Competing with supercomputers: HPC in the cloud becomes reality
Dean Hildebrand
Technical Director, Office of the CTO, Google Cloud
James Coomer
Sr. Vice President Products, DataDirect Networks
Migrating applications to the cloud usually requires significant planning, but some apps, such as data-intensive, tightly coupled high-performance computing (HPC) apps, pose a particular challenge. HPC data growth used to be bound by compute capabilities, but data now comes from many more sources, including sensors, cameras and instruments. That data growth is outpacing corresponding improvements in computer processing, network throughput, and storage performance. This spells trouble for the AI and ML algorithms that need to keep up and process this data to derive insights. This data growth means that many traditional HPC on-premises data centers have to start migrating at least some of the application load into the cloud.
With all that in mind, Google Cloud and DDN have developed an in-cloud file system suitable for HPC: DDN’s EXAScaler, a parallel file system designed to handle high concurrency access patterns to shared data sets. Such I/O patterns are typical of tightly coupled HPC applications such as computational simulations in the areas of astrophysics or finance. DDN provides expertise in deploying data-at-scale solutions for the most challenging data-intensive applications, and Google provides expertise in delivering global-scale data center solutions.
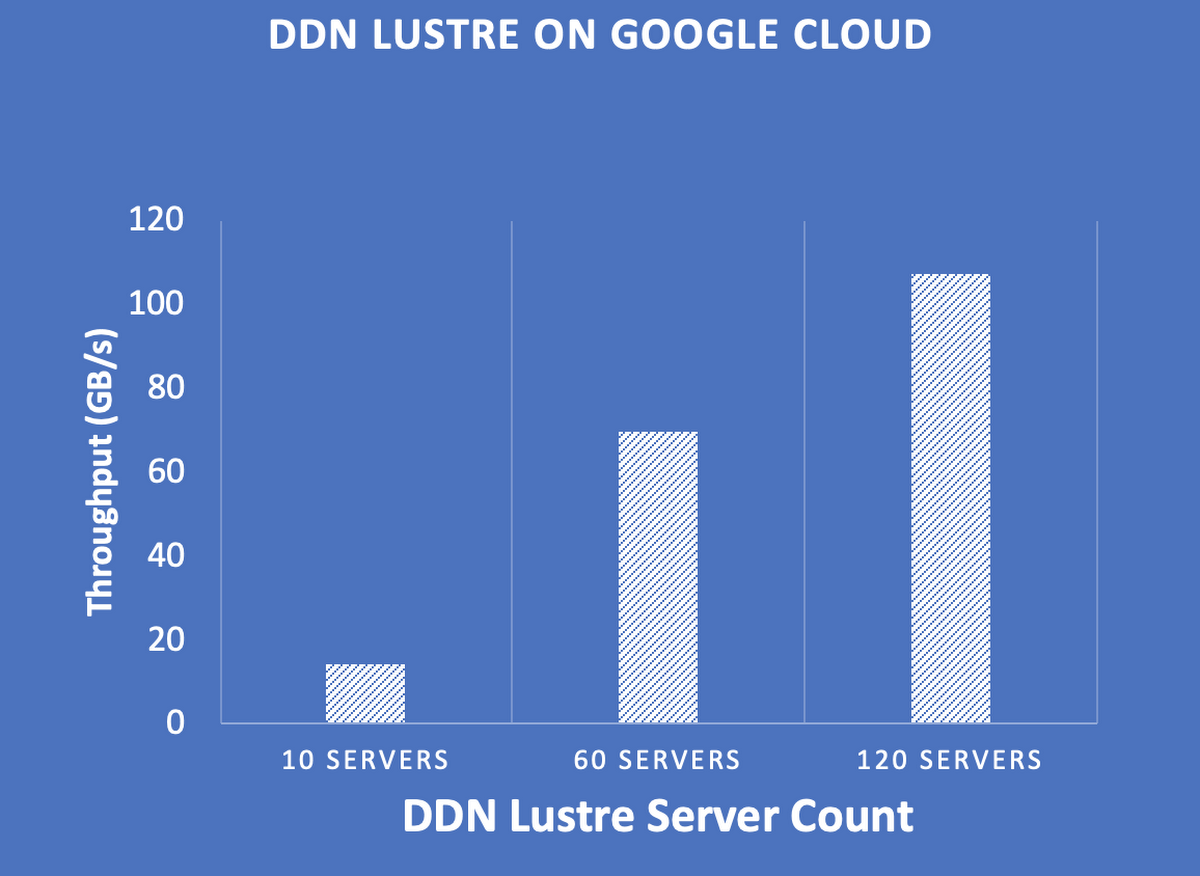
EXAScaler is DDN’s branded Lustre product. Lustre is an open-source file system, with more than 15 years of demonstrated stability and performance in commercial and research environments at the largest scales. Lustre performs well, but tuning it for maximum efficiency can be challenging. Google and DDN recently used IO-500, the top HPC storage benchmark, to demonstrate the joint system’s ease of use.
