Monitoring feature attributions: How Google saved one of the largest ML services in trouble
Ankur Taly
Research Scientist
Kaz Sato
Developer Advocate, Cloud AI
An emergency in the largest MLOps at Google
Claudiu Gruia is a software engineer at Google who works on machine learning (ML) models that recommend content to billions of users daily. In Oct 2019, Claudiu was notified by an alert from a monitoring service. A specific model feature (let us call this feature F1) had reduced in importance. The importance of the feature is measured using the concept of Feature Attribution, the influence of the feature on the model's predictions. This reduction in importance was associated with a large drop in the model's accuracy.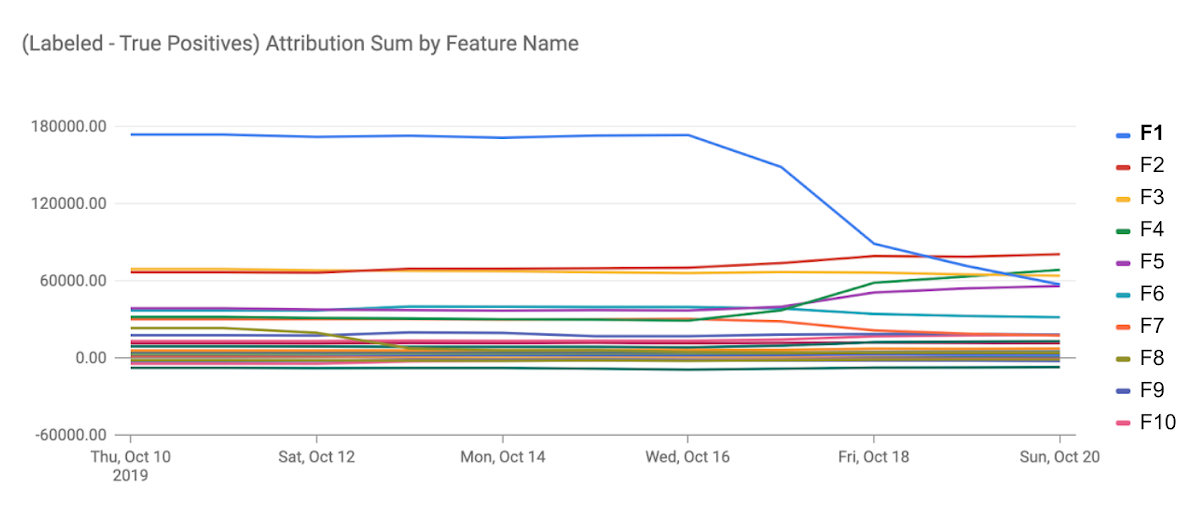
In response to the alert, Claudiu quickly retrained the model, and the two other features (F4 and F6 below) rose in importance, effectively substituting for F1, eliminating the drop in model quality. Had it not been for the alert and Claudiu's quick fix, the user-experience of a large consumer service would have suffered.

After the retraining, the feature F4 and F6 covered the F1 loss
Monitoring without the ground truth
So what happened? F1 was a feature generated by a separate team. On further investigation, it was found that a certain infrastructure migration caused F1 to significantly lose coverage and consequently its attribution across examples.
The easiest way to detect this kind of model failure is to track one or more model quality metrics (e.g., accuracy), and alert the developer if the metric drops below a threshold. But unfortunately, most model quality metrics rely on comparing the model’s prediction to "ground truth" labels which may not be available in real-time. For instance, in tasks such as fraud detection, credit lending or estimating conversion rates for online ads, the groundtruth for a prediction may lag by days, weeks or months.
In the absence of the ground truth, ML engineers at Google rely on proxy measures of model quality degradations, derived using model inputs and predictions as two available observables. There are two main measures:
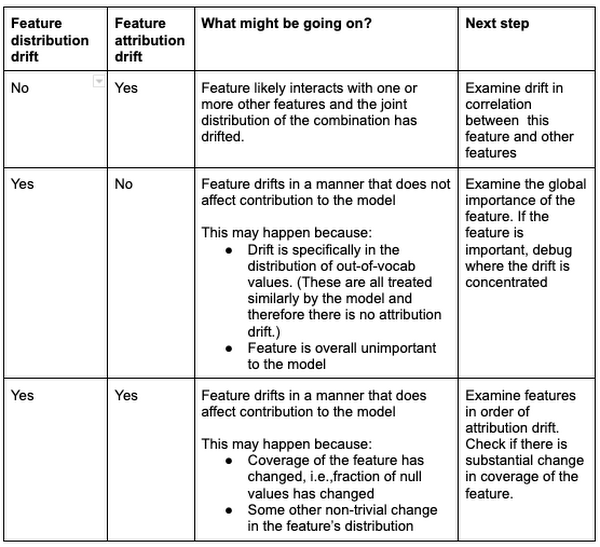
- Feature Distribution monitoring: detecting the skew and drift of feature distribution
- Feature Attribution monitoring: detecting the skew and drift of feature importance score
In the recent post Monitor models for training-serving skew with Vertex AI, we explored the first measure, Feature Distribution monitoring, for detecting any skew and anomalies happening in the feature itself at the serving time (in comparison to training or some other baseline). In the rest of this post, we discuss the second measure, Feature Attribution monitoring, which has also been successfully used to monitor large ML services at Google.
