Why we used Elastifile Cloud File System on GCP to power drug discovery
Woody Sherman
Chief Science Officer, Silicon Therapeutics
Vipin Sachdeva
Principal Investigator, Silicon Therapeutics
[Editor’s note: Last year, Silicon Therapeutics talked about how they used Google Cloud Platform (GCP) to perform massive drug discovery virtual screening. In this guest post, they discuss the performance and management benefits they realized from using the Elastifile Cloud File System and CloudConnect. If you’re looking for a high-performance file system that integrates with GCP, read on to learn more about the environment they built.]
Here, at Silicon Therapeutics, we’ve seen the benefits of GCP as a platform for delivering massive scale-out compute, and have used it as an important component of our drug discovery workload. For example, in our past post we highlighted the use of GCP for screening millions of compounds against a conformational ensemble of a flexible protein target to identify putative drug molecules.
However, like a lot of high-performance computing workflows, we encounter data challenges. It turns out, there are a lot of data management and storage considerations involved with running one of our core applications, molecular dynamics (MD) simulations, which involve the propagation of atoms in a molecular system over time. The time-evolution of atoms is determined by numerically solving Newton's equations of motion, where forces between the atoms are calculated using molecular mechanics force fields. These calculations typically generate thousands of snapshots containing the atomic coordinates, each with tens of thousands of atoms, resulting in relatively large trajectory files. As such, running MD on a large dataset (e.g. the entirety of the ~100,000 structures in the Protein Data Bank (PDB)) could generate a lot of data (over a petabyte).
In scientific computing, decreasing the overall time-to-result and increasing accuracy are crucial in helping to discover treatments for illnesses and diseases. In practice, doing so is extremely difficult due to the ever-increasing volume of data and the need for scalable, high-performance, shared data access and complex workflows. Infrastructure challenges, particularly around file storage, often consume valuable time that could be better spent on core research, thus slowing the progress of critical science.
Our physics-based workflows create parallel processes that generate massive amounts of data, quickly. Supporting these workflows requires flexible, high-performance IT infrastructure. Furthermore, analyzing the simulation results to find patterns and discover new druggable targets means sifting through all that data—in the case of this run, over one petabyte. That kind of infrastructure would be prohibitively expensive to build internally.
The public cloud is a natural fit for our workflows, since in the cloud, we can easily apply thousands of parallel compute nodes to a simulation or analytics job. However, while cloud is synonymous with scalable, high-performance compute, delivering complementary scalable, high-performance storage in the cloud can be problematic. We’re always searching for simpler, more efficient ways to store, manage, and process data at scale, and found that the combination of GCP and the Elastifile cross-cloud data fabric could help us resolve our data challenges, thus accelerating the pace of research.
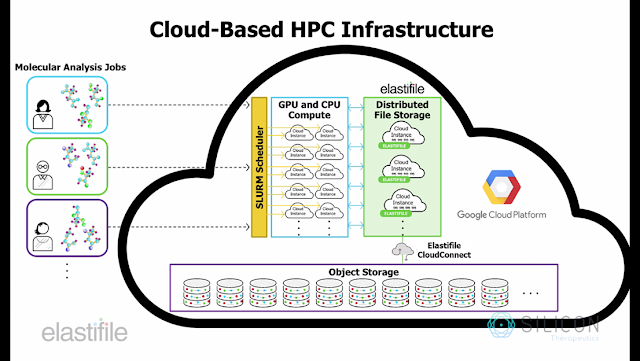
Why high-performance, scale-out file storage is crucial
To effectively support our bursty molecular simulation and analysis workflows, we needed a cloud storage solution that could satisfy three key requirements:- File-native primary storage - Like many scientific computing applications, the analysis software for our molecular simulations was written to generate and ingest data in file format from a file system that ensures strict consistency. These applications won’t be refactored to interface directly with object storage systems like Google Cloud Storage any time soon—hence the need for a cloud-based, POSIX-compliant file system.
