Drilling down into Stackdriver Service Monitoring
Jay Judkowitz
Senior Product Manager
If you’re responsible for application performance and availability, you know how hard it can be to see it through the eyes of your customers and end users. We think that’s really going to change with last week’s introduction of Stackdriver Service Monitoring, a new tool for monitoring how your customers perceive your applications, and that then lets you drill down to the underlying infrastructure when there’s a problem.
Most IT operations tools take a bottoms-up understanding of IT systems: they look at compute, storage, and networking metrics to infer the customer experience. Application performance management (APM) tools like tracing systems, debuggers, and profilers consider the application from the code level—but lose sight of the underlying infrastructure. Sometimes, a logs analytics solution can provide the glue between those two layers, but often with great effort and expense.
IT operators have been missing a cost-effective, easy-to-use, general-purpose tool to monitor the customer-facing behavior of their applications. It’s hard to know how end users experience your software and it’s difficult to measure services and applications in a standardized way. Ops staff risk burning out from all the spurious alerts. The result of all this is that mean-time-to-resolution (MTTR) is longer than necessary, and customer satisfaction is lower than desired. The situation is exacerbated with microservice architectures where the app itself is broken into many small pieces, which makes it hard to understand how all the pieces fit together and where to start investigating when there is a problem.
That all changes with the release of Stackdriver Service Monitoring. Service Monitoring takes advantage of service-aware, “opinionated” infrastructure so you can monitor how end users perceive your systems, letting you drill down to the infrastructure level when necessary. Initially, we are supporting this functionality for Google App Engine and for Istio service meshes running on Google Kubernetes Engine. We will expand to more platforms over time.
With Stackdriver Service Monitoring, you get the answers to the following questions:
- What are your services? What functionality do those services expose to internal and external customers?
- What are your promises and commitments regarding the availability and performance of those services, and are your services meeting them?
- For microservices-based apps, what are the inter-service dependencies? How can you use that knowledge to double check new code rollouts and triage problems in the event of service degradation?
- Can you look at all the monitoring signals for a service holistically to reduce MTTR?
Anatomy of Stackdriver Service Monitoring
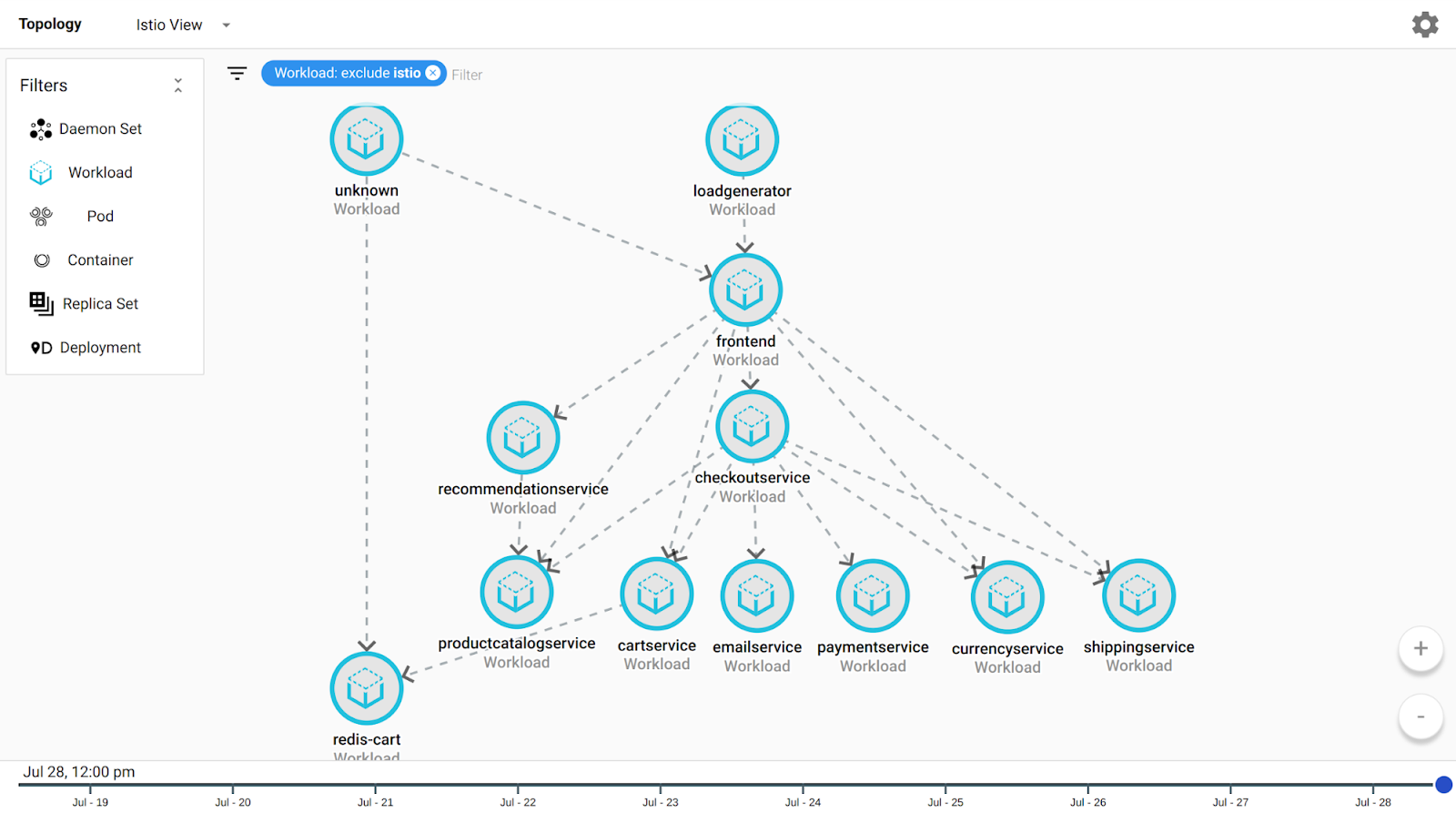
Service Monitoring has three pieces: the service graph, Service Level Objectives (SLOs), and multi-signal service dashboards. Together, these give you an inventory of your services, visually display the dependencies between them, let you set and measure availability and performance promises, help you triage application problems to quickly find the root cause, and finally, help you debug broken services more quickly than ever before. Let’s look at each piece in turn.The service graph: This is a service-specific view of your infrastructure. It starts out with a real-time top level display of all services in the Istio service mesh and the communication links between them. Selecting one service displays charts with error rates and latency metrics. Double-clicking on a service allows you to drill down into its