Build a platform with KRM: Part 4 - Administering a multi-cluster environment
Megan O'Keefe
Senior Staff Developer Advocate
This is part 4 in a multi-part series about the Kubernetes Resource Model. See parts 1, 2, and 3 to learn more.
Kubernetes clusters can scale. Open-source Kubernetes supports up to 5,000 Nodes, and GKE supports up to 15,000 Nodes. But scaling out a single cluster can only get you so far: if your cluster’s control plane goes down, your entire platform goes down; if the Cloud region running your cluster has a service interruption, so does your app.
Many organizations choose, instead, to operate multiple Kubernetes clusters. Besides availability, there are lots of reasons to consider multi-cluster, such as allocating a cluster to each development team, splitting workloads between cloud and on-prem, or providing burst capability for traffic spikes.
But operating a multi-cluster platform comes with its own challenges. How to consistently administer many clusters at once? How to keep the clusters secure? How to deploy and monitor applications running across multiple clusters? How to seamlessly fail over from one region to another?
This post introduces a few tools that can help platform teams more easily administer a multi-cluster Kubernetes environment.
The platform base layer, with Config Sync
In the last post, we explored how thoughtful platform abstractions can help reduce toil for app developers- including for a multi-cluster environment, where automation such as CI/CD handles all interactions with the staging and production clusters. But equally important is the platform base layer, the Kubernetes resources and configuration that are shared across services. Your platform base layer might consist of Namespaces, role-based access control, and shared workloads like Prometheus.
Platform abstractions depend on the existence of these base-layer resources. And so does the security and stability of your platform as a whole. It’s important that these resources not only get deployed, but also stay put. CI/CD is great for deploying resources, but what about making sure resources stay deployed? What if a Kubernetes Namespace gets deleted? Or a Prometheus StatefulSet is modified?
