Machine Learning Experiments in Gaming and Why it Matters
R.E. Wolfe
Machine Learning Specialist
Machine Learning Experiments in Gaming and Why it Matters
Introduction
Machine learning (ML) is essential to video game development. Predicting specific in-game actions and identifying and reaching your most valuable players helps to drive better outcomes. To this end, we need to keep track of all experiments that are happening behind the scenes. Google Cloud recently announced the general availability of a new feature called Vertex AI Experiments that can now help gaming companies do just that - keep track of their ML experiments to uncover insights and best practices across their ML Engineering and Data Science teams.
In this blog post, we will focus on a popular video game dataset coming from the EA Sports' FIFA video game series. We will use this dataset to build a ML pipeline to predict the overall rating for a player. We then experiment with different hyperparameters that can then be tracked in Vertex AI Experiments in order to identify the best performing run that's ultimately put into production by the gaming company.
The Challenge with Experimentation
In an ML experiment, you vary different inputs. Your hypothesis might involve testing a specific algorithm or value of a hyperparameter to determine if it is more performant than various alternatives. While ML experiments are common, we often hear the same complaint coming from Data Science teams at gaming companies:
Our team was developing a machine learning model, trying different hyperparameters, algorithms, training datasets, and even different hardware. The results were really strong after all of that fine tuning! Unfortunately, we didn’t track our different parameters and iterations and after all of that work couldn’t tell what performed best.
, Disheartened Data Scientist at a Gaming Company
Data Scientists and other ML practitioners at gaming companies are well versed in experimentation. Where they run into a challenge is keeping a record of all of the rich ML experiments that have been run.
But why is tracking so challenging? There are a number of reasons. First, tracking runs of multiple training jobs is cumbersome. It's easy to lose sight of what's working versus what's not. Second, issues compound as your team grows in size. Not all members will be tracking experiments or even sharing their results across the broader team. Third, data capture is time consuming. Manual methods (for example, tracking in spreadsheets) result in inconsistent and often incomplete information, which is difficult to learn from.
Teams can now move away from their old and ineffective way of doing things since platforms now exist that can help Data Science and ML Engineering teams better manage their experiments, compare model or pipeline runs, and uncover new insights.
What is Vertex AI Experiments and how does it work?
Let’s briefly discuss what Vertex AI Experiments does. Vertex AI Experiments is a service that more effectively tracks your ML experiments all in one place. Experiments tracked within Vertex AI Experiments consist of a set of runs. While our video game example will be focusing on tracking runs of a ML pipeline, a run within an experiment could be a run of a locally trained model as well.
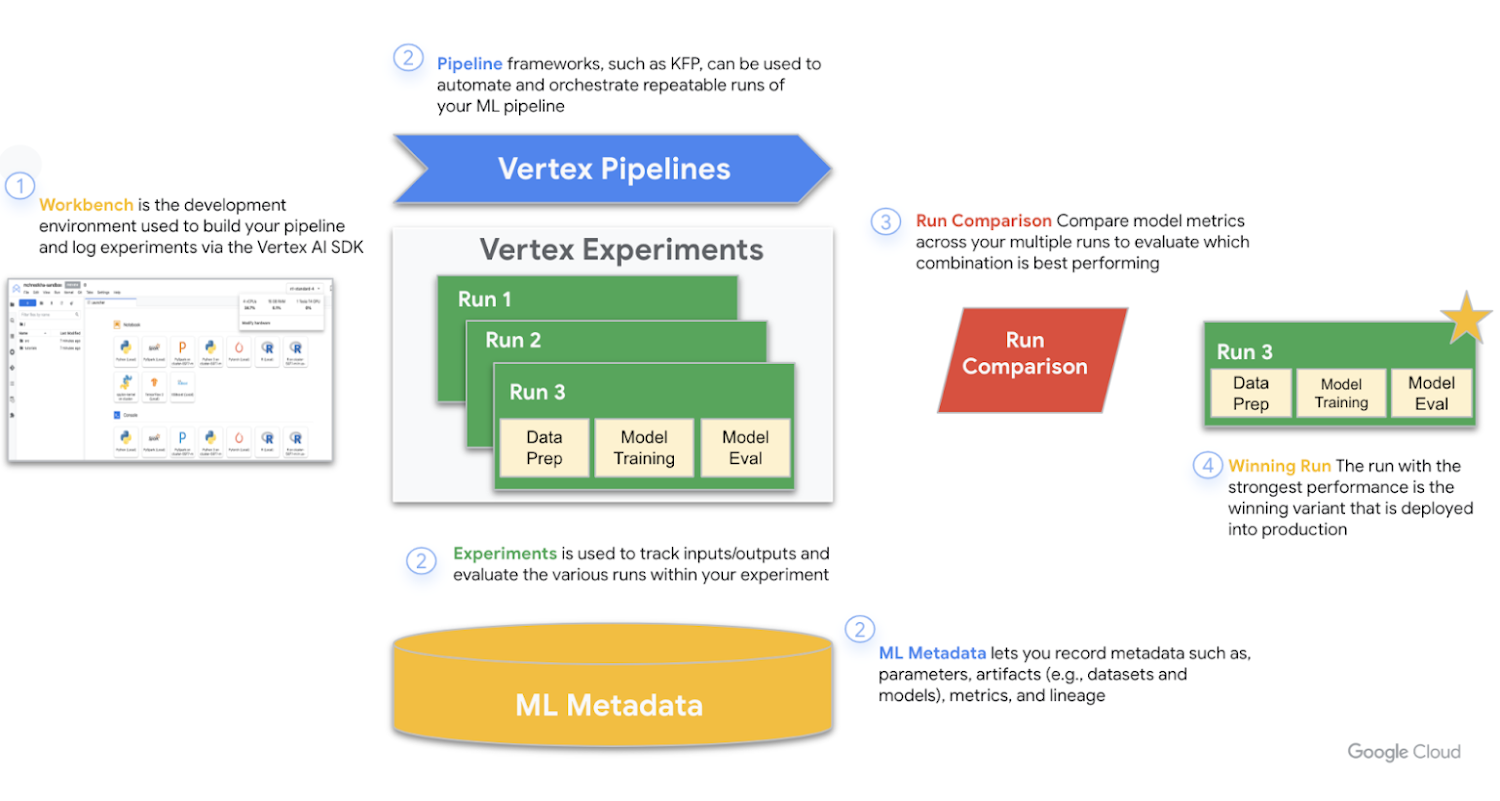
In fact, Vertex AI Experiments works hand in hand with other products within the larger Vertex AI suite to better track elements within your various runs. The tools used are Workbench, Pipelines, Experiments, and ML Metadata. The figure below provides a play-by-play on how these tools work together to capture relevant data and uncover the best performing run that is ultimately put into production.
What's required to get started?
Experiment runs tracked in Vertex AI Experiments are a value add and do not incur additional charges. Users are only charged for resources that are used during your experiment as described in Vertex AI pricing. Beyond that, as long as you have enabled the relevant APIs such as the Compute Engine API, Vertex AI API, and Notebooks API you are off to the races and can begin tracking and comparing the runs within your experiment.