underlying Kubernetes infrastructure, providing the long elusive connection between app behavior and infrastructure. There is also a time slider which allows you to see the graph at previous points in time. Using the service graph you can see your application architecture for reference purposes or to triage problems. You can explore metrics about service behavior, and determine whether an upstream service is causing problems to a downstream service. Finally, you can compare the service graph at different points in time to determine whether there was a significant architectural change right before a problem was reported. There is no quicker way to get started exploring and understanding complex multi-service applications.
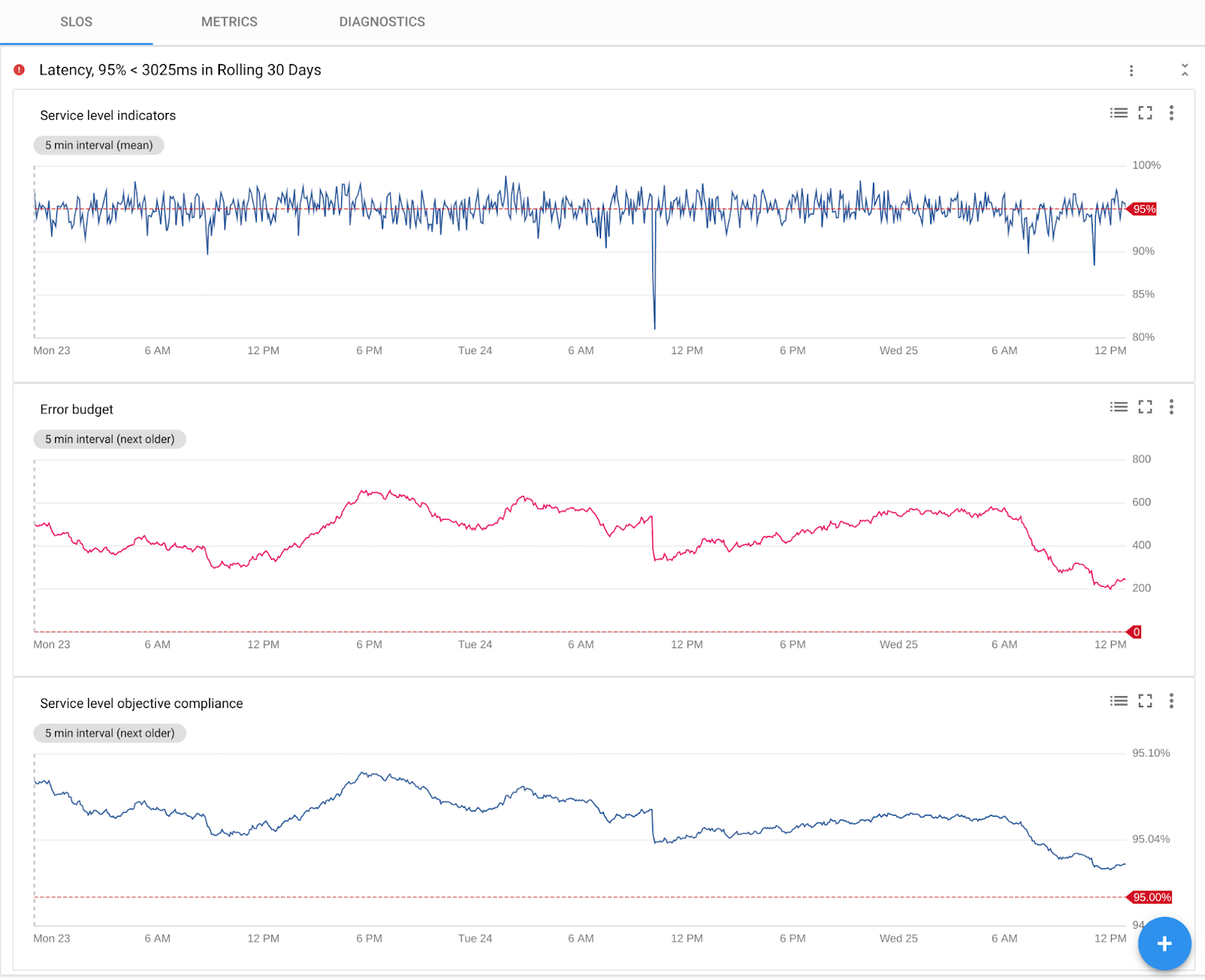
SLOs: Internally at Google, our Site Reliability Engineering team (SRE) only alert themselves on customer-facing symptoms of problems, and not all potential causes. This better aligns them to customer interests, lowers their toil, frees them to do value-added reliability engineering, and increases job satisfaction. Stackdriver Service Monitoring lets you to set, monitor, and alert on SLOs. Because Istio and App Engine are instrumented in an opinionated way, we know exactly what the transaction counts, error counts, and latency distributions are between services. All you need to do is set your targets for availability and performance and we automatically generate the graphs for service level indicators (SLIs), compliance to your targets over time, and your remaining error budget. You can configure the maximum allowed drop rate for your error budget; if that rate is exceeded, we notify you and create an incident so that you can take action. To learn more about SLO concepts including error budget, we encourage you to read the SLO chapter of the SRE book.