Feature Attributions monitoring
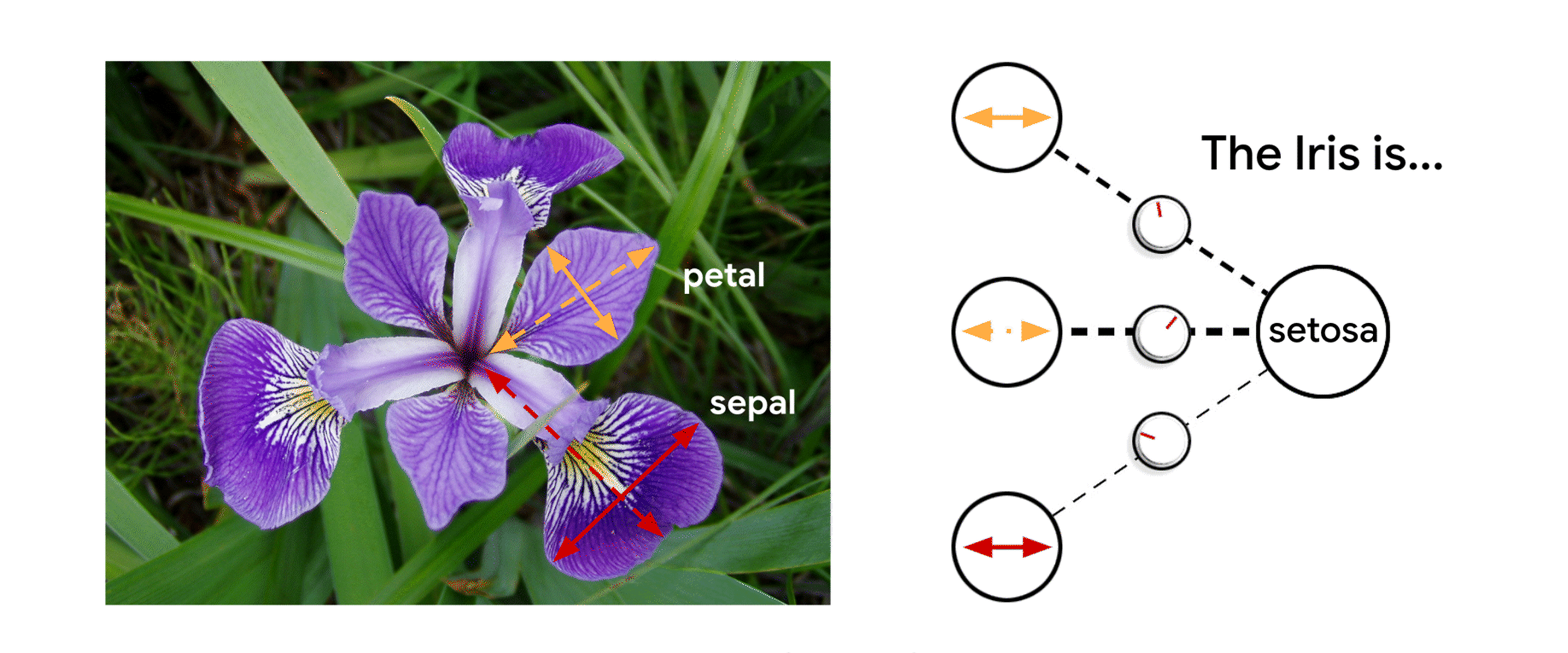
Feature Attributions is a family of methods for explaining a model’s predictions on a given input by attributing it to features of the individual inputs. The attributions are proportional to the