Google BigQuery cuts historical data storage cost in half and accelerates many queries by 10x
Tino Tereshko
Product Manager, Google BigQuery
Google BigQuery continues to define the next generation of fully-managed zero-Ops analytics data warehouses. Today BigQuery is making things faster, cheaper and easier to use.
You may have read the announcement on the release of new BigQuery features on the Google Cloud Platform Blog, and in this post we'll dive into a little bit more detail.
Long-term storage pricing
Long term storage pricing is an automatic discount for data residing in BigQuery for extended periods of time. When age of your data reaches 90 days in BigQuery, we'll automatically drop the price of storage from $0.02 per GB per month down to just a penny per GB per month.We started tracking when data is edited on February 1st, 2016, so you should see the price of your long term storage drop 90 days later, on May 1st, 2016.
Before long term storage pricing:

After long term storage pricing:

Long term storage pricing means not having to delete old data or architect a data archival process. Once this data remains in BigQuery, another added benefit is the ability to query older data using the same interface, at the same cost levels, with the same performance characteristics:
-
This discount is automatic
- There's no degradation of performance, durability or functionality whatsoever
- Query cost is the same as for Standard Storage
- Discount is counted on a per-table, per-partition basis
- If you modify the data in the table, the 90-day counter resets
Capacitor storage engine
After several years of work, we're rolling out a new storage engine, internally called Capacitor. Capacitor replaces ColumnIO, the incumbent optimized columnar storage format that plays a large role in BigQuery’s industry-leading performance characteristics. Without any visible changes or downtime, customers will be able to experience the benefits of Capacitor automatically. Performance of many queries, like simple aggregations and point lookups, will improve up to 10x, and in some cases up to 1000x!Among the many improvements, Capacitor is able to operate directly on compressed data, rather than the traditional method of decompressing the data first. This vastly increases efficiency of data processing.
Poseidon - faster import/export, without affecting query performance
We've rebuilt our import and export pipelines to use the same underlying Dremel infrastructure leveraged by queries. Not only does this retain the same benefits you've already come to expect, such as fast, free imports that have absolutely no impact on query performance, but also gives greater performance, scalability and predictability, improving ingest times by about 5x.Additionally, we're making it easier for you to query data that doesn’t reside in BigQuery storage by creating symmetry between import and query. Anything that you can import from Google Cloud Storage, you can also query directly.
A great example is that we have added support for AVRO, which can be both imported via our standard free batch process, and queried directly.
Table Partitions v1 - Alpha
(This feature will be available in the coming weeks as Alpha)The first version of table partitions will allow customers to keep data in one table, rather than the current best practice of sharding by day and combining tables through TABLE_DATE_RANGE operations. Support for automated partitioning will make processing the data cheaper, faster and easier. Furthermore, partitions give our users the table management experience they’re generally used to with traditional databases.
This version of table partitions will be set by default on the time when data is ingested into BigQuery. Future versions of table partitions will allow you to set custom date-time partitions and partitions on custom values in general.
Before Table Partitions: shard by day (customer-managed) + TABLE_DATE_RANGE (at query time)

With Table Partitions: partition by day (automatically managed by BigQuery) + select partitions (at query time)

