Predicting community engagement on Reddit using TensorFlow, GDELT, and Cloud Dataflow: Part 3
Sergei Sokolenko
Cloud Dataflow Product Manager
In Part 1 of our blog series we previewed TensorFlow models that combined traditional natural language processing (NLP) techniques such as entity and topic extraction, and deep learning techniques such as embeddings to predict with 92% accuracy which Reddit community (subreddit) a news article would land for discussion, and estimated the popularity score and volume of comments such post would generate. Part 2 of the series went into detail of developing and tuning these models. In this blog we will review the feature preprocessing infrastructure based on Cloud Dataflow and BigQuery that we built for these models.
Our first task was to place the GDELT and Reddit data into a database that was easy to query. BigQuery was the natural choice here. There are GDELT and Reddit BigQuery datasets already, but we wanted to do a deeper sentiment analysis on the raw content of news articles and Reddit posts and comments, and for that we used the Dataflow Opinion Analysis project (GitHub repo) we wrote about earlier.
Back in June 2017 Reza Rokni and John LaBarge—two GCP solutions architects—shared their best practices for developing production-quality Dataflow pipelines in a two-part blog series here (1) and here (2). As we were solidifying the design for our data preparation pipeline, we used several of these best practices to future-proof our opinion analysis infrastructure. The rest of the article will explain in more detail how we applied these Dataflow design practices to the data problems we encountered in building our training dataset.
The top 10 design patterns for Dataflow can be roughly divided according to the lifecycle of a Dataflow pipeline:
- Orchestrating the execution of a pipeline
- Onboarding external data
- Joining data
- Analyzing data and
- Writing data
CoGroupByKey pattern. When performing data analysis, we relied on the GroupByKey pattern to implement composite keys with multiple properties. And, lastly, when dealing with invalid or malformed input data, we implemented a Cloud Bigtable sink that collected invalid input records according to the dead letter queue pattern.Let's dive deeper into how these patterns helped us assemble our training dataset.
As we mentioned before, we sourced half of our training set (the features) from GDELT using files in gzipped JSON format. The other half of our training set (the labels) are Reddit posts and their comments, available in a BigQuery dataset in two tables: posts and comments. We wanted to run both the GDELT news articles and the Reddit posts/comments through a very similar processing pipeline, extracting subjects and sentiments from both of them, and storing the results in BigQuery. We therefore wrote a Dataflow pipeline that can change its input source depending on a parameter we pass to the job, but does all the downstream processing in the same way. Ultimately, we ended up with two BigQuery datasets that had the same schema, and that we could join with each other via the URL of the news article post using BiqQuery's SQL.
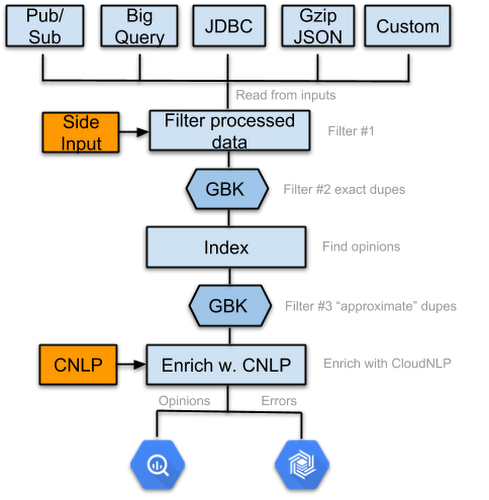
Here is the high-level design of the Dataflow pipeline that we used to bring both the GDELT and Reddit data over to BigQuery.
- Read from inputs
- Filter already processed URLs
- Filter exact duplicates
- Index (extract opinions and tags)
- Filter “approximate” duplicates
- Enrich with Cloud NLP
- Write output records (opinions found in the text) to BigQuery and invalid inputs to Bigtable
Joining data
As we were implementing the input reader for Reddit data, we had to join the posts and comments tables together. We used theCoGroupByKey design pattern to implement this join. For each dataset in the join we created a key-value (KV) pair and then applied the CoGroupByKey operation to match the keys between the two datasets. After the join, we iterated over the results to create a single entity that had both post and comment information.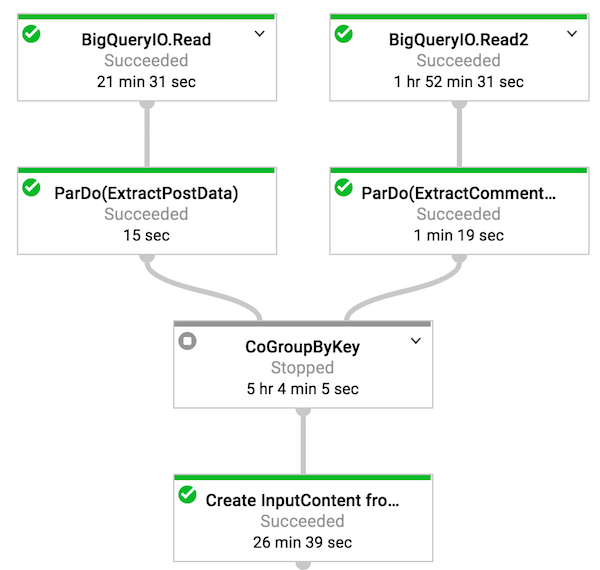
Pro tips:
- Side Inputs could be a faster alternative to
CoGroupByKeywhen joining datasets if one of the datasets can fit into the memory of a Dataflow worker VM. - Use the Cloud Dataflow Shuffle for better performance of your
CoGroupByKey. Add the following parameter to your pipeline:
--experiments=shuffle_mode=service
Grouping data
After reading our inputs—either news articles from GDELT or posts from Reddit—we proceeded to eliminate duplicates from our data. Duplicate elimination is typically done either by looking up a record ID among a list of already processed IDs, or, if the record wasn't yet processed, by grouping unprocessed data elements by some key that represents uniqueness and picking one of these elements to represent the entire group.There are three levels of filtering in our pipeline that use both of these techniques. In the first filter we simply check if the URL of the record (in effect, the ID column in our dataset) was already processed and stored in BigQuery. For this check, we use a side input consisting of the hashed URLs and populate it from the BigQuery dataset we are writing to.