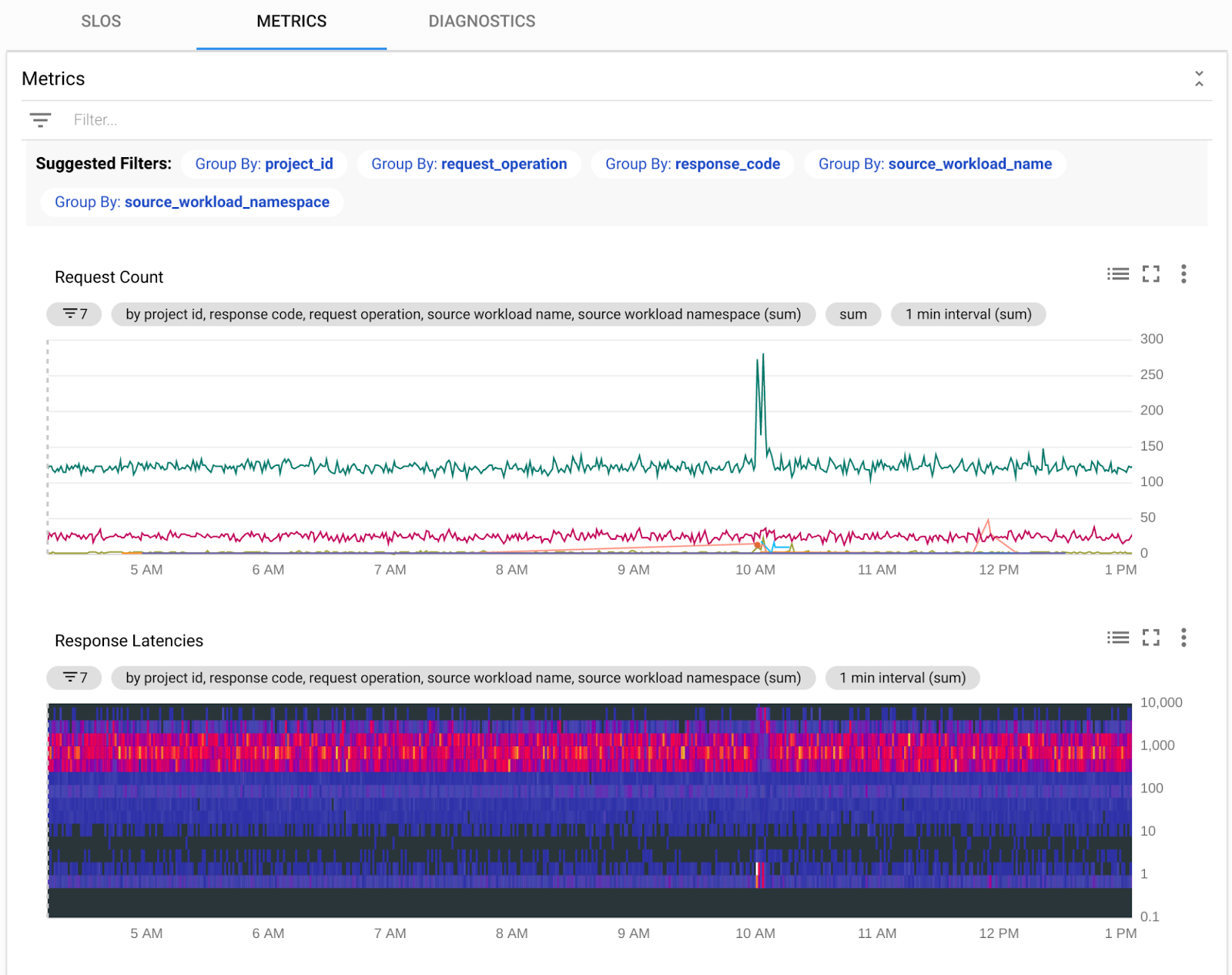
Service Dashboard: At some point, you will need to dig deeper into a service’s signals. Maybe you received an SLO alert and there’s no obvious upstream cause. Maybe the service is implicated by the service graph as a possible cause for another service’s SLO alert. Maybe you have a customer complaint outside of an SLO alert that you need to investigate. Or, maybe you want to see how the rollout of a new version of code is going.
The service dashboard provides a single coherent display of all signals for a specific service, all of them scoped to the same timeframe with a single control, providing you the fastest possible way to get to the bottom of a problem with your service. Service monitoring lets you dig deep into the service’s behavior across all signals without having to bounce between different products, tools, or web pages for metrics, logs, and traces. The dashboard gives you a view of the SLOs in one tab, the service metrics (transaction rates, error rates, and latencies) in a second tab, and diagnostics (traces, error reports, and logs) in the third tab.
