Using deemed SLIs to measure customer reliability
Adrian Hilton
Customer Reliability Engineer, SRE
Do you own and operate a software service? If so, is your service a ”platform”? In other words, does it run and manage applications of a wide range of users and/or companies? There are both simple and complex types of platforms, all of which serve customers. One example could be Google Cloud, which provides, among other things, relatively low-level infrastructure for starting and running VM images. A higher-level example of a platform might be a blogging service that allows any customer to create and contribute to a blog, design and sell merchandise featuring pithy blog quotes, and allow readers to send tips to the blog author.
If you do run a platform, it’s going to break sooner or later. Some breakages are large and easy to understand, such as no one being able to reach websites hosted on your platform while your company’s failure is frequently mentioned on social media. However, other kinds of breakage may be less obvious to you—but not to your customers. What if you’ve accidentally dropped all inbound network traffic from Kansas, for example?
At Google Cloud, we follow SRE principles to ensure reliability for our systems and also customers partnered with the Customer Reliability Engineering (CRE) team. A core SRE operating principle is the use of service-level indicators (SLIs) to detect when your users start having a bad time. In this blog post, we’ll look at how to measure your platform customers’ approximate reliability using approximate SLIs, which we term “deemed SLIs.” We use these to detect low-level outages and drive the operational response.
Why use deemed SLIs?
CRE founder Dave Rensin noted in his SRECon 2017 talk, Reliability When Everything Is A Platform, that as a platform operator, your monitoring doesn’t decide your reliability—your customers do! The best way to get direct visibility into your customers’ reliability experience is to get them to define their own SLIs, and share those signals directly with you. That level of transparency is wonderful, but it requires active and ongoing participation from your customers. What if your customers can’t currently prioritize the time to do this?
As a platform provider, you might use any number of internal monitoring metrics related to what’s happening with customer traffic. For instance, say you’re providing an API to a storage service:
You may be measuring the total number of queries and number of successful responses as cumulative numeric metrics, grouped by each API function.
You may also be recording the 95th percentile response latency with the same grouping, and get a good idea of how your service is doing overall by looking at the ratio of successful queries and the response latency values. If your success ratio suddenly drops from its normal value of 99% to 75%, you likely have many customers experiencing errors. Similarly, if the 95th percentile latency rises from 600ms to 1400ms, your customers are waiting much longer than normal for responses.
The key insight to motivate the use of “deemed SLIs” is that metrics aggregated across all customers will miss edge cases—and your top customers are very likely to depend on those edge cases. Your top customers need to know about outages as soon as, or even before, they happen. Therefore, you most likely want to know when any of your top customers is likely to experience a problem, even if most of your customers are fine.
Suppose FooCorp, one of your biggest customers, uses your storage service API to store virtual machine images:
- They build and write three different images every 15 minutes.
- The VM images are much larger than most blobs in your service.
- Every time one of their 10,000 virtual machines is restarted, it reads an image from the API.
- Therefore, their traffic rate is one write per five minutes and assuming a daily VM restart, one read per 8.6 seconds.
- Your overall API traffic rate is one write per second and 100 reads per second.
Let’s say you roll out to your service a change that has a bug, causing very large image reads and writes, which are likely to time out and not complete. You initially don’t see any noticeable effect on your API’s overall success rate and think your platform is running just fine. FooCorp, however, is furious. Wouldn’t you like to know what just happened?
Implementation of deemed SLIs
The first and foremost step is to see key metrics at the granularity of a single customer. This requires careful assessment and trade-offs.
For our storage API, assuming we were originally storing two cumulative measures (success, total) and one gauge (latency) at one-minute intervals, we can measure and store three data points per minute with no problem at all. However, if we have 20,000 customers, then storing 60,000 points per minute is a very different problem. Therefore, we need to be careful in the selection of metrics for which we provide the per-customer breakdown. In some cases, it may be sensible to have per-customer breakdowns only for a subset of customers, such as those contracting for a certain level of paid support.
Next, identify your top customers. “Top” could mean:
invests the most money on your platform;
is expected to invest the most money on your platform in the next two years;
is strategic from the point of view of partnerships or publicity; or even
raises the most support cases and hence causes the greatest operational load on your team.
As we mentioned, customers use your platform in different ways and as a result, have different expectations of it. To find out what your customer might regard as an outage, you need to understand in some depth what their workload really does. In some cases, the customer’s clients might automatically read data from your API every 30 minutes, and update their state if new information is available. However, even if the API is completely broken for an hour, very few customers might actually notice.
To determine your deemed SLIs, consider applying your understanding of the customer’s workload from the limited selection of metrics per customer. Think about your observation of the volatility of the metrics over time, and if possible, observation of the metrics during a known customer outage. From this, pick the subset of metrics which you think best represent customer happiness. Identify the normal ranges of those metrics, and aggregate them into a dashboard view for that customer.
This is why we call these metrics “deemed SLIs”—you deem them to be representative of your particular customer’s happiness, in the absence of better information.
Some of the metrics you look at for your deemed SLIs of the storage service might include:
Overall API success rate and latency
Read and write success rate for large objects (i.e., FooCorp’s main use case)
Read latency for objects below a certain size (i.e., excluding large image read bursts so there’s a clear view of API performance for its more common read use case).
