Optimizing your Cloud Storage performance: Google Cloud Performance Atlas
Colt McAnlis
Developer Advocate
Google Cloud Storage is Google Cloud Platform’s powerful unified object storage that can meet most if not all of your developer needs. Out of the box, you get close-to-user-edge serving, CDN capabilities, automatic redundancy and the knowledge that you’re using a service that can even help reduce your storage carbon emissions to zero!
That being said, every developer has a unique use case and specific requirements for how they use Cloud Storage. While its out-of-the-box performance is quite impressive, here are a few pro tips, tweaks and suggestions to help you optimize for your particular use case.
Establishing baseline performance
First off, you can’t fix what you can’t measure. As such, it’s important to establish a baseline expectation of the performance of a Cloud Storage bucket. To this end, we suggest running the perfdiag utility which runs a set of tests to report the actual performance of a Cloud Storage bucket. It has lots of options, so that you can tune it as closely as possible to match your own usage pattern, which can help set expectations, and, if there’s a performance difference, help track down where the problem might be.Improving upload performance
How to upload small files fasterEach Cloud Storage upload transaction has some small overhead associated with it, which in bulk scenarios, can quickly dominate the performance of the operation. For example, when uploading 20,000 files that are 1kb each, the overhead of individual upload takes more time than all the entire upload time altogether. This concept of overhead-per-operation is not new, nor is the solution: batch your operations together. If you’ve ever done SIMD programming on the CPU, for example, you’ve seen firsthand how batch operations mitigates the overhead of each operation across the set, improving performance.
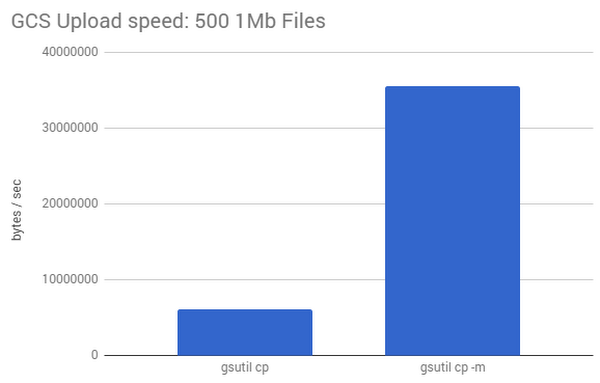
To this end, gsutil provides the "-m" option that performs a batched, parallel (multi-threaded/multi-processing) upload from your local machine to your cloud bucket, which can significantly increase the performance of an upload. Here’s a test that compares uploading 100 200k files individually and batch uploading them using "gsutil -m cp". In the example below, upload speeds increase by more than 5X by using this flag.
More efficient large file uploads
The gsutil utility can also automatically use object composition to perform uploads in parallel for large, local files that you want to upload to Cloud Storage. It splits a large file into component pieces, uploads them in parallel and then recomposes them once they're in the cloud (and deletes the temporary components it created locally). You can enable this by setting the `parallel_composite_upload_threshold` option on gsutil (or, updating your .boto file, like the console output suggests).
Where "localbigfile" is a file larger than 150MB. This divides up your data into chunks ~150MB and uploads them in parallel, increasing upload performance. (Note, there are some restrictions on the number of chunks that can be used. Refer to the documentation for more information.)
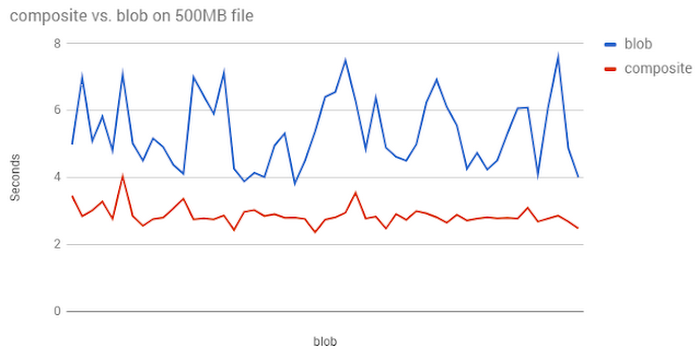
Here’s a graph that compares the speed of uploading 100 500MB files using regular vs. composite uploads.
Avoid the sequential naming bottleneck
When uploading a number of files to Cloud Storage, the Google Cloud frontends auto-balance your upload connections to a number of backend shards to handle the transfer. This auto-balancing is, by default, done through the name/path of the file, which is very helpful if the files are in different directories (since each one can be properly distributed to different shards).This means that how you name your files can impact your upload speed.