contribution of the feature to the prediction. They are typically signed, indicating whether a feature helps push the prediction up or down. Finally, attributions across all features are required to add up to the model’s prediction score.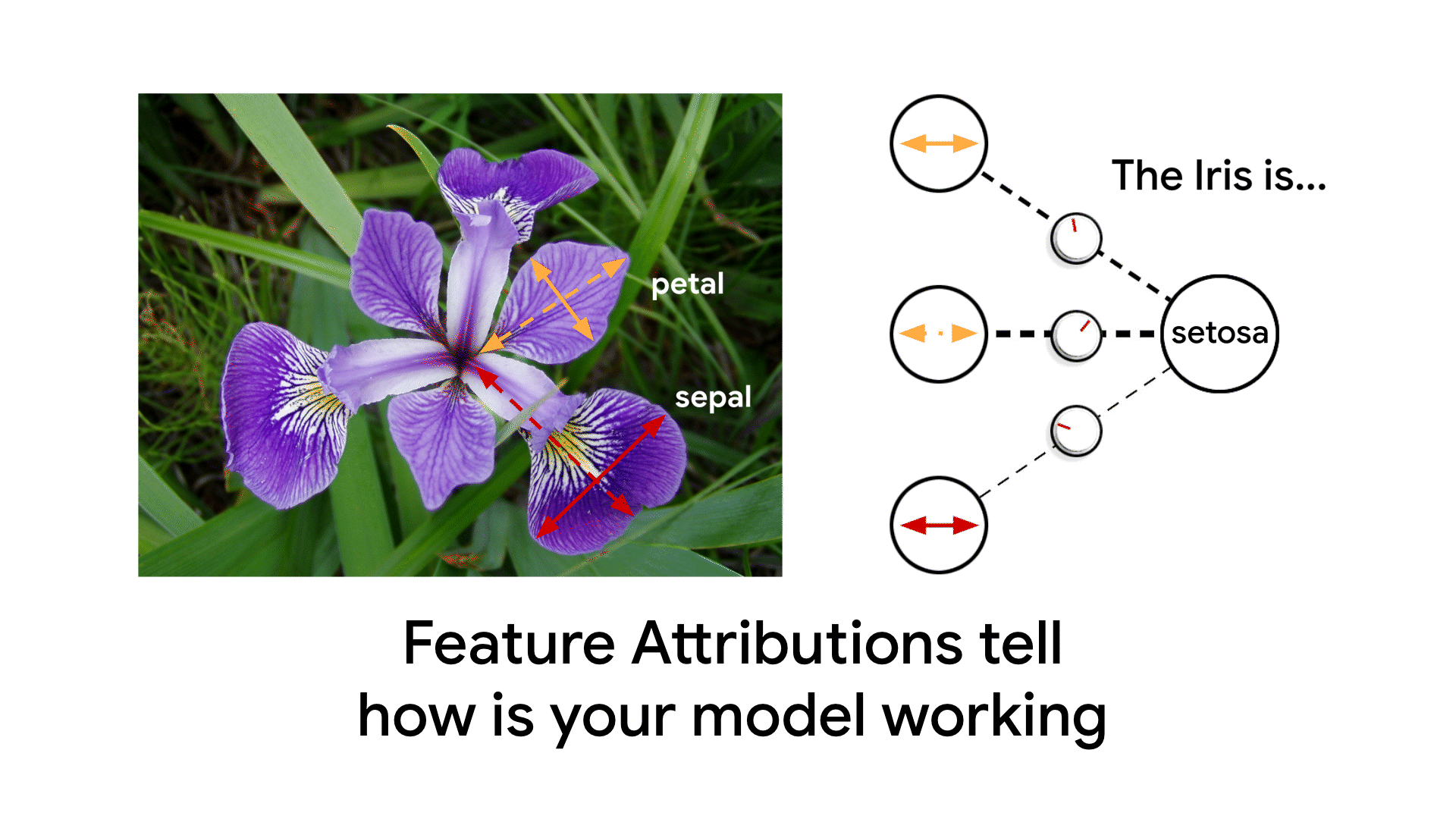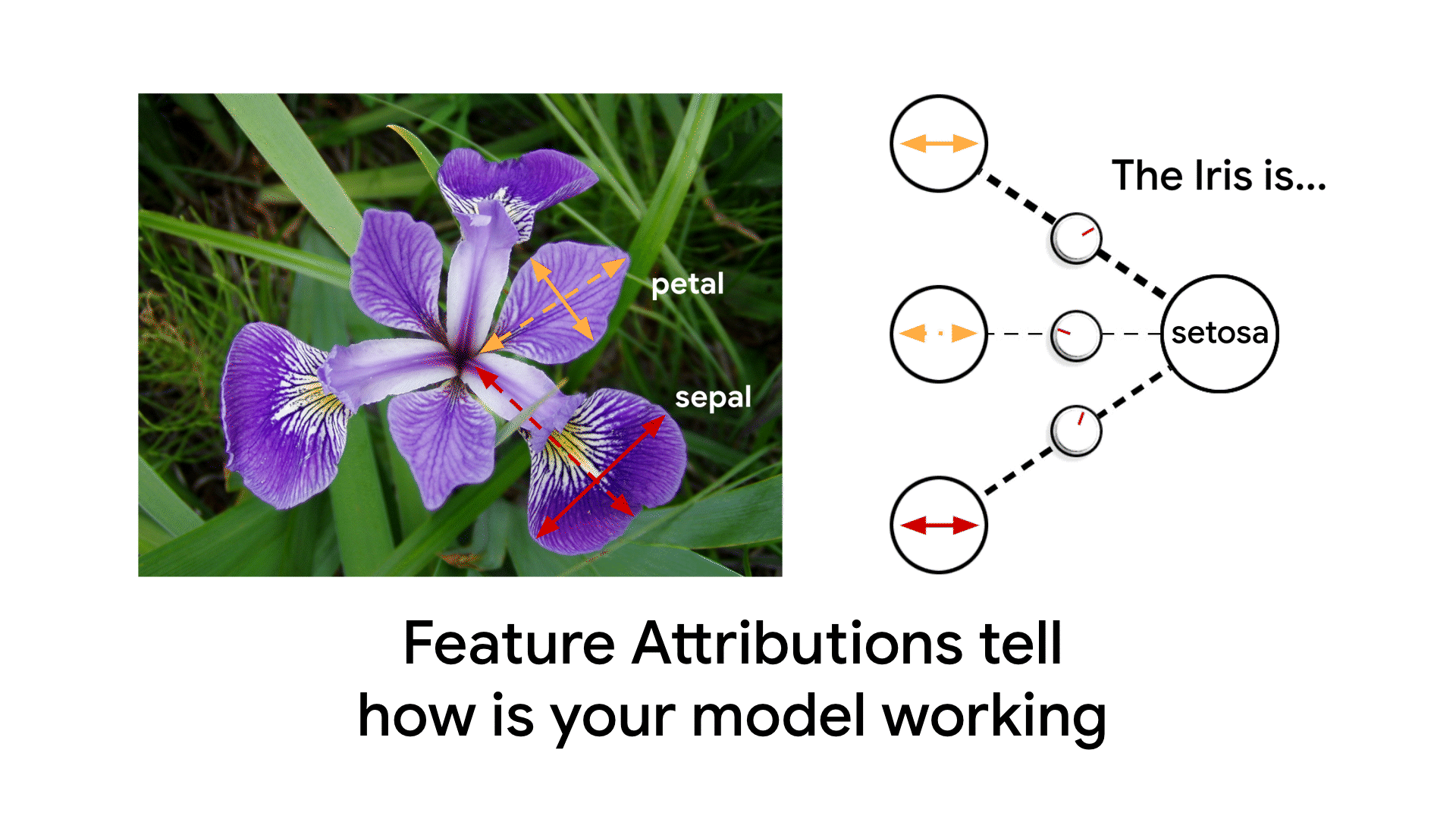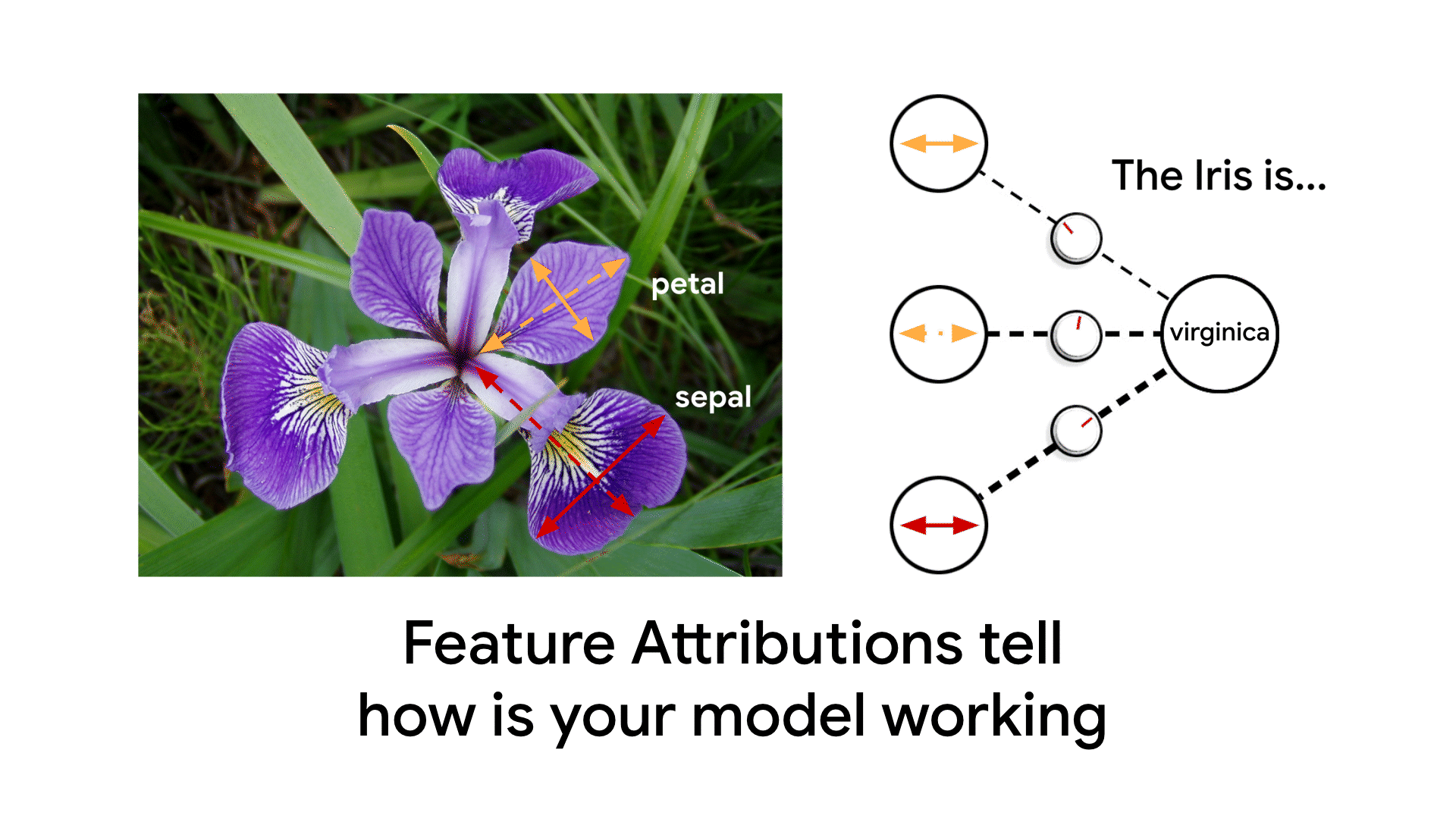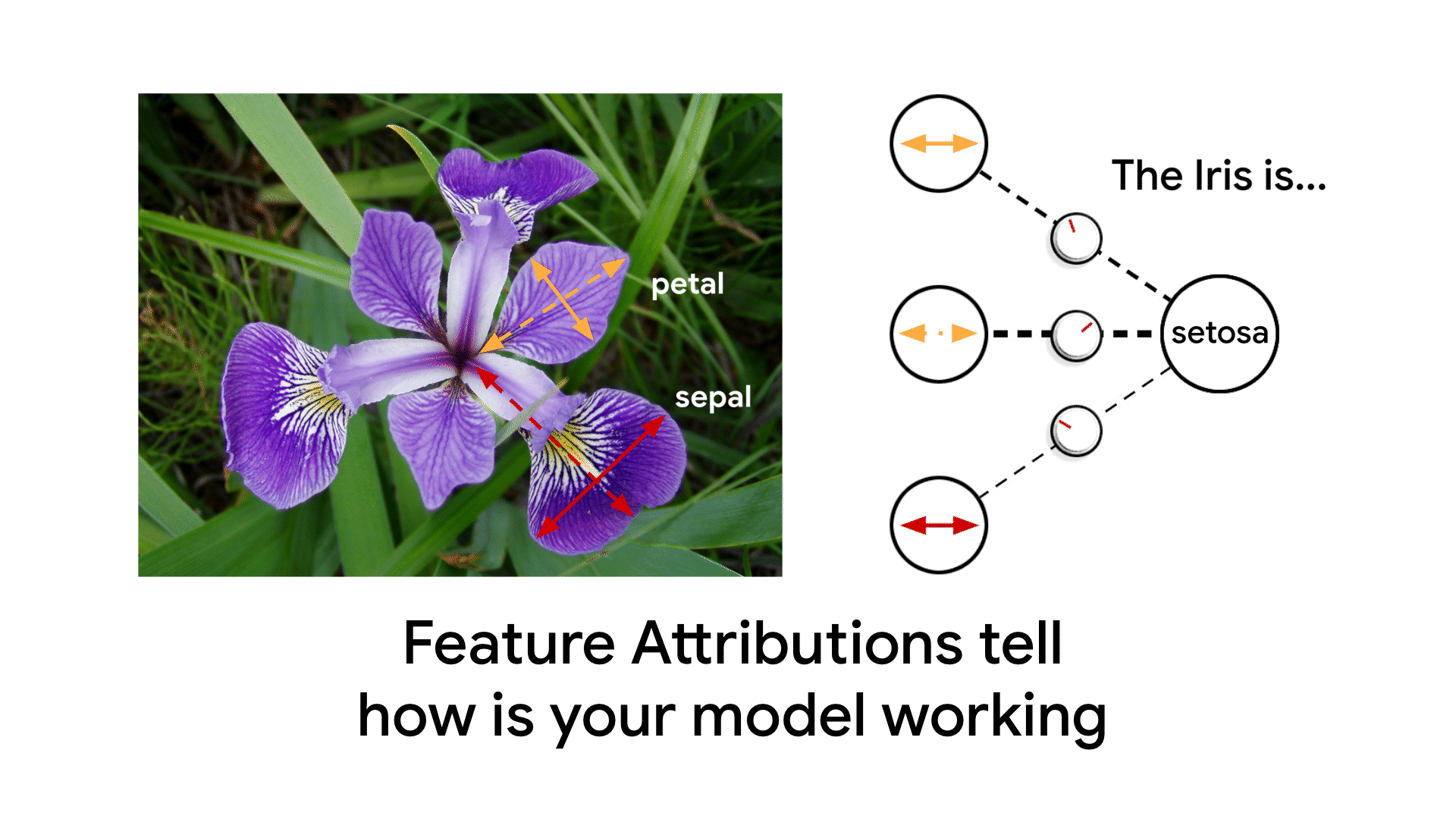
Feature Attributions have been successfully used in the industry and also at Google to improve model transparency, debug models, and assess model robustness. Prominent algorithms for computing feature attributions include SHAP, Integrated Gradients and LIME. Each algorithm offers a slightly different set of properties. For an in-depth technical discussion, refer to our AI Explanations Whitepaper.
