Managing streaming pipelines in Google Cloud Dataflow just got better
Matt Lang
Software Engineer
We're happy to introduce a new option for stopping your streaming Google Cloud Dataflow job: Drain. When a job is stopped using Drain, Dataflow waits for all in-flight data to be processed before gracefully shutting down your job. This addition increases the flexibility of managing streaming pipelines running on the Cloud Dataflow service and provides a different set of processing semantics guarantees from existing alternatives. Read on to learn about how to use Drain, Cancel and Update to make changes to your streaming Dataflow pipelines.
Making changes to streaming pipelines
Maintaining a production pipeline, like any production system, requires regular (or in some cases, continuous) updates.Let's say your gaming analytics pipeline is up and scaling to meet demand, but you realize you'd like to tweak how long of a gap between records is considered a session. In batch analytics, this is easy: you make the change and deploy the new code between runs. With streaming, making this sort of change is more complicated.
Cloud Dataflow makes this task less painful by providing you with different options to update pipeline code. When you need to update a streaming pipeline running on the Cloud Dataflow service, you can follow one of two paths: use Dataflow's update feature to replace a currently running pipeline with a new version, or manually stop an existing pipeline and start a new pipeline in its place by performing a manual swap.
Using Update
Any currently running Dataflow job likely has in-flight data — data that’s already been read from input sources and buffered, but that has not yet been emitted to a sink. The pipeline may, for example, use Dataflow's Windowing and Triggers features to aggregate data into Windows based on event-time. Your pipeline may have many "open" windows with buffered data that are waiting for the event-time watermark to advance beyond the window's event-time trigger.With Update, it’s possible to replace an existing pipeline in-place with the new one and preserve Dataflow's exactly-once processing guarantee1. All in-flight data (data buffered by the existing pipeline) will be preserved and processed by the new pipeline, and no duplicate data will be processed between the two jobs.
Updating a Cloud Dataflow job is easy: simply run the new Cloud Dataflow job with the --update flag and ensure that the --jobName flag is the same as the name of the job you want to update. Unlike some other streaming systems (like Apache Spark, where checkpoints from previous pipelines may not be used with updated code), you do not need to configure anything in advance, add manual journaling or otherwise structure your code differently in order to update the pipeline; all streaming pipelines running on the Cloud Dataflow service can be updated with no configuration necessary.
The Update feature preserves in-flight data and resumes processing it with the updated pipeline. In order to do so, it re-uses the persistent store from the old pipeline for the new pipeline. Because of this, the two pipelines must meet some compatibility requirements. For example, you cannot change Coders or side inputs during update, and if you've renamed or removed any pipeline steps in your new pipeline, you must provide a mapping between transform names in the old and new pipelines. The Dataflow service performs a compatibility check on the new job to ensure that the two pipelines are compatible2. If the new job is incompatible, it doesn't start and the old job continues running.
Update can also be used to manually scale the number of workers associated with your pipeline, subject to some bounds. For more information about Update, see the Cloud Dataflow service documentation.
Performing a manual swap
Sometimes, you may need to make changes to your pipeline that cause incompatibility between two pipelines. In this case, Update's compatibility check will fail. In order to replace an existing pipeline with an incompatible new pipeline, you have to stop your existing Dataflow job and start another in its place. Dataflow now provides two options for stopping a job: Cancel and Drain.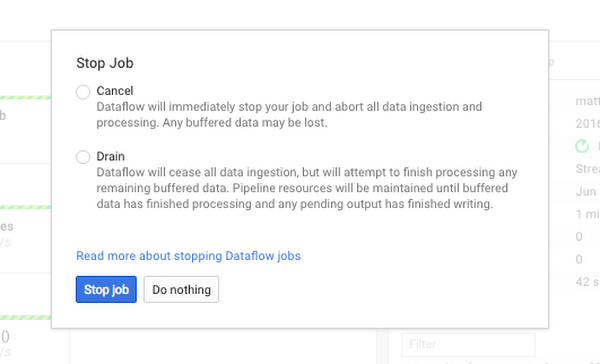
The updated "Stop Job" dialog in the Cloud Dataflow monitoring UI now provides a choice between Cancel and Drain. Draining a pipeline can also be initiated using the glcoud CLI, using the command gcloud alpha dataflow jobs drain <job_id>
Canceling a pipeline causes the job to stop and frees all resources associated with it (e.g., Google Compute Engine virtual machines, persistent disks, etc.). When a job is canceled, the pipeline stops immediately; all in-flight or buffered data is lost.
Cancelling and restarting provides the weakest set of guarantees about data processed by your jobs. It does not guarantee that only duplicate-free data will be processed between your jobs (e.g., in the case where your input sources do not provide exactly-once delivery semantics) and it allows for loss of in-flight data.
Drain, on the other hand, does not immediately stop a job. Rather, when a job is stopped using Drain, the job stops pulling from its input sources and completes processing of all in-flight and buffered data, causing all triggers to emit the contents of open windows. Note that in this case, windows may be incomplete: windows closed during a drain only contain data that was pulled from input sources and buffered before draining was initiated. Drain guarantees that all messages pulled from the pipeline's Cloud Pub/Sub sources are acknowledged and guarantees that finalize() is called on all unbounded custom sources. When Dataflow observes that all buffered data has been processed, all resources associated with the job are freed and the job is stopped.
In this way, Drain provides at-least-once processing semantics, a middle-ground between the weak guarantees of Cancel and the strong guarantees of Update; although duplicate data may be processed if sources do not guarantee exactly-once delivery, it guarantees that all in-flight data is processed (similar to Update).
| Methodology | Processing Semantics |
| Update in place | Exactly-once |
| Drain and replace | At-least-once3 |
| Cancel and replace | None |
For more information, see the Cloud Dataflow documentation on stopping a pipeline.
With this suite of tools, you can easily update pipeline code based on your processing semantics requirements, and you don't have to fear that a pipeline will become a maintenance burden.
1The Google Cloud Dataflow managed service guarantees exactly-once semantics for streaming pipelines. That is, even in the face of sources that may deliver duplicate data, Dataflow pipelines will process each unique data element once, and only once.
2The Dataflow service also optimizes your pipeline graphs, which may, in some cases, cause incompatibility.
3 If your custom source guarantees exactly-once delivery and provides source-side buffering, Drain and replace can provide exactly-once semantics.