Kubernetes’ job is to ensure that the cluster’s actual state matches the desired state. But sometimes, the “desired” state isn’t desired at all - it’s a developer who mistakenly modified a resource, or a bad actor that’s gained access into the system. For this reason, a platform base layer needs more than a one-and-done CI/CD pipeline. A tool called Config Sync can help with this.
Config Sync is a Google Cloud product that can sync Kubernetes resources from a Git repository to one or more GKE or Anthos clusters. Unlike CI/CD tools like Cloud Build, Config Sync watches your clusters constantly, making sure that the intended resource state in the cluster always matches what’s in Git. Config Sync is designed primarily for base-layer resources like namespaces and RBAC. In this way, Config Sync is complementary to, not a replacement for, CI/CD.
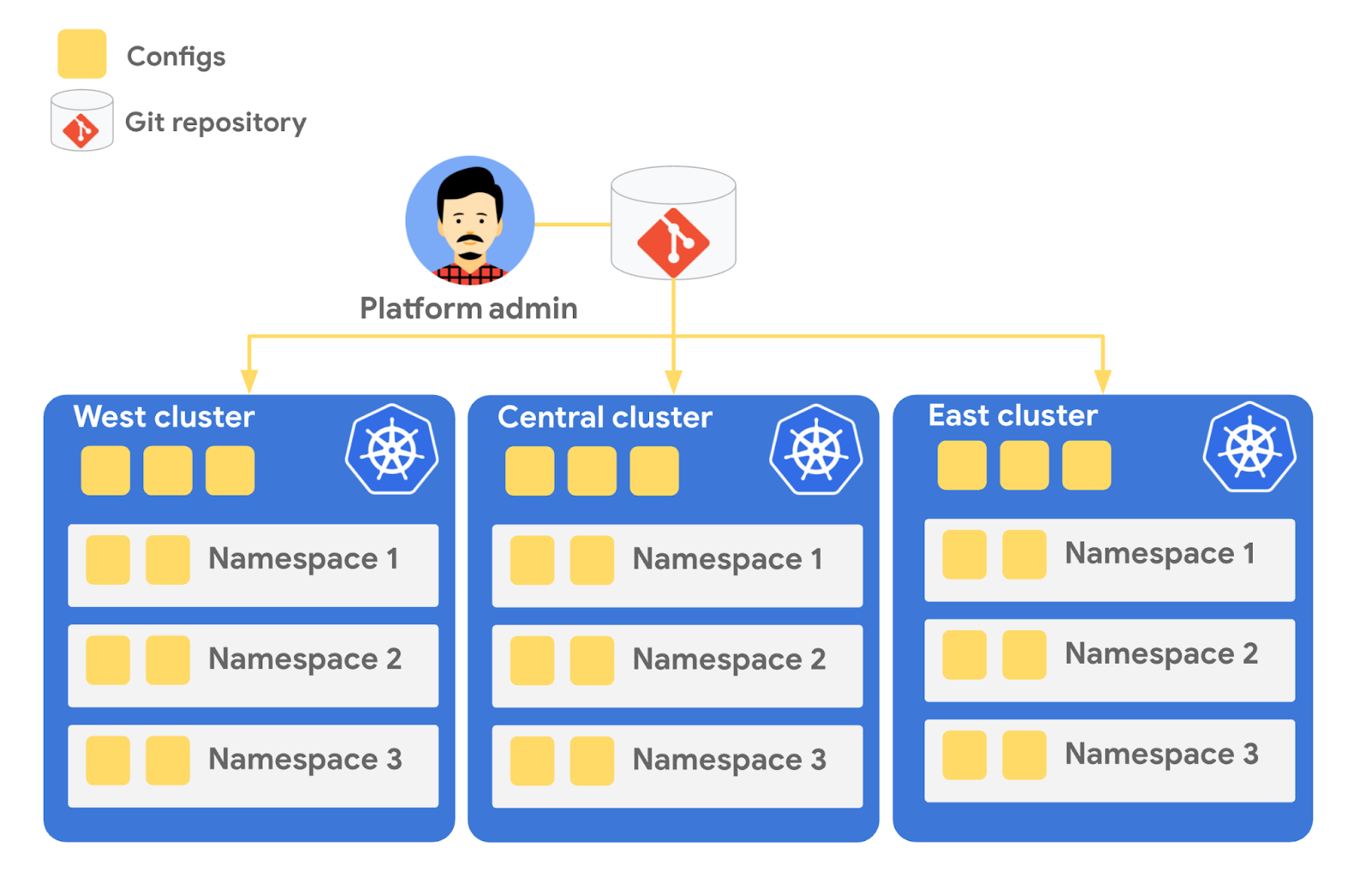
Config Sync runs in a Pod inside your Kubernetes cluster, watching your Git config repo for changes, and also watching the cluster itself for any divergence from your desired state in Git. If any configuration drift is detected from what’s stored in Git, Config Sync will update the API Server accordingly.
You can point multiple Config Sync deployments at the same Git repo, allowing you to manage the base-layer platform resources for multiple clusters using the same source of truth. And by using Git as the landing zone for config, you can benefit from some of the GitOps principles we discussed in part 2, including the ability to audit and roll back configuration changes.
Let’s walk through an example of how to manage base-layer resources with Config Sync.
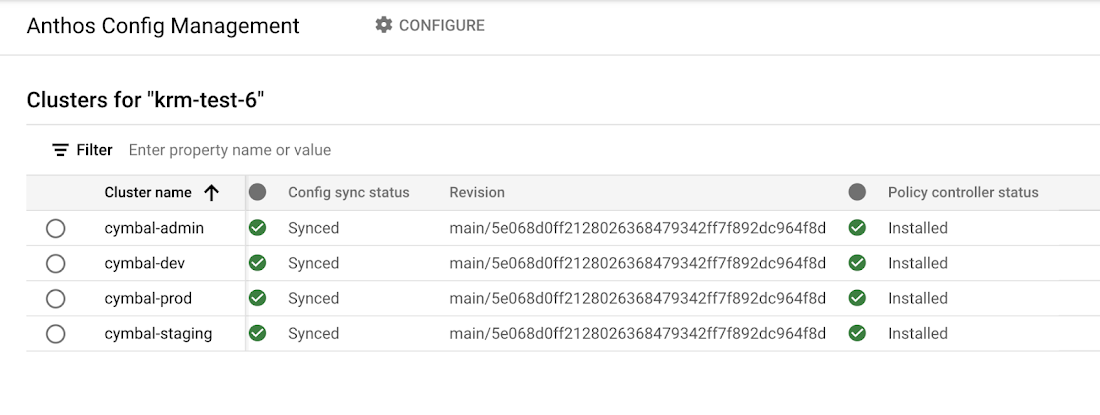
The Cymbal Bank platform consists of four GKE clusters: admin, dev, staging, and prod. We can install Config Sync on all four clusters using the gcloud tool or the Google Cloud Console, pointing all four clusters at a single Git repository, called cymbalbank-policy. Note that this repo is separate from the application source and config repos, and is managed by the platform team. From the Console, we can see that all four clusters are synced to the same commit of the cymbalbank-policy repo.