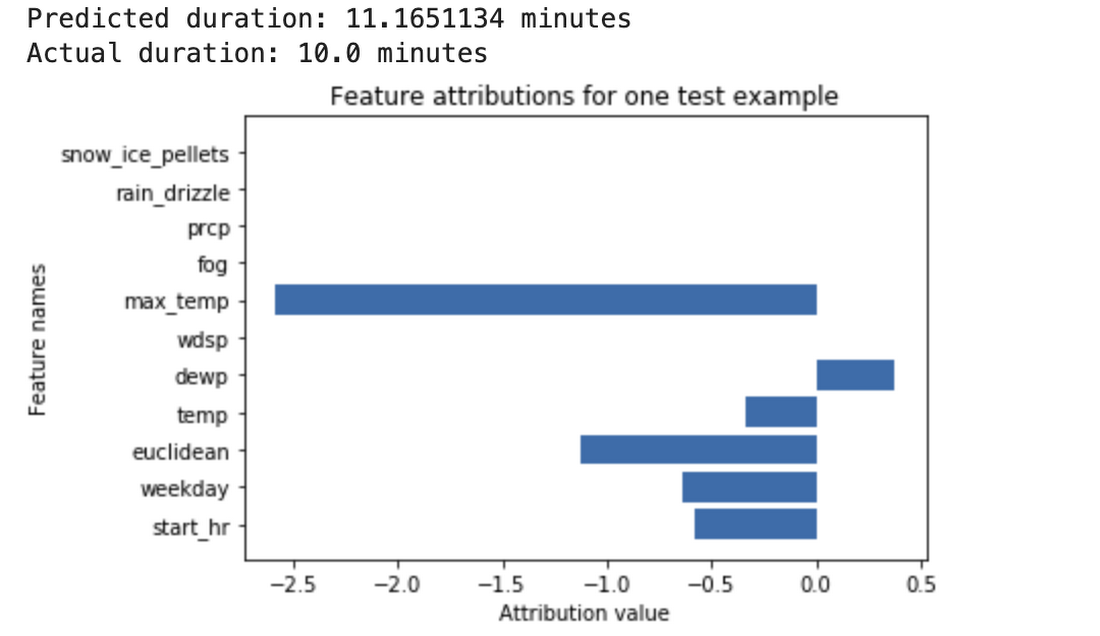
An Example of Feature Attributions
Monitoring Feature Attributions
While feature distribution monitoring is a handy tool, it suffers from the following limitations:
(1) Feature drift scores do not convey the impact the drift has on the model’s prediction (2) There is no unified drift measure that works across different feature types and representations (numeric, categorical, images, embeddings, etc.), (3) Feature drift scores do not account for drift in the correlation between features.
To address this, on September 10th, Vertex Model Monitoring added new functionality to monitor feature attributions. In contrast to feature distribution monitoring, the key idea is to monitor the contribution of each feature to the prediction (i.e., attribution) during serving to report any significant drifts relative to training (or some other baseline). This has several notable benefits:
- Drift scores correspond to impact on predictions. A large change in attribution to a feature by definition means that the feature’s contribution to the prediction has changed. Since the prediction is equal to the sum of the feature contributions, large attribution drift is usually indicative of large drift in the model predictions. (But there may be false positives if the attribution drifts across features cancel out leading to negligible prediction drift. For more discussion on false positives and false negatives, please see Note #1)
- Uniform analysis units across feature representations. Feature attributions are always numeric, regardless of the underlying feature type. Moreover, due to their additive nature, attributions to a multi-dimensional feature (e.g., embeddings) can be reduced to a single numeric value by adding up the attributions across dimensions. This allows using standard univariate drift detection methods for all feature types.
- Account for feature interactions. Attributions account for the feature’s contribution to the prediction, both individually and via interactions with other features. Thus, distribution of feature attributions may change, even if the marginal distribution of the feature does not change but its correlation with the features it interacts with changes.
- Monitor feature groups. Since attributions are additive, we can add up attributions to related features to obtain attribution to a feature group. For instance, in a house pricing model, we can combine the attribution to all features pertaining to the location of the house (e.g., city, school district) into a single value. This group-level attribution can then be tracked to monitor for changes in the feature group.
- Track importances across model updates. Monitoring attributions across model retraining helps understanding how the relative importance of a feature changes with model retraining. For instance, in the example mentioned in the beginning, we noticed that features F4 and F6 stepped up in importance after retraining.
Enabling the service

Vertex Model Monitoring now supports Feature Attributions
Once a prediction endpoint is up and running, you can turn on skew or drift detection for both Feature Distibution and Feature Attributions by running a single gcloud command like the following; no need for any pre-processing or extra setup tasks.
Here are the key parameters:
- emails: The email addresses to which you would like monitoring alerts to be sent
- endpoint: the prediction endpoint ID to be monitored
- prediction-sampling-rate: This parameter controls the fraction of the incoming prediction requests that are logged and analyzed for monitoring purposes
- feature-thresholds: Specify which input features to monitor Feature Distribution, along with the alerting threshold for each feature.
