How to build an open cloud datalake with Delta Lake, Presto & Dataproc Metastore
Jayadeep Jayaraman
Senior Staff Software Engineer, Google
Organizations today build data lakes to process, manage and store large amounts of data that originate from different sources both on-premise and on cloud. As part of their data lake strategy, organizations want to leverage some of the leading OSS frameworks such as Apache Spark for data processing, Presto as a query engine and Open Formats for storing data such as Delta Lake for the flexibility to run anywhere and avoiding lock-ins.
Traditionally, some of the major challenges with building and deploying such an architecture were:
- Object Storage was not well suited for handling mutating data and engineering teams spent a lot of time in building workarounds for this
- Google Cloud provided the benefit of running Spark, Presto and other varieties of clusters with the Dataproc service, but one of the challenges with such deployments was the lack of a central Hive Metastore service which allowed for sharing of metadata across multiple clusters.
- Lack of integration and interoperability across different Open Source projects
To solve for these problems, Google Cloud and the Open Source community now offers:
- Native Delta Lake support in Dataproc, a managed OSS Big Data stack for building a data lake with Google Cloud Storage, an object storage that can handle mutations
- A managed Hive Metastore service called Dataproc Metastore which is natively integrated with Dataproc for common metadata management and discovery across different types of Dataproc clusters
- Spark 3.0 and Delta 0.7.0 now allows for registering Delta tables with the Hive Metastore which allows for a common metastore repository that can be accessed by different clusters.
Architecture
Here’s what a standard Open Cloud Datalake deployment on GCP might consist of:
- Apache Spark running on Dataproc with native Delta Lake Support
- Google Cloud Storage as the central data lake repository which stores data in Delta format
- Dataproc Metastore service acting as the central catalog that can be integrated with different Dataproc clusters
- Presto running on Dataproc for interactive queries
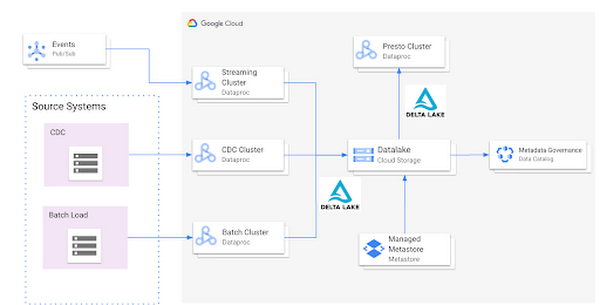
Such an integration provides several benefits:
- Managed Hive Metastore service
- Integration with Data Catalog for data governance
- Multiple ephemeral clusters with shared metadata
- Out of the box integration with open file formats and standards
Reference implementation
Below is a step by step guide for a reference implementation of setting up the infrastructure and running a sample application
Setup
The first thing we would need to do is set up 4 things:
- Google Cloud Storage bucket for storing our data
- Dataproc Metastore Service
- Delta Cluster to run a Spark Application that stores data in Delta format
- Presto Cluster which will be leveraged for interactive queries
Create a Google Cloud Storage bucket
Create a Google Cloud Storage bucket with the following command using a unique name.
Create a Dataproc Metastore service
Create a Dataproc Metastore service with the name “demo-service” and with version 3.1.2. Choose a region such as us-central1. Set this and your project id as environment variables.
Create a Dataproc cluster with Delta Lake
Create a Dataproc cluster which is connected to the Dataproc Metastore service created in the previous step and is in the same region. This cluster will be used to populate the data lake. The jars needed to use Delta Lake are available by default on Dataproc image version 1.5+
Create a Dataproc cluster with Presto
Create a Dataproc cluster in us-central1 region with the Presto Optional Component and connected to the Dataproc Metastore service.
Spark Application
Once the clusters are created we can log into the Spark Shell by SSHing into the master node of our Dataproc cluster “delta-cluster”.. Once logged into the master node the next step is to start the Spark Shell with the delta jar files which are already available in the Dataproc cluster. The below command needs to be executed to start the Spark Shell. Then, generate some data.
# Write Initial Delta format to GCS
Write the data to GCS with the following command, replacing the project ID.
# Ensure that data is read properly from Spark
Confirm the data is written to GCS with the following command, replacing the project ID.
Once the data has been written we need to generate the manifest files so that Presto can read the data once the table is created via the metastore service.
# Generate manifest files
With Spark 3.0 and Delta 0.7.0 we now have the ability to create a Delta table in Hive metastore. To create the table below command can be used. More details can be found here
# Create Table in Hive metastore
Once the table is created in Spark, log into the Presto cluster in a new window and verify the data. The steps to log into the Presto cluster and start the Presto shell can be found here.
#Verify Data in Presto
Once we verify that the data can be read via Presto the next step is to look at schema evolution. To test this feature out we create a new dataframe with an extra column called “z” as shown below:
# Schema Evolution in Spark
Switch back to your Delta cluster’s Spark shell and enable the automatic schema evolution flag
Once this flag has been enabled create a new dataframe that has a new set of rows to be inserted along with a new column
Once the dataframe has been created we leverage the Delta Merge function to UPDATE existing data and INSERT new data
# Use Delta Merge Statement to handle automatic schema evolution and add new rows
As a next step we would need to do two things for the data to reflect in Presto:
- Generate updated schema manifest files so that Presto is aware of the updated data
- Modify the table schema so that Presto is aware of the new column.
When the data in a Delta table is updated you must regenerate the manifests using either of the following approaches:
- Update explicitly: After all the data updates, you can run the generate operation to update the manifests.
- Update automatically: You can configure a Delta table so that all write operations on the table automatically update the manifests. To enable this automatic mode, you can set the corresponding table property using the following SQL command.
However, in this particular case we will use the explicit method to generate the manifest files again
Once the manifest file has been re-created the next step is to update the schema in Hive metastore for Presto to be aware of the new column. This can be done in multiple ways, one of the ways to do this is shown below:
# Promote Schema Changes via Delta to Presto
Once these changes are done we can now verify the new data and new column in Presto as shown below:
# Verify changes in Presto
In summary, this article demonstrated:
- Set up the Hive metastore service using Dataproc Metastore, spin up Spark with Delta lake and Presto clusters using Dataproc
- Integrate the Hive metastore service with the different Dataproc clusters
- Build an end to end application that can run on an OSS Datalake platform powered by different GCP services
Next steps
If you are interested in building an Open Data Platform on GCP please look at the Dataproc Metastore service for which the details are available here and for details around the Dataproc service please refer to the documentation available here. In addition, refer to this blog which explains in detail the different open storage formats such as Delta & Iceberg that are natively supported within the Dataproc service.