Now, let’s say that the Cymbal Bank platform team wants to limit the amount of CPU and memory resources each application team can request for their service. Kubernetes ResourceQuotas help impose these limits, and prevent unexpected Pod evictions.
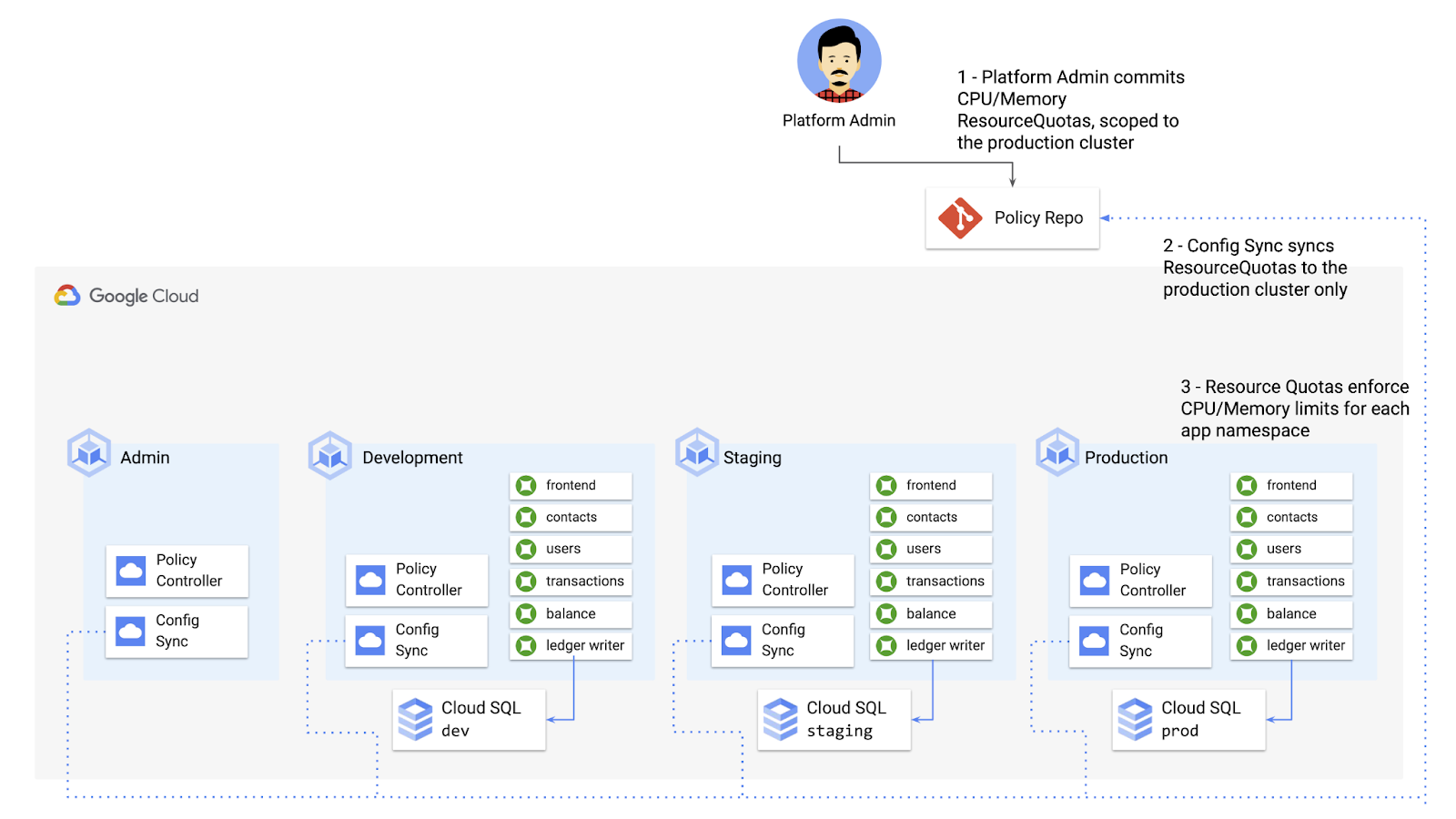
The platform team can define a set of ResourceQuotas for each application namespace. They can also scope the resources to only be applied to a subset of clusters - for instance, to the production cluster only. (If no cluster name selector is specified, Config Sync will deploy the resource to all clusters by default.)
