millisecond performance: Spanner consistently delivers under 5ms latency for both read and write operations.
-
Repeatable read isolation: This feature utilizes optimistic concurrency to reduce latency and transaction aborts in read-heavy, low-contention scenarios.
-
Read leases: Enable strongly consistent reads in multi-region instances without cross-region coordination, maximizing node efficiency and performance.
3. Prepare for peak traffic surges
For planned events like marketing launches or massive data ingestions, you can proactively manage capacity:
-
Manual split APIs: While Spanner handles data partitioning automatically, the pre-splitting capability allows you to exactly define how your database distributes data ahead of peak loads. This helps ensure immediate utilization of new capacity for stable performance.
4. Isolate operational and analytical pipelines
Prevent resource contention by isolating BI and ETL processes from core operations:
-
Dedicated resources: Leverage read-only replicas and directed reads to achieve workload isolation.
-
Advanced analytics: Spanner provides high-performance operational analytics through its columnar engine, and integrates with BigQuery via Data Boost, reverse ETL, and continuous queries.
Deconstruct your Cassandra ecosystem
Migrating from Apache Cassandra to Spanner is a strategic opportunity to decouple your architecture from a complex web of sidecar utilities. While the Cassandra-compatible API serves as the entry point, the true value lies in collapsing the operational "Cassandra tax" into a unified, managed multi-model ecosystem.
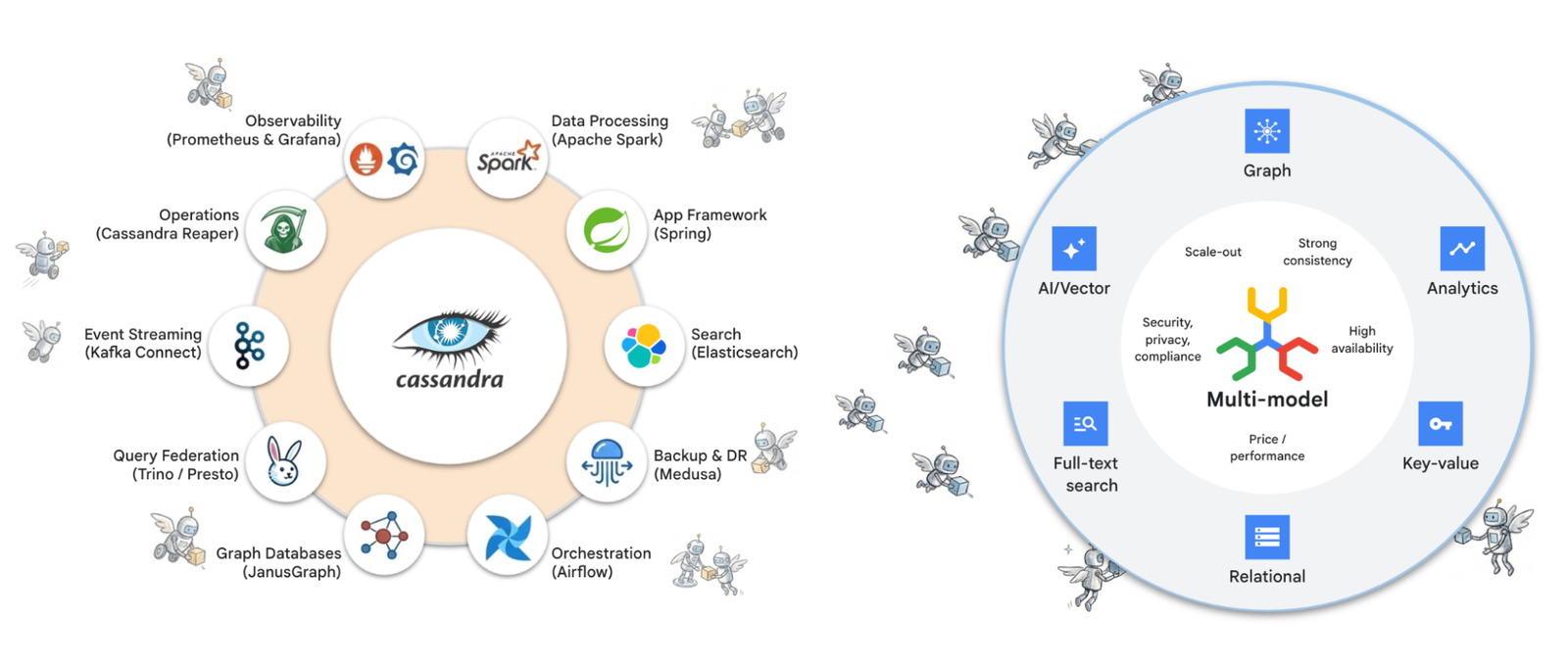
Here’s a quick guide to drastically lowering your TCO while significantly boosting performance.
1. Transition easily via connectors
Minimize initial friction by leveraging the Spanner Cassandra Adapter and connectors to port management and application layers with near-zero code modifications:
-
Orchestration: Maintain your existing Airflow DAGs by redirecting to the Spanner proxy.
-
Application frameworks: Transition from Spring Data Cassandra to Spring Data Spanner, preserving established repository patterns while unlocking a superior transaction model.
-
Data processing: Continue leveraging Apache Spark by connecting to Spanner’s native CQL endpoint or using the specialized Spanner Connector for Spark.
2. Retire sidecars via native integrations
Cassandra demands a "babysitting" layer that Spanner automates. Decommission legacy maintenance tools and unlock Spanner’s advanced capabilities:
-
Anti-entropy: Decommission Cassandra Reaper. Spanner’s Paxos-based replication manages consistency natively, removing the need for manual repair cycles.
-
Data protection: Replace Medusa with Spanner-native backups. Move away from fragile SSTable snapshots to reliable, Point-in-Time Recovery (PITR).
-
Observability: Swap complex JMX exporters for Cloud Monitoring. Focus on high-value metrics like Query Insights and Lock Statistics rather than maintenance debt.
-
Integrated search: Replace external Elasticsearch sidecars and complex ETL pipelines with Spanner full-text search to eliminate indices-synchronization issues.
-
Modern streaming: Swap legacy CDC for Spanner change streams, providing native integration with Dataflow and Kafka.
-
Graph analytics: Port JanusGraph to Spanner Graph to run openCypher queries directly on operational data without complex ETL processes.
-
Query federation: Replace Trino/Presto with BigQuery Federation via Data Boost. Join real-time transactional data with massive data lakes without impacting production I/O.
Build the future with Spanner’s multi-model advantage
Spanner is the definitive always-on database that integrates relational, key-value, graph, search, and vector search capabilities into a single, interoperable platform. By transitioning to Spanner, you eliminate the overhead of managing fragmented databases and unlock the ability to develop innovative applications on a unified data foundation. Build new applications or modernize your legacy applications to take full advantage of Spanner.
Get started today
Ready to refocus on building rather than managing? Initiate your migration today and experience the power of Spanner with your existing Cassandra Query Language.
-
Codelab: Gain practical experience with the native CQL endpoint.
-
Free trial: Explore Spanner for 90 days or start for as little as $65/month for a production-ready instance that scales without disruption.
- Migration guide: Access deep technical documentation and comprehensive migration resources.