The main challenges are:
Lack of technical transparency into the customer’s key considerations. For instance, if you only provide TCP load balancing to your customer, you can’t observe HTTP response codes.
Lack of organizational transparency—you don’t have enough understanding of the customer’s workload to be able to identify what SLIs are meaningful to them.
Missing per-customer metrics. You might find that you need to know whether an API call is made internally or externally because the latter is the key representative of availability. However, this distinction isn’t captured in the existing metrics.
It’s important to remember that we don’t expect these metrics to be perfect at first— these metrics are often quite inconsistent with the customer’s experience in the beginning. So how do we fix this? Simple—we iterate.
Iteration when choosing deemed SLIs
Now sit back and wait for a significant outage of your platform. There’s a good chance that you won’t have to wait too long, particularly if you deploy configuration changes or binary releases often.
When your outage happens:
- Do an initial impact analysis. Look at each of your deemed SLIs, see if they indicate an outage for that customer, and feed that information to your platform leadership.
- Feed quantitative data into the postmortem being written for the incident. For example, “Top customer X first showed impact at 10:30 EST, reached a maximum of 30% outage at 10:50 EST, and had effectively recovered by 11:10 EST.”
- Reach out to those customers via your account management teams, to discover what their actual impact was.
Here’s a quick reference table for what you need to do for each customer:
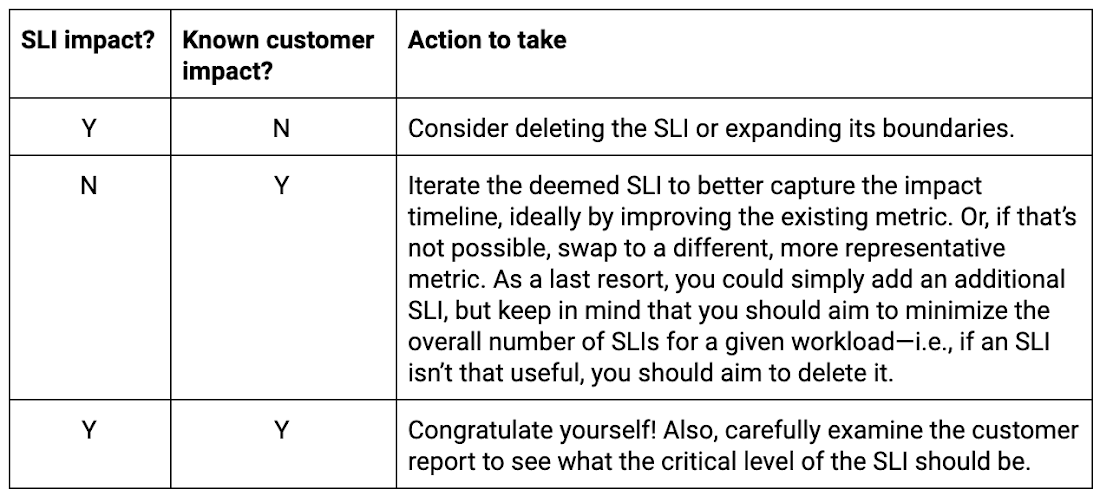
As you gain confidence in some of the deemed SLIs, you may start to set alerts for your platform’s on-call engineers based on those SLIs going out of bounds. For each such alert, see whether it represents a material customer outage, and adjust the bounds accordingly.
It’s important to note that customers can also shoot themselves in the foot and cause SLIs to go out of bounds. For example, they might cause themselves a high error rate in the API by providing an out-of-date decryption key for the blob. In this case, it’s a real outage, and your on-caller might want to know about it. There’s nothing for the on-caller to do, however—the customer has to fix it themselves. At a higher level, your product team may also be interested in these signals because there may be opportunities to design the product to guard against customers making such mistakes—or at least advise the customer when they are about to do so.
If a top customer has too many “it was us, not the platform” alerts, that’s a signal to turn off the alerts until things improve. This may also indicate that your engineers should collaborate with the customer to improve their reliability on your platform.
When your on-call engineer gets deemed SLI alerts from multiple customers, on the other hand, they can have a high confidence that the proximate cause is likely on the platform side.
Getting started with your own deemed SLIs
In Google Cloud, some of these metrics are exposed to customers directly through project-related, Transparent SLIs.
If you run a platform, you need to know what your customers are experiencing.
Knowing that a top customer has started having a problem before they phone your support hotline shrinks incident detection by many minutes, reduces the overall impact of the outage, and improves relationships with that customer.
Knowing that several top customers have started to have problems can even be used to signal that a recent deployment should presumptively be rolled back, just in case.
Knowing roughly how many customers are affected by an outage is a very helpful signal for incident triage—is this outage minor, significant, or huge?
Whatever your business, you know who your most important customers are. This week, go and look at the monitoring of your top three customers. Identify a “deemed SLI” for each of them, measure it in your monitoring system, and set up an automated alert for when those SLIs go squirrelly. You can tune your SLI selection and alert thresholds over the next few weeks, but right now, you are in tune with your top three customers’ experience on your platform. Isn’t that great?
Learn more about SLIs and other SRE practices from previous blog posts and the online Site Reliability Workbook.
Thanks to additional contributions from Anna Emmerson, Matt Brown, Christine Cignoli and Jessie Yang.