From here, the platform team can commit the resources to the cymbalbank-policy repo, and Config Sync, always watching the policy repo, will deploy the resources to the production cluster:
If a developer tries to delete one of the ResourceQuotas, Config Sync will block the request, helping to ensure that these base-layer resources stay put.
In this way, Config Sync can help platform teams ensure the stability of that platform base-layer, as well as ensure resource consistency across multiple clusters at once. This, in turn, can help organizations mitigate the complexity of adding new clusters to their environment.
Enforce policies on Kubernetes resources
Config Sync is a powerful tool on its own, and can work with any Kubernetes resource that your cluster recognizes. This includes Custom Resource Definitions (CRDs) installed with add-ons like Anthos Service Mesh.
But Config Sync, by default, doesn’t have an idea of “good or bad” Kubernetes resources. It will deploy whatever resources land in Git, even resources that might pose a security risk to your organization. Security is an essential feature of any developer platform, and when it comes to Kubernetes, it’s important to think about security from the initial software design stages, and set up your clusters with security best-practices in mind.
But it’s just as important to think about security at deploy-time. Who and what can access your clusters? What kinds of Kubernetes resources - and fields within those resources- are allowed? These decisions will depend on lots of factors, including the kinds of data your application deals with, and any industry-specific regulations.
One common security use case for KRM is the need to monitor incoming Kubernetes resources, whether they’re coming in through kubectl, CI/CD, or Config Sync. But if you have multiple clusters, your Kubernetes environment has multiple API Servers, and therefore multiple entry points.
A Google tool called Policy Controller can help automate resource monitoring across multiple clusters. Policy Controller is a Kubernetes admission controller that can accept or reject incoming resources based on custom policies you define. Policy Controller is based on the OpenPolicyAgent Gatekeeper project, and it allows you to define policies, or “Constraints,” as KRM. This means you can deploy them using Config Sync, via Git. Once deployed, Policy Controller uses your Constraints as a set of rules to evaluate all incoming KRM, rejecting resources that fall out of compliance.
