CRE life lessons: What is a dark launch, and what does it do for me?
Adrian Hilton
Customer Reliability Engineer, SRE
Say you’re about to launch a new service. You want to make sure it’s ready for the traffic you expect, but you also don’t want to impact real users with any hiccups along the way. How can you find your problem areas before your service goes live? Consider a dark launch.
A dark launch sends a copy of real user-generated traffic to your new service, and discards the result from the new service before it's returned to the user. (Note: We’ve also seen dark launches referred to as “feature toggles,” but this doesn’t generally capture the “dark” or hidden traffic aspect of the launch.)
Dark launches allow you to do two things:
- Verify that your new service handles realistic user queries in the same way as the existing service, so you don’t introduce a regression.
- Measure how your service performs under realistic load.
Where to fork traffic: clients vs. servers
When considering a dark launch, one key question is where the traffic copying/forking should happen. Normally this is the application frontend, i.e. the first service, which (after load balancing) receives the HTTP request from your user and calculates the response. This is the ideal place to do the fork, since it has the lowest friction of change — specifically, in varying the percentage of external traffic sent to the new backend. Being able to quickly push a configuration change to your application frontend that drops the dark launch traffic fraction back down to 0% is an important — though not crucial — requirement of a dark launch process.If you don’t want to alter the existing application frontend, you could replace it with a new proxy service which does the traffic forking to both your original and a new version of the application frontend and handles the response diffing. However, this increases the dark launch’s complexity, since you’ll have to juggle load balancing configurations to insert the proxy before the dark launch and remove it afterwards. Your proxy almost certainly needs to have its own monitoring and alerting — all your user traffic will be going through it, and it’s completely new code. What if it breaks?
One alternative is to send traffic at the client level to two different URLs, one for the original service, and the other for the new service. This may be the only practical solution if you’re dark launching an entirely new app frontend and it’s not practical to forward traffic from the existing app frontend — for instance, if you’re planning to move a website from being served by an open-source binary to your own custom application. However, this approach comes with its own set of challenges.
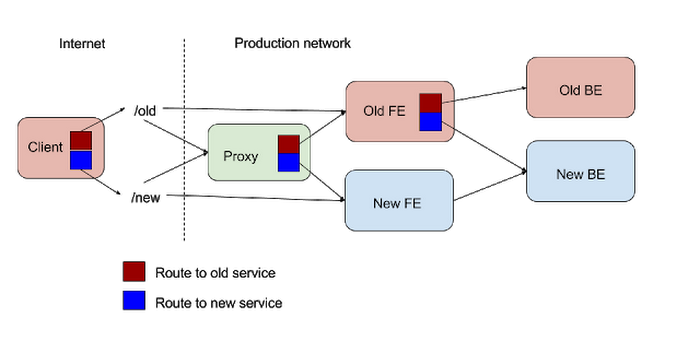
The main risk in client changes is the lack of control over the client’s behavior. If you need to turn down the traffic to the new application, then you’ll at least need to push a configuration update to every affected mobile application. Most mobile applications don’t have a built-in framework for dynamically propagating configuration changes, so in this case you’ll need to make a new release of your mobile app. It also potentially doubles the traffic from mobile apps, which may increase user data consumption.
Another client change risk is that the destination change gets noticed, especially for mobile apps whose teardowns are a regular source of external publicity. Response diffing and logging results is also substantially easier within an application frontend than within a client.
How to measure a dark launch
It’s little use running a dark launch if you’re not actually measuring its effect. Once you’ve got your traffic forked, how do you tell if your new service is actually working? How will you measure its performance under load?The easiest way is to monitor the load on the new service as the fraction of dark launch traffic ramps up. In effect, it’s a very realistic load test, using live traffic rather than canned traffic. Once you’re at 100% dark launch and have run over a typical load cycle — generally, at least one day — you can be reasonably confident that your server won’t actually fall over when the launch goes live.
If you’re planning a publicity push for your service, you should try to maximize the additional load you put on your service and adjust your launch estimate based on a conservative multiplier. For example, say that you can generate 3 dark launch queries for every live user query without affecting end-user latency. That lets you test how your dark-launched service handles three times the peak traffic. Do note, however, that increasing traffic flow through the system by this amount carries operational risks. There is a danger that your “dark” launch suddenly generates a lot of “light” — specifically, a flickering yellow-orange light which comes from the fire currently burning down your service. If you’re not already talking to your SREs, you need to open a channel to them right now to tell them what you’re planning.