In the second and third filters, which we apply only to news articles in GDELT, we are looking at the contents of the news article. We don't need to do this filtering of Reddit records because our data source guarantees uniqueness of posts. However, the GDELT data source is highly redundant, reflecting the fact that the world of news is also highly repetitive.
Original news stories are still being written by staff at major news publications or by bloggers, but a large percentage of news websites, especially regional publications, reposts news from news wires such as Associated Press, Reuters, Agence France Presse, Deutsche Welle, and others. Our pipeline attempts to identify such reposts and cluster them in groups.
A note on terminology we will use in the remainder of this blog:
- Original post: a web page where the original news story was published for the first time
- Repost: a web page which re-posted/republished an original story
- Publisher: the domain where a story (original or reposted) was published
After this initial, simplistic grouping, we then try to group articles that have small variations in text, for example, because they prefix the source of the publication, e.g. (“CHICAGO (AP)“), or because they add a copyright statement at the end. This is a more advanced grouping than just taking a hash over the text. Here, we need to group on combinations of attributes of the article.
The grouping pattern recommends defining a class that has all of the attributes by which you want to group, and then tag this class with AvroCoder as the @DefaultCoder of the class. By doing that we get for free the serialization/deserialization of objects of this class, and we can then use the GroupByKey transform to group by all the attributes of the class.
The following code sample demonstrates how to use a composite key class ContentSoftDeduplicationKey to group data elements:
The document attributes that have shown to be effective in finding similar content—and that we use for grouping—include the title of document, document length rounded to a thousand characters, and the topics that are discussed in the articles. The title and document length are values we retrieve with no additional processing because they are part of the source dataset. To return topics of the document we need to run NLP and sentiment analysis, and this is why this third and last filtering step is slotted behind the "Indexing" step. The content-based grouping is highly accurate and allows us to reduce the number of stories we insert into our analysis dataset by about 45%. For example, in June 2017 there were 6.1M web pages from which the GDELT project extracted English-language news, but only 3.7M unique stories. The additional benefit from this deduplication is that we are able to aggregate the social impact of all the reposts of an original story.
Dealing with malformed data
As we processed text documents in the Indexing step, we sometimes encountered cases where the inputs were malformed and could not be processed. For example, in GDELT we sometimes saw text full of CSS formatting, the result of edge cases in the GDELT web crawler. Or, and this is typical for social content on Reddit, we saw posts that consisted entirely of Emoticons or Unicode symbol characters that could not be processed by NLP libraries. This is another opportunity to access our bag of patterns. Normally, a developer would place a potentially "dangerous" block of code into a try/catch block and handle exceptions by logging them. The dead letter processing design pattern recommends, in addition to logging, redirecting such bad records into a Side Output and then storing them in a database that supports fast writes, for example Bigtable, Datastore or BigQuery. It then recommends periodically reviewing the contents of the Dead Letter tables and debug these bad records, determining the cause of the exceptions. Usually, a change in business logic, covering the additional edge case, or improving data collection will be needed to address bad records, but at the very least, we are not ignoring these errors and preserve data that would have been otherwise lost. In our pipeline, we implemented a side output in the Indexing step and a Bigtable sink for this side output.Calling external services for data enrichment
We've talked about how the Indexing step of the pipeline finds topics of documents by using the Sirocco opinion extraction library. Sirocco is not the only way to generate topics from documents. Cloud Natural Language provides an API for classifying a text document into roughly 700 categories. Additionally, it provides mechanisms for extracting entities from text, which is very similar to what Sirocco does. We integrated entity extraction by Cloud Natural Language with entity extraction by Sirocco into our pipeline to benefit from a richer classification of text in our pipeline, and to do that we applied another pattern from the pattern blog posts.After the opinion extraction in the Indexing step, the Cloud Nautural Language enrichment, and final filtering steps, we are finally ready to insert data into BigQuery. Note that both the Reddit and GDELT data will end up in distinct datasets, but the schemas of these datasets are the same, so we can join the news articles in GDELT with the Reddit posts via the URL field of the news post.
This concludes the third and final part of our blog series, in which we showed how to prepare the data for model training. We extracted features from our GDELT article dataset such as the entities found in the article, the author or the news post, publication date and time, and the sentiment. We extracted our training labels from the Reddit posts and comments, including the submitter of the Reddit post, the subreddit, and the sentiment of comments. We cleaned our training data of duplicates, and in the process, we gained useful information about reposts, which will help us provide a more accurate estimate of the net social impact.
Next steps
We hope you can apply these Cloud Dataflow best practices to your own data processing pipelines. Here are a few useful links if you want to learn more:- Predicting community engagement on Reddit using Tensorflow, GDELT and Cloud Dataflow: Part 1
- Predicting community engagement on Reddit using Tensorflow, GDELT and Cloud Dataflow: Part 2
- Guide to common Cloud Dataflow use-case patterns, Part 1
- Guide to common Cloud Dataflow use-case patterns, Part 2
- Dataflow Opinion Analysis GitHub repository