Let’s Track ML Pipeline Runs to Better Predict Player Ratings
To see Vertex AI Experiments in action in a video game context, we now build an ML pipeline and track its various runs within Vertex AI Experiments. While we show you a few highlights here, you can find the full pipeline code for this example in this codelab which again leverages the popular EA Sports FIFA Video Game Series Dataset to predict the overall rating for a player. Our experiment involves the following:
Train a custom Keras regression model to predict player ratings using different values of hyperparameters
Use the Kubeflow Pipelines SDK to build a scalable ML pipeline
Create and run a 5-step pipeline that ingests data from Cloud Storage, scales the data, trains the model, evaluates it, and saves the resulting model back into Cloud Storage
Leverage Vertex ML Metadata to save model artifacts such as Models and Model Metrics
Utilize Vertex AI Experiments to track and compare results of the various pipeline runs with different values of hyperparameters
To build, run, and track our ML pipeline runs, we’ll start by importing a couple of libraries:
The Kubeflow Pipelines SDK is used to build our components and connect them together into a pipeline
The Vertex AI SDK allows us to run our pipeline on Vertex Pipelines and track our runs within an experiment
To begin running our experiments, we need to specify our training job by defining it as a pipeline training component. Our component takes in our dataset and hyperparameters (e.g., DROPOUT_RATE, LEARNING_RATE, EPOCHS) as inputs and output model metrics (e.g., MAE and RMSE) and a model artifact.
A few additional callouts. We have included a few parameters in our model architecture so that we can more easily experiment and pass in different values of the hyperparameters we are using to tune the Keras model. In the final step of the code, you can also see how we are able to interact with ML metadata to store our model metrics and the model artifact itself.
After defining and compiling our pipeline, we are ready to submit our pipeline runs. We can speed up our experimentation by creating a variable called “runs” that defines the different hyperparameter values we want to pass in for each run.
We can then leverage a for loop to successfully feed in the different hyperparameter values associated with each run into our pipeline job.
Now we can start to see Vertex AI experiments in action. The Vertex AI SDK for Python currently supports a get_experiment_df method which returns information about your runs. You can use it to get details such as the model metrics and the current state of a given run.
After leveraging the Vertex AI SDK to view experiments, we can now more effectively compare the different runs of our pipeline and identify the run that is best performing and should be put into production. This can be done both programmatically in our managed notebook but also in the console itself.

Figure 2. View Pipeline Runs Within Your Experiment Programmatically
You might be asking at this point, what could a data scientist at a gaming company learn from the above results? The output from your experiment should contain five rows, one for each run of the pipeline. Both MAE and RMSE are measures of the average model prediction error so a lower value for both metrics is desirable in most cases.
We can see based on the output from Vertex AI Experiments that our most successful run across both metrics was the final run with a dropout_rate of 0.001, a learning_rate of 0.001, and the count of epochs being 20. Based on this experiment, the final run has the model parameters the gaming company would ultimately use in production since it results in the best model performance.
Conclusion
ML practitioners can now bid farewell to the old docs and excel sheets they were once using to haphazardly track ML experiments. With Vertex AI Experiments, we are now able to better harness the power of ML experiments. With more effective tracking comes richer insights, best practices, and the ability to gain insight into the experiments that are happening across your broader team.