You can also operate over individual partitions directly by adding the partition suffix. For instance, you can run the following query:
SELECT … FROM sales$20160101
Which will be equivalent to
SELECT … FROM sales WHERE _PARTITION_LOAD_TIME = TIMESTAMP(“20160101”)
Suppose you have a query that analyzes data in columns c1 and c3, but only for the dates 01/03/2016 and 01/04/2016. Before Table Partitions, BigQuery would scan the entirety of these columns, and users were charged for processing both columns, even if we only needed a portion of the data:
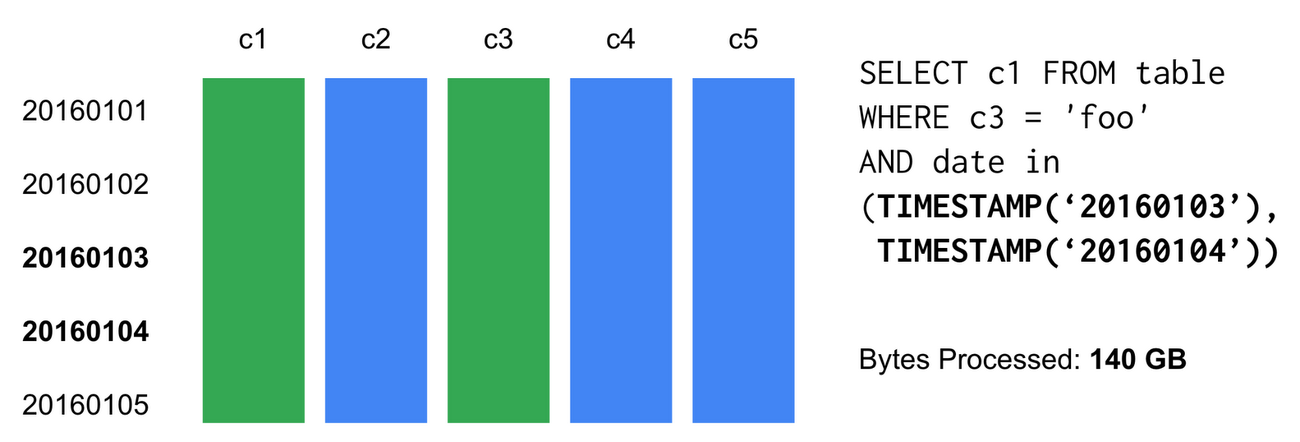
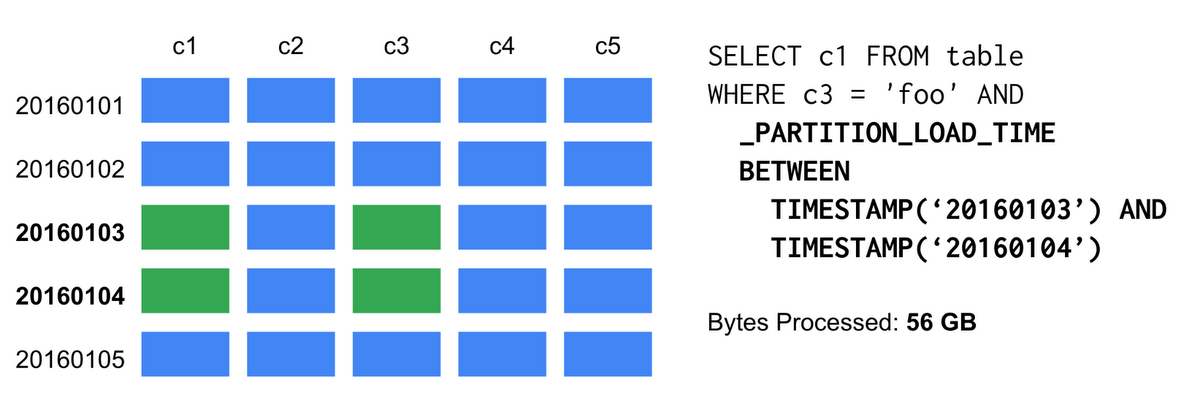
With Table Partitions, you may additionally specify which partitions to read data from. In our example, BigQuery will only read data from columns c1 and c3, and only from partitions 20160103 and 20160104. This results in better performance, as well as noticeable cost savings.
AVRO format support
You may now leverage the popular AVRO format, in addition to CSV and JSON, for both importing data into BigQuery, and for querying data from our Federated Data Sources.To query an AVRO file from Google Cloud Storage:
bq query --external_table_definition=foo::AVRO=gs://test/avrotest.avro* "SELECT * FROM foo"
And to load an AVRO file into BigQuery from Google Cloud Storage:
bq load --source_format=AVRO project:dataset.dest_table gs:://test/avrotest.avro
Automatic schema detection
Prior to today’s BigQuery release, users had to define table schemas for their CSV and JSON files. Now, BigQuery attempts to detect the schema automatically.This works for CSV, JSON and AVRO at load time:
bq load --source_format=CSV project:dataset.dest_table gs:://test/csvtest.csv
And if you choose to query this data directly from Google Cloud Storage:
bq query --external_table_definition=foo::CSV=gs://test/test.csv* "SELECT * FROM foo"
A new table create UX
BigQuery brings you a streamlined and simplified user experience for table creation in the BigQuery UI.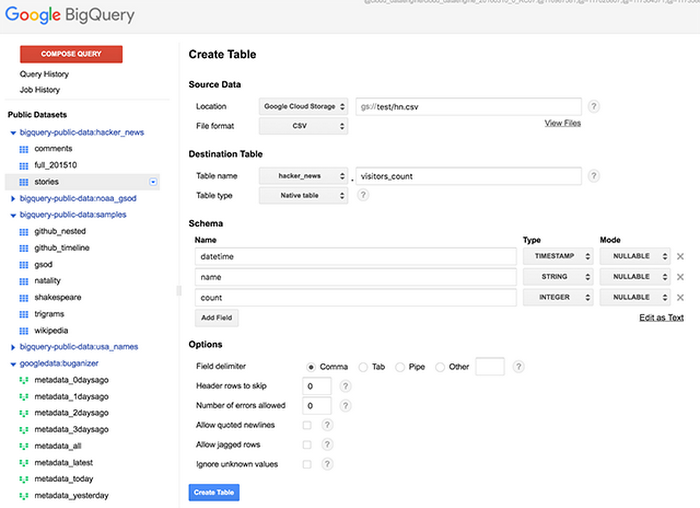
Please note that automatic schema inference will be available in the coming weeks in the UI.
Under-the-hood improvements
We're releasing many transparent under-the-hood improvements that make querying your data faster, easier and more reliable. One of these improvements is dynamic materialization of analytic functions and semi-JOINs.Our customers have come to expect exceptional reliability and performance. As usual, we will be delivering all these features to you seamlessly, without any downtime, and without any user action, the way fully managed is meant to be!