- Scalable global namespace - Stitching together file servers on discrete cloud instances may suffice for simple analyses on small data sets. However, the do-it-yourself method comes up short as datasets grow and when you need to share data across applications (e.g., in multi-stage workflows). We needed a modern, fully-distributed, shared file system to deliver the scalable, unified namespace that our workflows require.
- Cost-effectiveness - Finally, when managing bursty workloads at scale, rigid storage infrastructure can be prohibitively expensive. Instead, we needed a solution that could be rapidly deployed/destroyed, to keep our infrastructure costs aligned to demand. And ideally, for maximum flexibility, we also wanted a solution that could facilitate data portability, both 1) between sites and clouds, and 2) between formats—file format for “active” processing and object format for cost-optimized “inactive” storage/archival/backup.
Solving the file storage problem
To meet our storage needs and support the evolving requirements of our research, we worked with Elastifile, whose cross-cloud data fabric was the backbone of our complex molecular dynamics workflow.The heart of the solution is the Elastifile Cloud File System (ECFS), a software-only, distributed file system designed for performance and scalability in cloud and hybrid-cloud environments. Built to support the noisy, heterogeneous environments encountered at cloud-scale, ECFS is well-suited to primary storage for data-intensive scientific computing workflows. To facilitate data portability and policy-based controls, Elastifile file systems are exposed to applications via Elastifile “data containers.” Each file system can span any number of cloud instances within a single namespace, while maintaining the strict consistency required to support parallel, transactional applications in complex workflows.
By deploying ECFS on GCP, we were able to simplify and optimize a molecular dynamics workflow. We then applied it to 500 unique proteins as a proof of concept for the aforementioned PDB-wide screen. For this computation, we leveraged a SLURM cluster running on GCP. The compute nodes were 16 n1-highcpu-32 instances, with 8 GPUs attached to every instance for a total of 120 K80 GPUs and 512 CPUs. The storage capacity was provided by a 6 TB Elastifile data container mounted on all the compute nodes.
Before Elastifile, provisioning and managing storage for such workflows was a complex, manual process. We partitioned the input datasets manually and created several different clusters, each with their own disks. This was because a single large disk often led to NFS issues, specifically with large metadata. In the old world, once the outputs of each cluster were completed, we stored the disks as snapshots. For access, we spun up an instance and shared the credentials for data access. This access pattern was error-prone as well as insecure. Also, at scale, manual processes such as these are time-consuming and introduce risk of critical errors and/or data loss.
With Elastifile, however, deploying and managing storage resources was quick and easy. We simply specified the desired storage capacity, and the ECFS cluster was automatically deployed, configured and made instantly available to the SLURM-managed compute resources . . . all in a matter of minutes. Also, if we want, we can expand the cluster later for additional capacity, with the push of a button. This future-proofs the infrastructure to be able to handle dynamically changing workflow requirements and data scale. By simplifying and automating the deployment process for a cloud-based file system, Elastifile reduced the complexity and risk associated with manual storage provisioning.
In addition, by leveraging Elastifile’s CloudConnect service, we were able to seamlessly promote and demote data between ECFS and Cloud Storage, minimizing infrastructure costs. Elastifile CloudConnect makes it easy to move the data to Google buckets from Elastifile’s data container, and once the data has moved, we can tear down the Elastifile infrastructure, reducing unnecessary costs.
This data movement is essential to our operations, since we need to visualize and analyze subsets of this data on our local desktops. Moving forward, leveraging Elastifile’s combination of data performance, parallelism, scalability, shareability and portability will help us perform more—and larger-scale—molecular analyses in shorter periods of time. This will ultimately help us find better drug candidates, faster.
As a next step, we’ll work to scale the workflow to all of the unique protein structures in the PDB and perform deep-learning analysis on the resulting data to find patterns associated with proteins dynamics, druggability and tight-binding ligands.
To learn more about how Elastifile supports highly-parallel, on-cloud molecular analysis on GCP, check out this demo video and be sure to visit them at www.elastifile.com.


