New ways to manage sensitive data with the Data Loss Prevention API
Scott Ellis
Senior Product Manager
If your organization has sensitive and regulated data, you know how much of a challenge it can be to keep it secure and private. The Data Loss Prevention (DLP) API, which went beta in March, can help you quickly find and protect over 50 types of sensitive data such as credit card numbers, names and national ID numbers. And today, we’re announcing several new ways to help protect sensitive data with the DLP API, including redaction, masking and tokenization.
These new data de-identification capabilities help you to work with sensitive information, while reducing the risk of sensitive data being inadvertently revealed. If like many enterprises you follow the principle of least privilege or need-to-know access to data (only use or expose the minimum data required for an approved business process) the DLP API can help you enforce these principles in production applications and data workflows. And because it’s an API, the service can be pointed at any virtually any data source or storage system. DLP API offers native support and scale for scanning large datasets in Google Cloud Storage, Datastore and BigQuery.
Google Cloud DLP API enables our security solutions to scan and classify documents and images from multiple cloud data stores and email sources. This allows us to offer our customers critical security features, such as classification and redaction, which are important for managing data and mitigating risk. Google’s intelligent DLP service enables us to differentiate our offerings and grow our business by delivering high quality results to our customers.
— Sateesh Narahari, VP of Products, Managed Methods
New de-identification tools in DLP API
De-identifying data removes identifying information from a dataset, making it more difficult to associate the remaining data with an individual and reducing the risk of exposure.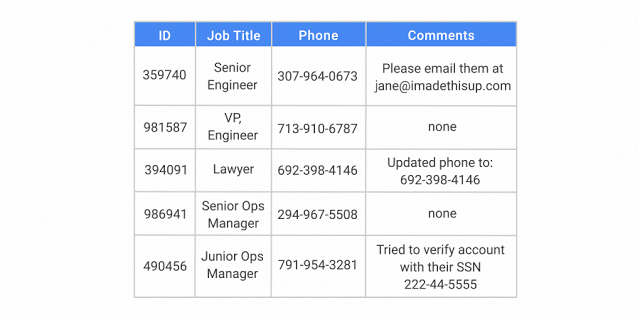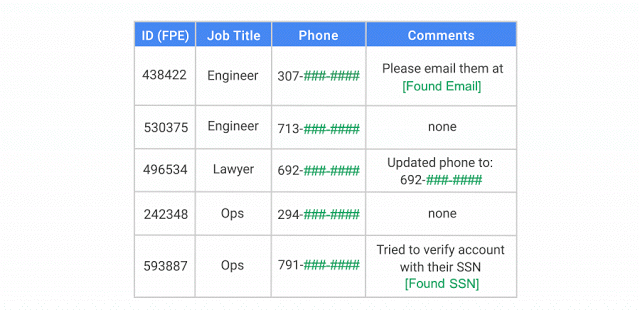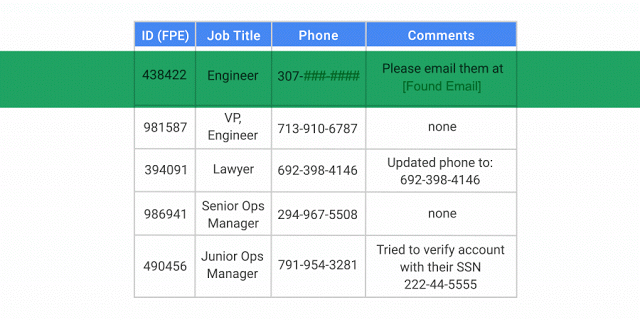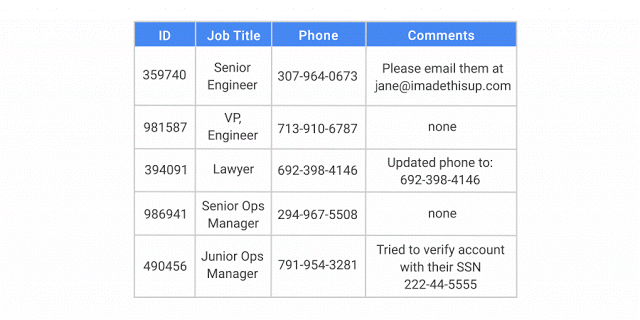
The DLP API now supports a variety of new data transformation options:
Redaction and suppression
Redaction and suppression remove entire values or entire records from a dataset.
For example, if a support agent working in a customer support UI doesn’t need to see identifying details to troubleshoot the problem, you might decide to redact those values. Or, if you’re analyzing large population trends, you may decide to suppress records that contain unique demographics or rare attributes, since these distinguishing characteristics may pose a greater risk.

Partial masking
Partial masking obscures part of a sensitive attribute — for example, the last 7 digits of a US telephone number. In this example, a 10-digit phone number retains only the area code.
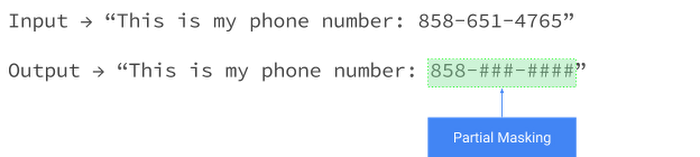
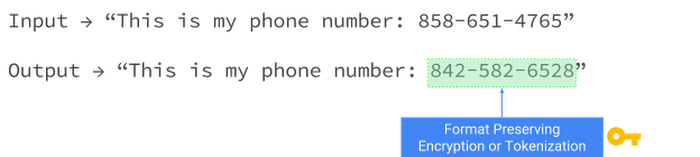
Tokenization or secure hashing
Tokenization, also called secure hashing, is an algorithmic transformation that replaces a direct identifier with a pseudonym or token. This can be very useful in cases where you need to retain a record identifier or join data but don’t want to reveal the sensitive underlying elements. Tokens are key-based and can be configured to be reversible (using the same key) or non-reversible (by not retaining the key).
The DLP API supports the following token types:
- Format-Preserving Encryption - a token of the same length and character set.
- Secure, key-based hashes - a token that's a 32-byte hexadecimal string generated using a data encryption key.

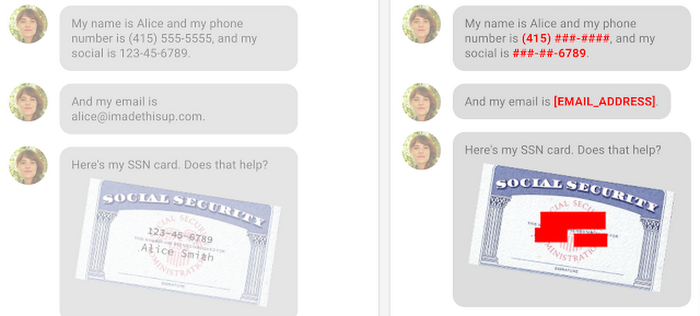
Dynamic data masking
The DLP API can apply various de-identification and masking techniques in real time, which is sometimes referred to as “Dynamic Data Masking” (DDM). This can be useful if you don’t want to alter your underlying data, but want to mask it when viewed by certain employees or users. For example, you could mask data when it’s presented in a UI, but require special privileges or generate additional audit logs if someone needs to view the underlying personally identifiable information (PII). This way, users aren’t exposed to the identifying data by default, but only when business needs dictate.
Bucketing, K-anonymity and L-Diversity
The DLP API offers even more methods that can help you transform and better understand your data. To learn more about bucketing, K-anonymity, and L-Diversity techniques, check out the docs and how-to guides.