For example, imagine you’re using a directory structure that includes a timestamp:
YYYY/MM/DD/CUSTOMER/timestamp
This can cause an upload speed issue, since the majority of your connections will all be directed to the same shard, since the filenames are so similar. Once the number of connections gets high enough, performance can quickly degrade. This scenario is very common with datasets which have a deep connection to a timestamp (like photographs, or sensor data logs).
A simple solution to this issue is to simply re-name your folder or file structure such that they are no longer linear. For example, prepending a uniformly distributed hash (over a fixed range) to the filenames breaks the linearity and allows the load balancers to do a better job at partitioning the connections.
Below, you can see the difference between how long it took to upload a set of files named linearly, vs. ones that were prepended with a hash:

It’s worth noting that if this renaming process breaks some data-dependencies in your pipeline, you can always run a script to remove the hashes on the files once the upload is finished.
Improving download performance
Set your optimal fetch sizeAs mentioned before, Cloud Storage has fixed transactional overhead per request. For downloads (much like uploads), this means you can achieve improved performance by finding the sweet spot between the size of the request, and the number of requests that have to be made to download your data.
To demonstrate this, let’s take an 8MB file, and fetch it through different sized chunks. In the graph below, we can see that as the block size gets larger, performance improves. As the chunk size decreases, the overhead per-transaction increases, and performance slows down.
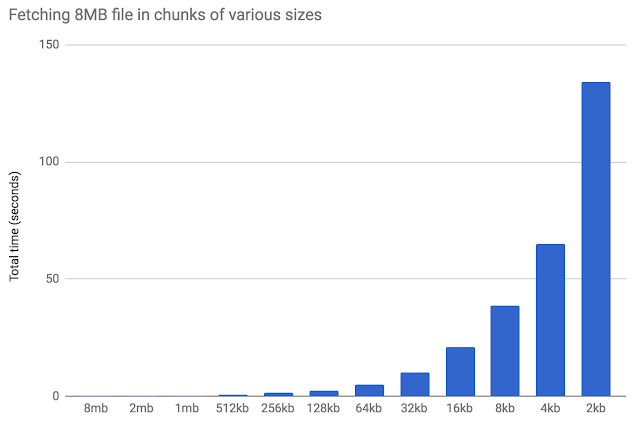
What this graph highlights is that Cloud Storage is extremely strong in terms of single-stream throughput. That means that for both uploads and downloads, Cloud Storage performance is at its best for larger requests of around 1MB in size. If you have to use smaller requests, try to parallelize them, so that your fixed latency costs overlap.
Optimizing GSUTIL reads for large files
If you need to download multi-gigabyte files to an instance for processing, it’s important to note that gsutil’s default settings aren’t optimized for large-file transfer. As a result, you might want to adjust your use of slicing, and threadcount to improve performance.The default settings for GSUTIL spread file downloads to four threads, but only use a single process. To copy a single file onto a powerful Compute Engine VM, we can improve the performance by limiting the number of threads, forcing the system to use multiple processes instead.
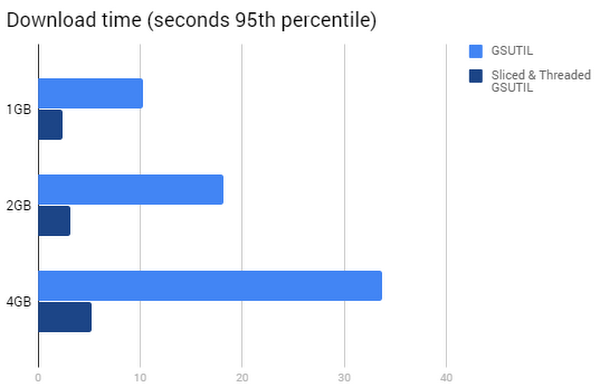
For large files, GSUTIL has a nifty feature that can help even further. Gsutil uses HTTP Range GET requests to perform "sliced" downloads in parallel when downloading large objects from Cloud Storage.
You can see in the graph below that using sliced and threaded downloads with HTTP Range GET requests is a big time-saver.
So there you have it folks—some quick and dirty tricks to help you get the most performance out of your Cloud Storage environment. If you have any other tips that you’ve found helpful, reach out to me on social media, and let me know if there are other topics you’d like me to cover. And don’t forget to subscribe to the Google Cloud Platform Youtube channel for more great tips and tricks for optimizing your cloud application.