Let’s walk through an example. Say that the Cymbal Bank security team wants to ensure that no code in development is accessible to the public. Kubernetes Services of type LoadBalancer expose public IP addresses by default, so the platform team wants to define a PolicyController constraint that blocks Services of that type on the development GKE cluster.
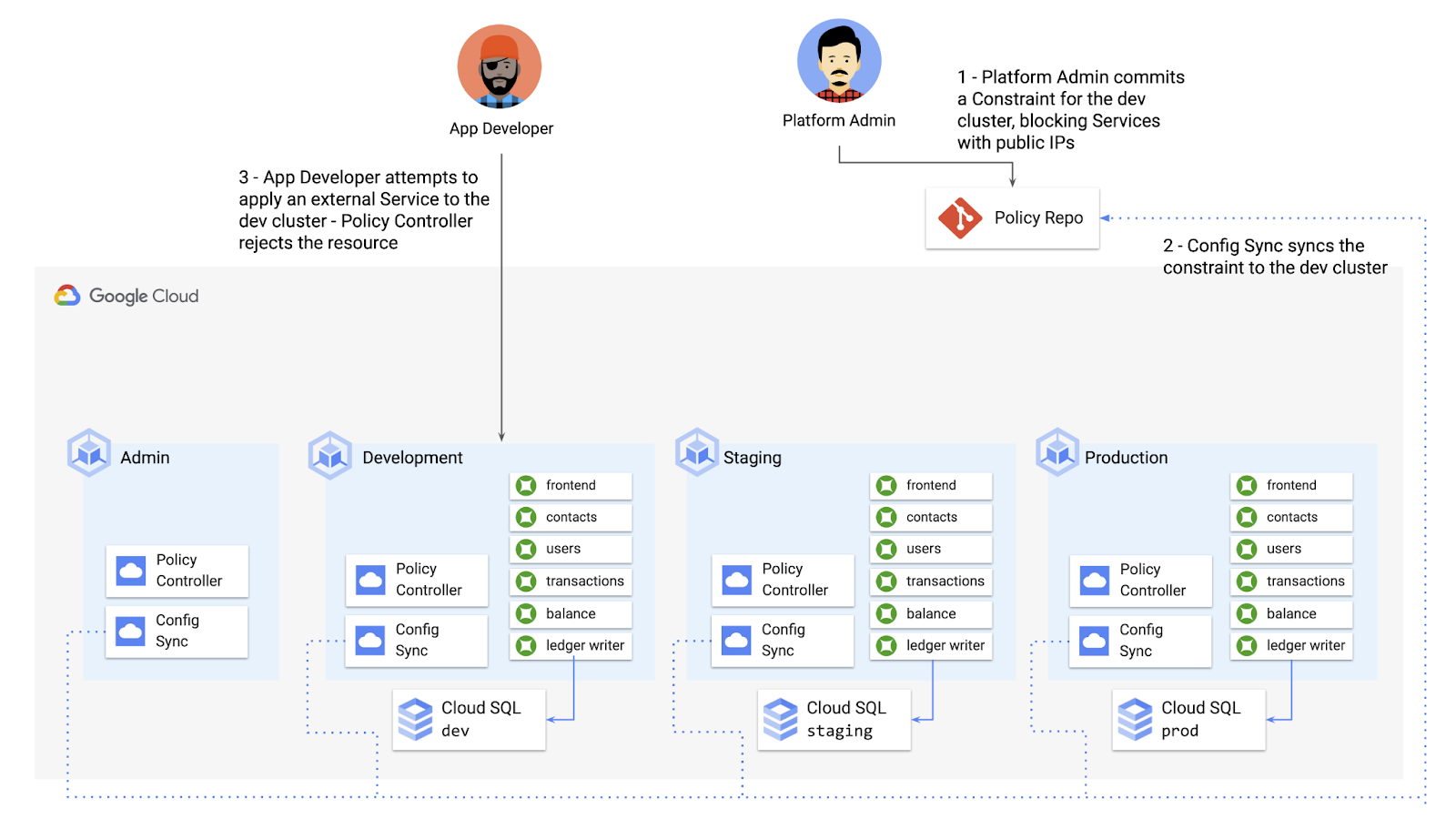
To do this, the platform team can define a Policy Controller Constraint as KRM. This Constraint uses a Constraint Template, provided through the pre-installed Constraint Template library. The ConstraintTemplate defines the logic of the policy itself, and the Constraint makes the template concrete, populating any variables needed to execute the policy logic. Here, we’re also adding a Config Sync cluster name annotation, to scope this resource to apply only to the development cluster.
The platform team can then commit the resource to the cymbalbank-policy repo, and Config Sync will deploy the resource to the development cluster.
From here, if an app developer tries to create an externally-accessible Kubernetes Service, Policy Controller will block the resource from being created.
The platform team can define as many of these Constraints as they want, each defining a separate policy.
Writing custom policies
The Policy Controller Constraint Template library provides a lot of functionality, from blocking privileged containers, to requiring certain resource labels, to preventing app teams from deploying into certain namespaces. But if you want to enforce custom logic on your organization’s KRM, you can do so by writing a custom Constraint Template.
Constraint Templates are written in a query language called Rego. Rego was designed for policy rule evaluation, and it can introspect Kubernetes resource fields to make a conclusion as to whether the resource is allowed or not.
For instance, let’s say that the platform team wants to limit the number of containers allowed inside a single application Pod. Too many containers per Pod can cause outage risks— when one container crashes, the entire Pod crashes.