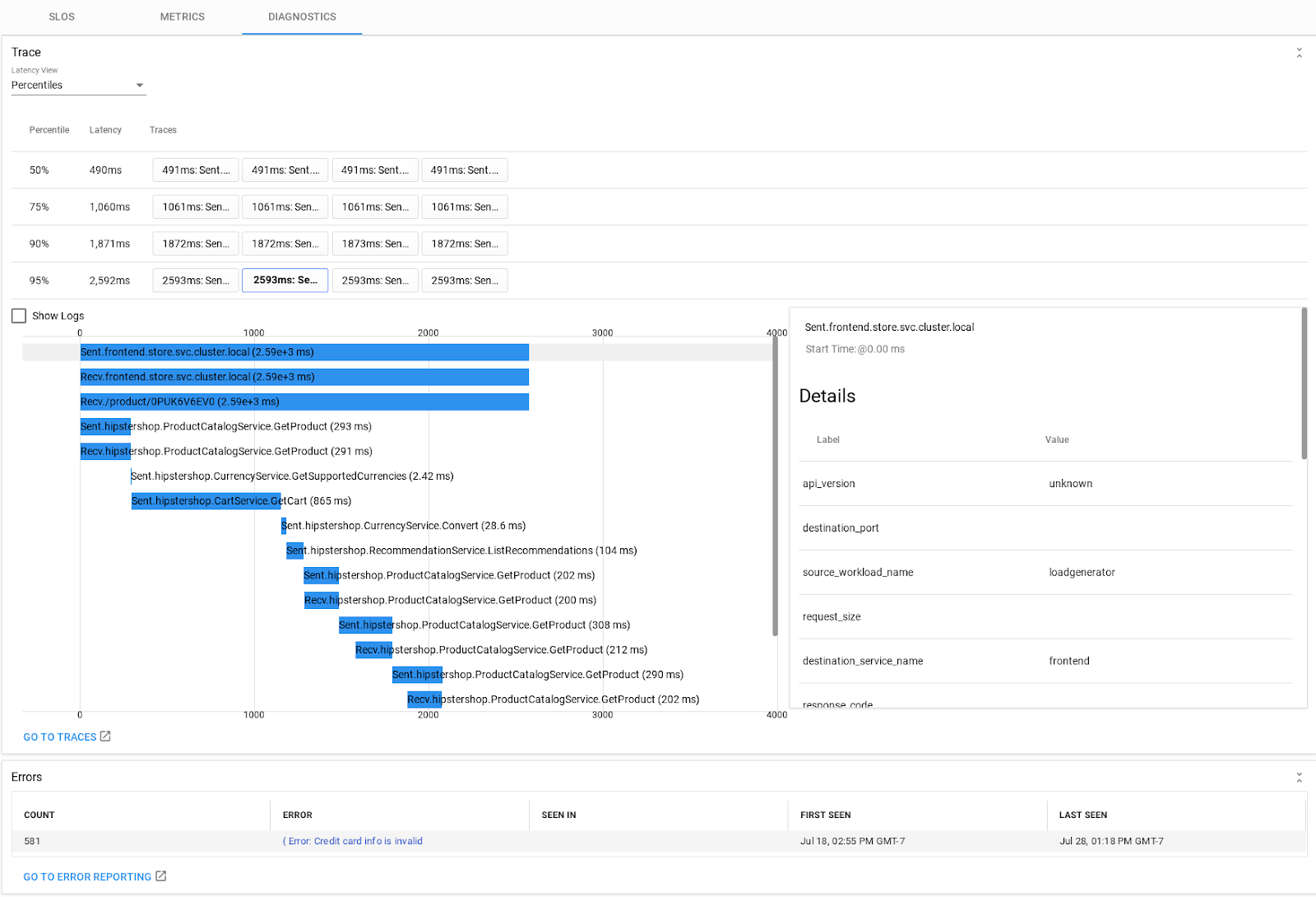
Once you’ve validated an error budget drop in the first tab and isolated anomalous traffic in the second tab, you can drill down further in the diagnostics tab. For performance issues, you can drill down into long tail traces, and from there easily get into Stackdriver Profiler if your app is instrumented for it. For availability issues you can drill down into logs and error reports, examine stack traces, and open the Stackdriver Debugger, if the app is instrumented for it.
Stackdriver Service Monitoring gives you a whole new way to view your application architecture, reason about its customer-facing behaviors, and get to the root of any problems that arise. It takes advantage of infrastructure software enhancements that Google has championed in the open source-world, and leverages the hard-won knowledge of our SRE teams. We think this will fundamentally transform the ops experience of cloud native and microservice development and operations teams. To learn more see the presentation and demo with Descartes Labs at GCP Next last week. We hope you will sign up to try it out and share your feedback.