Competing in the HPC storage challenge
IO-500 is an emerging HPC storage benchmark that seeks to capture the full picture of an HPC storage system by calculating a score based upon a wide range of storage characteristics, rather than capturing one narrow performance dimension (such as sequential read performance). Designed to give users realistic performance expectations and to help administrators select their next HPC storage system, the IO-500 competition releases two ranked lists per year: one in the U.S. in November at Supercomputing, the premiere HPC conference, and one in June at ISC, the European equivalent. We were excited to join this competition for the first time to show how easy it is to use this joint solution.
Our top-performing configuration achieved #8 on the IO-500, and was limited solely by our allocated resources (next time we’ll request more). This success shows that anyone can now deploy a high-end storage system, not just those with a large budget and extensive expertise.
The key benefits of using EXAScaler really came through during the benchmarking process itself:
Fast deployment
The entire Lustre file system, including the VMs and storage it used, was deployed in minutes and shut down immediately afterwards. This is in contrast with on-premises HPC deployments, where it can take weeks just to deploy the hardware alone.
Resource efficiency
EXAScaler could generally saturate Google Cloud block storage IOPS and bandwidth limits, which is a testament to Lustre efficiency, EXAScaler tuning, and Google Cloud capabilities.
Easy configuration
We submitted three separate configurations to evaluate the effect of changing the number of clients, storage servers, and metadata servers. Deploying each configuration required only a few changes in the deployment script. In fact, this flexibility made it harder to narrow down our configuration choices, since we were only limited by our allotted resources and our imagination of how many different ways Lustre can be deployed.
Integrated monitoring
We found that combining client and storage server monitoring using Google Stackdriver with the native DDN EXAScaler monitoring tools allowed for quick diagnosis and resolution of performance bottlenecks. Further, these tools allowed us to identify opportunities to reduce the cost of the system (such as reducing the number of allocated storage server vCPUs).
Predictable performance
While the IO-500 benchmark only requires the results of a single run, we found benchmark performance extremely consistent between runs.
Finally, Lustre on Google Cloud is the only pay-as-you-go storage system on the list, and so the actual cost of the system is simply the per-second cost of running the benchmark (approximately one hour). It would be very interesting if the IO-500 included the cost of each system, as the balance between price and performance is in many cases more important for users than raw performance.
Tips for running HPC in the cloud
Benchmarks can be a useful way to get to know the overall market and narrow down your HPC storage choices. However, it’s also important to know what to watch out for when you’re moving important workloads to cloud, particularly if your business relies on them.
If you’re considering moving traditional HPC workloads to the cloud, first identify a set of applications to migrate and their sustained performance requirements to create economically efficient hybrid solutions. Executing HPC workloads in the cloud can simply be a lift and shift of HPC software, but it’s also a chance for you to tailor your infrastructure to the needs of the workload. Compute can be scaled up when it's needed, and scaled down when it’s not. Workloads that need GPUs can provision them and those that do not can simply customize the compute and memory that is required. Storage can also be allocated when in use and either stopped or de-allocated when idle.
The goal when you’re running HPC in the cloud should be to simply focus on what applications need, and leave the execution to Google Cloud. For example, one common storage deployment issue is that a single parallel file system is supposed to handle workloads with conflicting requirements such as high metadata/IOPS performance and high bandwidth. Optimizing for metadata/IOPS performance requires more expensive SSDs, which is unnecessary for workloads that simply need high bandwidth. Also, running both types of workloads at the same time can drastically increase the runtime of both due to the mixing of I/O requests. A better way is to customize a parallel file system for each workload type, which decreases overall workload runtime by reducing I/O contention and can even reduce cost by making better use of the provisioned storage devices.
While Lustre is proven to scale in traditional on-premises HPC infrastructures, its ability to adapt and deliver the benefits of the cloud has so far not been demonstrated—which is why DDN focuses on adapting, deploying and running Lustre at extreme scales in the cloud. Lustre in the cloud should continue to deliver extreme scale and performance, but be easy to manage and not blow up your storage budget.
Using Google Cloud and DDN together can create the right balance of compute and storage for each workload. For active hot data, the Lustre file system brings high performance. For inactive cold data, Google Cloud Storage can be used as an extreme scale archive that delivers high availability with multi-regional, dual-regional, and regional classes and low cost with standard, nearline, and coldline classes. Combining Lustre with Google Cloud storage means that hot data can be fast and cold data can be stored cheaply and brought to bear quickly when needed.