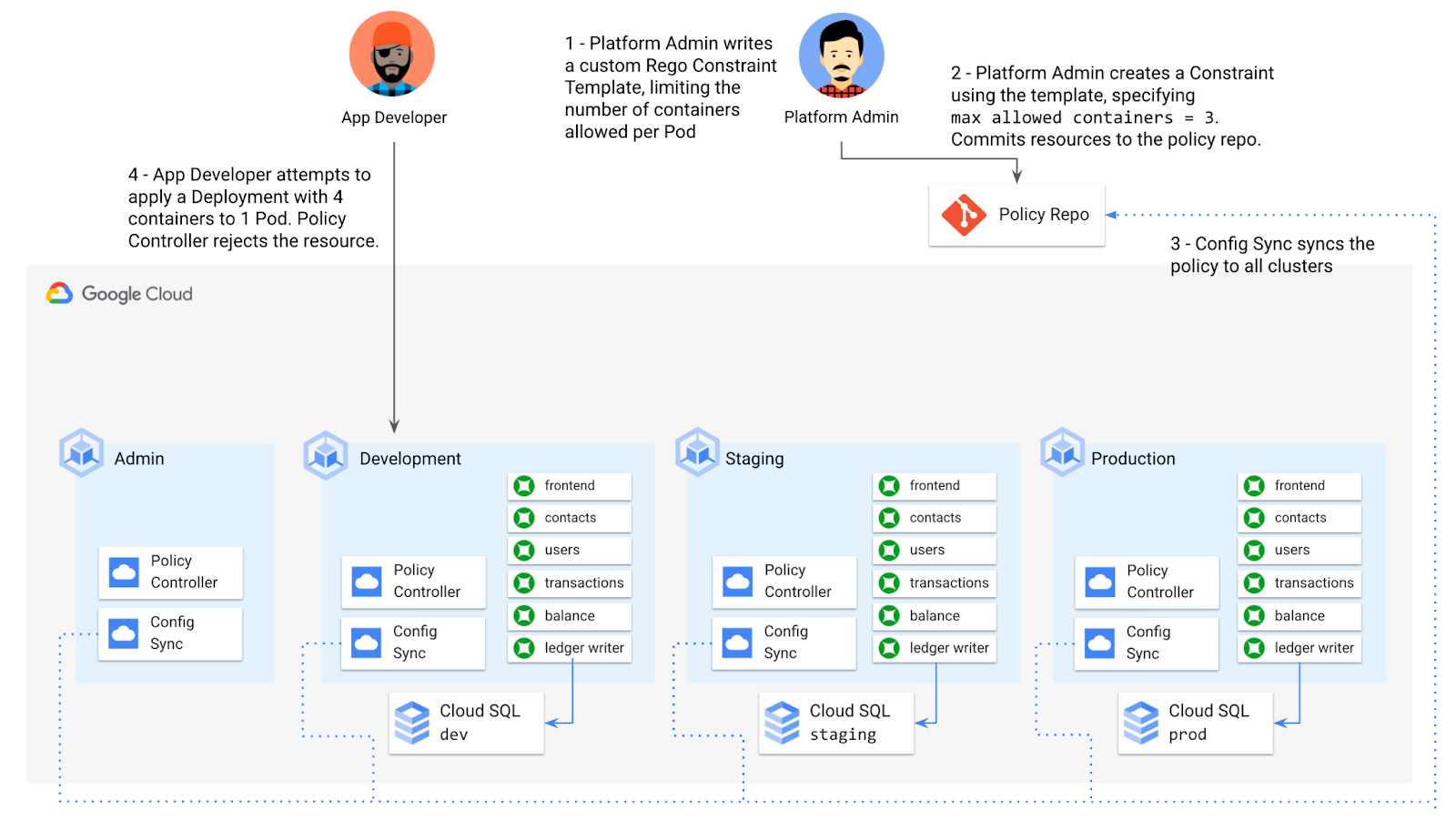
To enforce this policy, the platform team can define a Constraint Template, using the Rego language, that looks inside a resource to ensure that the number of containers per Pod is within the allowed limit:
Finally, the platform team can push these resources to the cymbalbank-policy repo, and Config Sync will deploy the policy to all four clusters. If a developer tries to define a Kubernetes Deployment containing more containers per pod than what’s allowed, the resource will be blocked at deploy time:
Custom Constraint Templates can give platform teams lots of flexibility in the types of policies they define and enforce in a Kubernetes environment.
Integrating policy checks into CI/CD
As we explored earlier, Config Sync and CI/CD are complementary tools. Config Sync works great for base-layer platform resources and policies, whereas CI/CD works well for application tests and deployment.
But one pitfall of having two separate KRM deployment mechanisms is that app developers may not know that their resources are out of policy until they try to deploy them into production. This is especially true if some policies are scoped only to production, as we saw with the ResourceQuota example. Ideally, the platform team has a way to empower developers and code reviewers to know ahead of time whether new or modified resources are still in compliance. We can enable this use case by integrating policy checks into the existing Cymbal Bank CI/CD.