- feature-attribution-thresholds: Specify which input features to monitor Feature Attributions, along with the alerting threshold for each feature.
You can also use the Console UI of setup the monitoring when creating a new Endpoint:
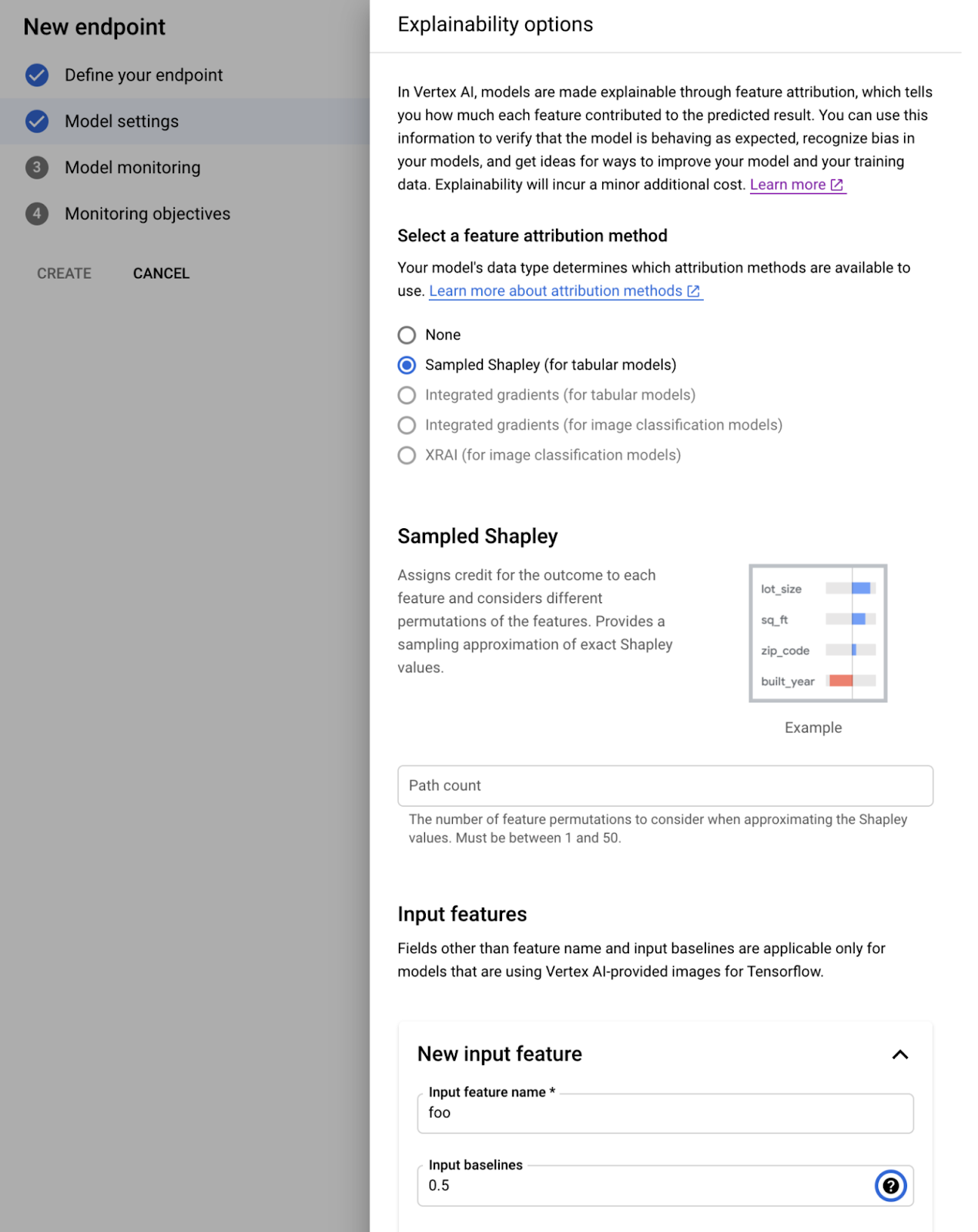
Using Console UI to set up a Feature Attributions and Feature Distribution monitoring
For the detailed instructions on how to set up the monitoring, please refer to the documentation.
After enabling it, you would see some alerts on the console like below whenever any feature attribution skews or drifts are detected, and also receive an email for the same. The Ops engineer can then take appropriate corrective action.