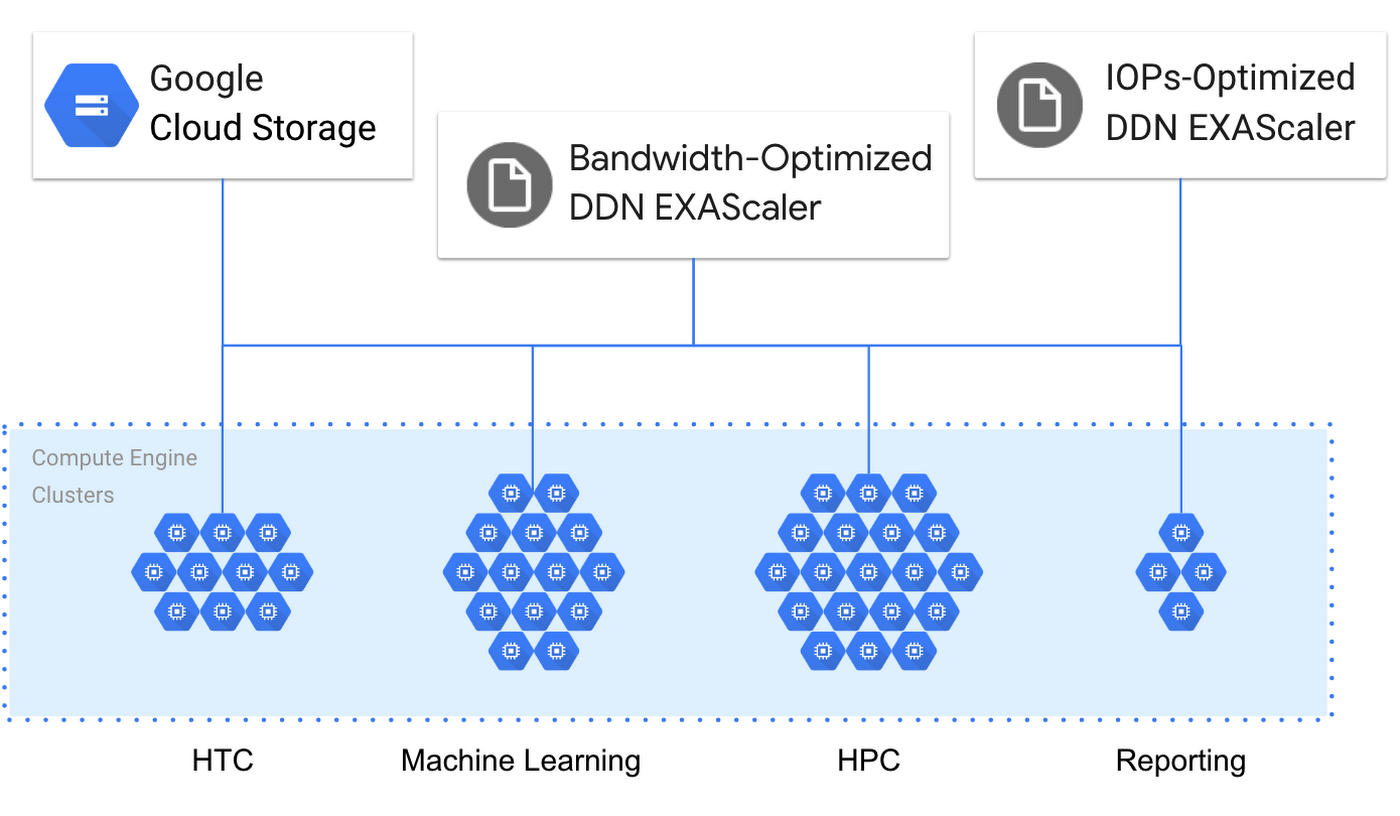
If you’re running HPC workloads on-prem, EXAScaler on Google Cloud can help model on-premises Lustre deployments in advance to ensure they are provisioned appropriately before the hardware is ordered and deployed. Due to the complexity of workloads, it can be hard to know the best economic blend of capacity, performance, bandwidth, IOPS, metadata and more before you deploy. Quickly prototyping different configurations quickly and cheaply can ensure a good experience from the start.
What’s next for cloud HPC
Try the Google Cloud and DDN Lustre solution from the GCP Marketplace. Keep an eye out for exciting new features as we upgrade to EXAScaler in the coming months.
For more tips on running HPC apps in Google Cloud, watch our talk from Google Cloud Next ’19. You can also learn more about DDN’s other products for data migration to GCP and workload analysis to fine-tune your deployment.