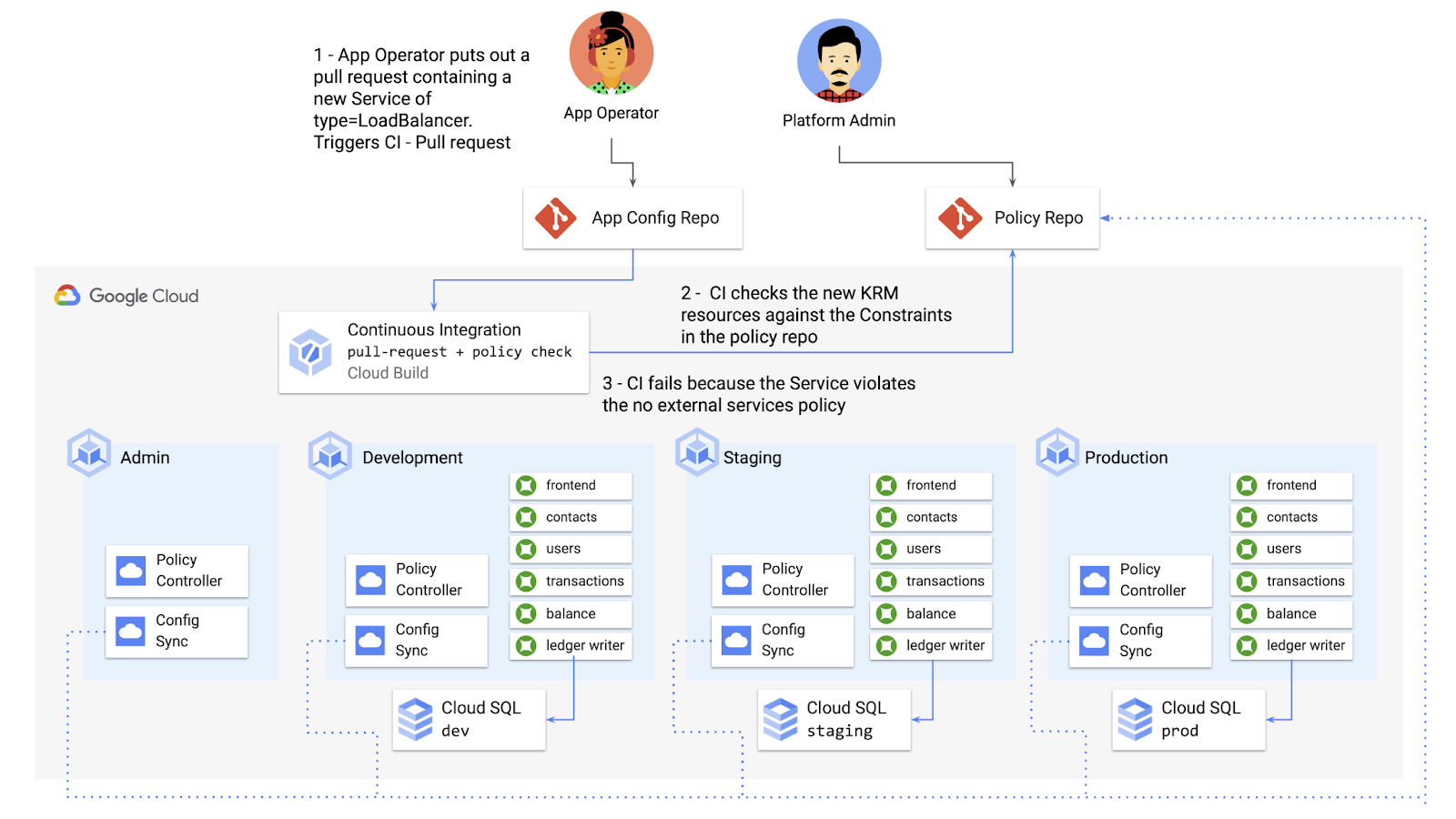
Policy Controller operates, by default, as a Kubernetes Admission Controller running inside the cluster. But Policy Controller also provides a “standalone” mode, running inside a container, that can be used outside of a cluster, such as from inside a Cloud Build pipeline.
In the example below, Cloud Build executes Policy Controller checks by getting the cymbalbank-app-config manifests, cloning the cymbalbank-policy resources, and using the “policy-controller-validate” container image to evaluate the app manifests against the policies.
From here, an app developer or operator can know if their resources violate org-wide policies, by looking at the Cloud Build output for their Pull Request:
By integrating policy checks into CI/CD, app development teams can understand whether their resources are in compliance, and platform teams add an additional layer of policy checks to the platform.
Overall, Config Sync and Policy Controller can provide a powerful toolchain for standardizing base-layer config across a multi-cluster environment. Check out the Part 4 demo to try out each of these examples.
And stay tuned for Part 5, where we’ll learn how to use KRM to manage cloud-hosted resources.