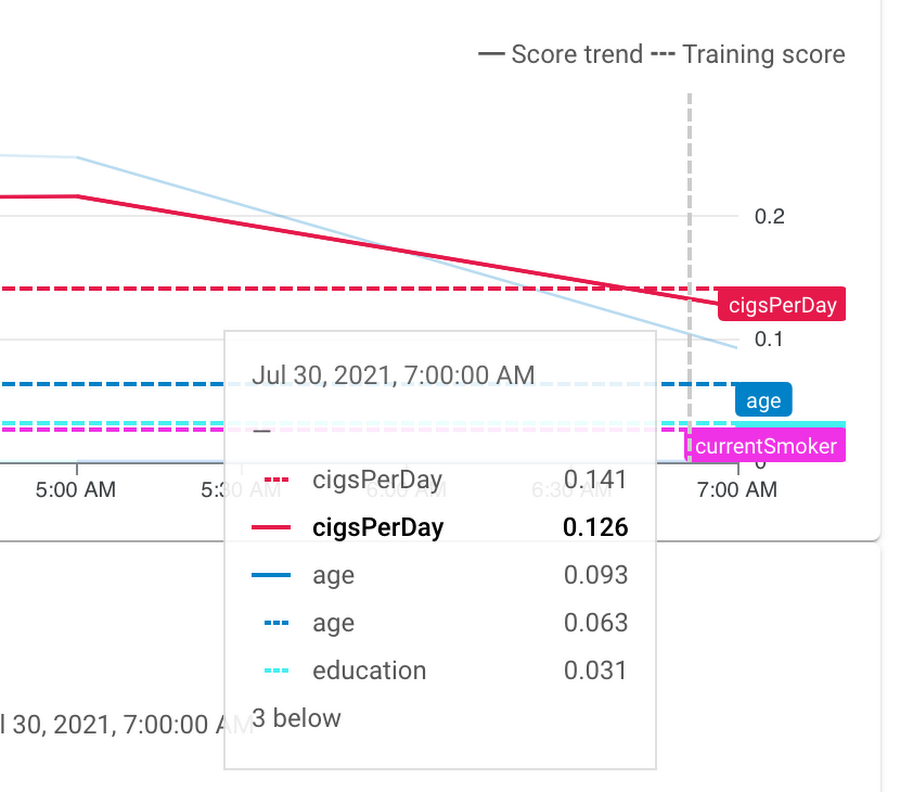

Example: The feature attribution of "cigsPerDay" has crossed the alert threshold
Design choices
Lastly, we go over two important technical considerations involved in designing feature attributions monitoring.
- Selecting the prediction class for attribution. In case of classification models, feature attributions are specific to an input and prediction class. When monitoring a distribution of inputs, which prediction class must be used for computing attributions? We recommend using the class that is considered as the prediction decision for the input. For multiclass models, this is usually the class with the largest score (i.e., “argmax” class). In some cases there is a specific protagonist class (for e.g., the “fraud” class in a fraud prediction model) whose score is considered by downstream applications. In such cases, it is reasonable to always use the protagonist class for attributions.
- Comparing attribution distributions. There are several choices for comparing distributions of attributions, including, distribution divergence metrics (e.g., Jensen-Shannon divergence) and various statistical tests (e.g. Kolmogorov-Smirnov test). Here, we use a relatively simple method of comparing the average absolute value of the attributions. This value captures the magnitude of contribution of each feature. Since attributions are in units of the prediction score, the difference in average absolute attribution can also be interpreted in units of prediction score. A large difference typically translates into a large impact on the prediction.
Next steps
To get started with Feature Attribution monitoring, start trying it with the Model Monitoring documentation. Also, Marc Cohen created a great Notebook material for learning how to use the functionality with an end-to-end scenario. By incorporating Vertex Model Monitoring and Explainable AI features with the best practices, you would be able to experience and learn "how to build and operate Google-scale production ML systems" for supporting mission critical businesses and services.Note #1: When Feature Attribution monitoring exposes false positives and false negatives
Feature Attribution monitoring is a powerful tool, but also has some caveats; sometimes it exposes false positives and false negatives, as illustrated by the following cases. Thus, when you apply the method to a production system, consider using it in a combination with other methods such as Feature Distribution monitoring for better understanding of the behaviour of your ML models.
[False negative] Univariate drift in attributions may fail to capture multivariate drift in features when the model has no interactions
Example: Consider a linear model y = x1 +...+ xn. Here, univariate drift in attributions will be proportional to univariate drift in features. Thus, attribution drift would be tiny if univariate drift in features is tiny, regardless of any multivariate drift.
[False negative] Drift in features that are unimportant to the model but affect model performance but may not manifest up in the attribution space.
Example: Consider a task y = x1 XOR x2 and model y_hat = x1. Let’s say the training distribution is an equal mix of <1, 0> and <0, 0> while the production distribution is an equal mix of <1, 1> and <0, 1>. While feature x2 has zero attribution (and therefore zero attribution drift), drift in x2 has a massive impact on model performance.
[False positive] Drift in important features may not always affect model performance
Example: Let’s say in the XOR example, the production distribution consists of just <1, 0>. While there is large drift in the input feature x1, it does not affect performance.
Note #2: Combining Feature Distribution and Feature Attributions
- By combining both Feature Distribution and Feature Attributions monitoring, we can obtain deeper insights on what changes might be affecting the model. The table below provides some potential directions based on combining the observations from the two monitoring methods.