Different services have different peak times. A service that serves worldwide traffic and directly faces users will often peak Monday through Thursday in the morning in the US as this is where users normally dominate traffic. By contrast, a service like a photo upload receiver is likely to peak on weekends when users take more photos, and will get huge spikes on major holidays like New Years. Your dark launch should try to cover the heaviest live traffic that it’s reasonable to wait for.
We believe that you should always measure service load during a dark launch as it is very representative data for your service and requires near-zero effort to do.
Load is not the only thing you should be looking at, however, as the following measurements should also be considered.
Logging needs
The point where incoming requests are forked to the original and new backends — generally, the application front end — is typically also the point where the responses come back. This is, therefore, a great place to record the responses for later analysis. The new backend results aren’t being returned to the user, so they’re not normally visible directly in monitoring at the application frontend. Instead, the application will want to log these responses internally.Typically the application will want to log response code (e.g. 20x/40x/50x), latency of the query to the backend, and perhaps the response size, too. It should log this information for both the old and new backends so that the analysis can be a proper comparison. For instance, if the old backend is returning a 40x response for a given request, the new backend should be expected to return the same response, and the logs should enable developers to make this comparison easily and spot discrepancies.
We also strongly recommend that responses from original and new services are logged and compared throughout dark launches. This tells you whether your new service is behaving as you expect with real traffic. If your logging volume is very high, and you choose to use sampling to reduce the impact on performance and cost, make sure that you account in some way for the undetected errors in your traffic that were not included in the logs sample.
Timeouts as a protection
It’s quite possible that the new backend is slower than the original — for some or all traffic. (It may also be quicker, of course, but that’s less interesting.) This slowness can be problematic if the application or client is waiting for both original and new backends to return a response before returning to the client.The usual approaches are either to make the new backend call asynchronous, or to enforce an appropriately short timeout for the new backend call after which the request is dropped and a timeout logged. The asynchronous approach is preferred, since the latter can negatively impact average and percentile latency for live traffic.
You must set an appropriate timeout for calls to your new service, and you should also make those calls asynchronous from the main user path, as this minimizes the effect of the dark launch on live traffic.
Diffing: What’s changed, and does it matter?
Dark launches where the responses from the old and new services can be explicitly diff’ed produce the most confidence in a new service. This is often not possible with mutations, because you can’t sensibly apply the same mutation twice in parallel; it’s a recipe for conflicts and confusion.Diffing is nearly the perfect way to ensure that your new backend is drop-in compatible with the original. At Google, it’s generally done at the level of protocol buffer fields. There may be fields where it’s acceptable to tolerate differences, e.g. ordering changes in lists. There’s a trade-off between the additional development work required for a precise meaningful comparison and the reduced launch risk this comparison brings. Alternatively, if you expect a small number of responses to differ, you might give your new service a “diff error budget” within which it must fit before being ready to launch for real.
You should explicitly diff original and new results, particularly those with complex contents, as this can give you confidence that the new service is a drop-in replacement for the old one. In the case of complex responses, we strongly recommend either setting a diff “error budget” (accept up to 1% of responses differing, for instance) or excluding low-information, hard-to-diff fields from comparison.
This is all well and good, but what’s the best way to do this diffing? While you can do the diffing inline in your service, export some stats, and log diffs, this isn't always the best option. It may be better to offload diffing and reporting out of the service that issues the dark launch requests.
Within Google, we have a number of diffing services. Some run batch comparisons, some process data in live streams, others provide a UI for viewing diffs in live traffic. For your own service, work out what you need from your diffing and implement something appropriate.
Going live
In theory, once you’ve dark-launched 100% of your traffic to the new service, making it go “live” is almost trivial. At the point where the traffic is forked to the original and new service, you’ll return the new service response instead of the original service response. If you have an enforced timeout on the new service, you’ll change that to be a timeout on the old service. Job done! Now you can disable monitoring of your original service, turn it off, reclaim its compute resources, and delete it from your source code repository. (A team meal celebrating the turn-down is optional, but strongly recommended.) Every service running in production is a tax on support and reliability, and reducing the service count by turning off a service is at least as important as adding a new service.Unfortunately, life is seldom that simple. (As id Software’s John Cash once noted, “I want to move to ‘theory,’ everything works there.”) At the very least, you’ll need to keep your old service running and receiving traffic for several weeks in case you run across a bug in the new service. If things start to break in your new service, your reflexive action should be to make the original service the definitive request handler because you know it works. Then you can debug the problem with your new service under less time pressure.
The process of switching services may also be more complex than we’ve suggested above. In our next blog post, we’ll dig into some of the plumbing issues that increase the transition complexity and risk.




