Combining Thomson Reuters data with Google BigQuery and Google Cloud Pub/Sub API
Reza Rokni
Dataflow Product Manager
We recently had the very exciting opportunity to work in partnership with Thomson Reuters to demonstrate to Citibank's Global Banking and Markets department the benefits of combining Google's core data technologies with Thomson Reuters financial market content. In a proof-of-concept experiment, our task was to show how easy it would be for Citibank to use Google BigQuery and Google Cloud Pub/Sub to analyze and consume roughly 1,000 financial instruments' worth of historic and near-real time tick data from Thomson Reuters.
Overview
The work was done in collaboration with Sean Micklethwaite, lead developer from Citibank, and Sebastian Fuchs, solution specialist from Thomson Reuters.BigQuery allowed us to store tick-by-tick market data efficiently in per day partitioned tables. Those tables can be shared with authenticated users or groups - SQL requests are made directly to the tables, there is no need to create separate output files for batched transfers. Access is granted by using the standard Google access tools (IAM) and could be extended using our own access-control mechanisms. BigQuery also supports streaming ingestion of events, allowing customers to get intra-day snaps close to real time. We started to use BigQuery without having the need to do excessive capacity planning upfront. It simply grows as needed, both from a content provisioning as well as from a number of user queries point of view.” — Sebastian Fuchs
We required access to a set of cross-asset market data from Thomson Reuters to feed our internal analytics system. This meant integrating with several Thomson Reuters APIs and storing tick history for fast access, a daunting task for our small team. We wanted an API that we could query for historic data on-demand, without the need to maintain our own data warehouse, and all the cost and operational overhead that entails. Additionally, we required real-time updates to market data with human-level latency. With Google Cloud, we get access to all the data we need through a single platform. BigQuery takes care of our historic tick data needs, and has the power to process raw ticks at high frequency over large ranges. Cloud Pub/Sub takes care of our real-time data requirements, and we receive all data in a consistent format.” — Sean Micklethwaite
Implementation
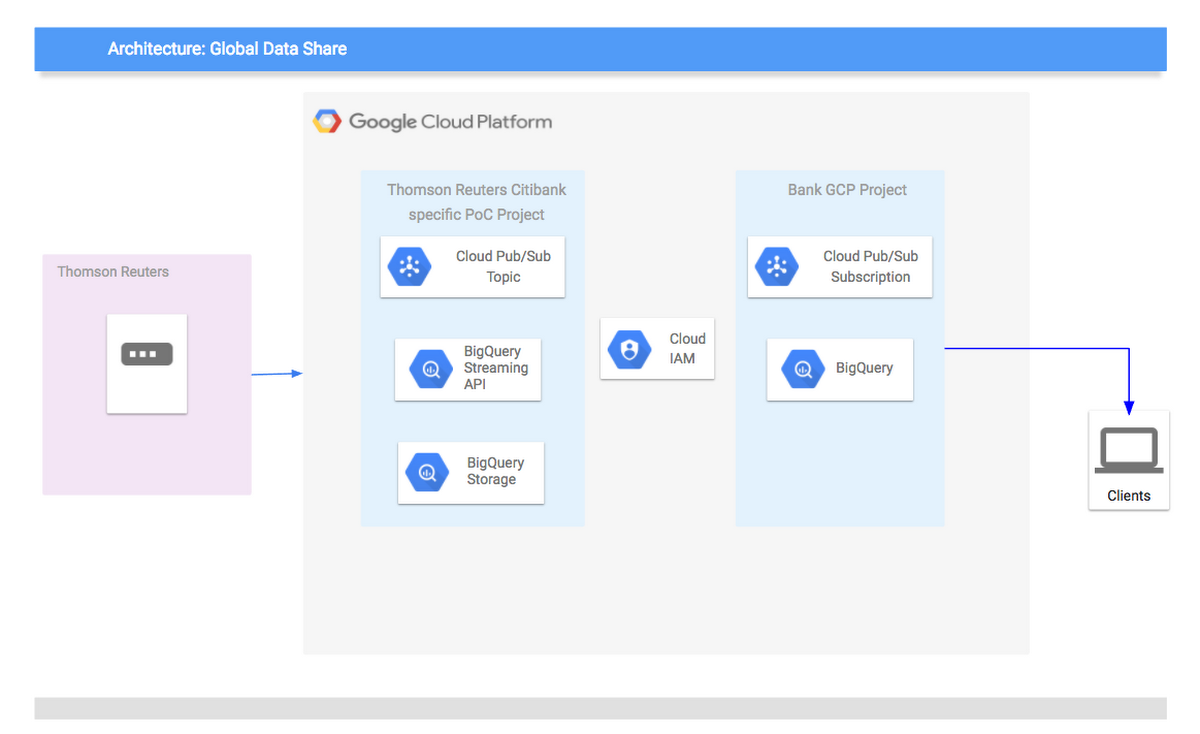
BigQuery and Cloud Pub/Sub were chosen as the tools to deliver the solution, as their technical characteristics are an especially good match for the requirements outlined. BigQuery’s relevant features include:
- BigQuery uses Capacitor, BigQuery’s next-generation columnar storage format, to store data in Colossus, Google’s latest-generation distributed filesystem. Colossus is coupled with Google’s Jupiter network, which can deliver 1PB/sec of total bisection bandwidth. This is the infrastructure that delivers services like Gmail and YouTube, and it also allows BigQuery to separate its storage layer from the processing layer while retaining the performance characteristics needed by users. An important aspect of this infrastructure is that sharing of data across companies becomes easy; there is no need to physically move data nor is there a need for the user to build in multi-tenancy and resource sharing at the database level. Thomson Reuters can load data into its project and simply provide access to the consumers, who can run their own queries from within their own projects.
- BigQuery integration with GCP Identity And Access Management ensures granular control access to the datasets.
- The BigQuery streaming API allows data to be pushed directly into BigQuery without the need for batch / micro batching. The data is always immediately available for query and up to date.
- BigQuery exposes Google's Dremel technology for customers to provide a fully-managed environment that will allocate resources to a user query every time a user makes a request. This means there's no installation, maintenance or forward planning needed to size out clusters — allowing Thomson Reuters and Citibank to just get on with the business problem.
We created BigQuery tables based on our existing data structure design derived from our TickHistory product, which allowed us to backfill data easily. This was then extended by intraday data updates — each table does have day partitions and we make sure the right data goes into the right partitions. This creates a seamless view of data, no matter which data source it originally was coming from. The dataset structure is following the same principles — based on permission entities, which we do follow with our market data products. This allows us to control very granular access to different Citibank applications.” — Sebastian Fuchs
We access BigQuery, via the Google Cloud Node.JS client library, to populate our analytics dashboards with historic data the first time our users request it. Additionally, we process the raw ticks in BigQuery using SQL to generate candlesticks of arbitrary size. With this model, we only pay for queries on the data we need, when we need it, and network overhead is relatively small because we’re doing aggregation at-source. Thanks to daily partitioned tables, our costs are kept low.” — Sean Micklethwaite
Cloud Pub/Sub relevant features include:
- Cloud Pub/Sub is a fully-managed service with no setup or configuration required outside of the administration of the topics and subscriptions. Setting up a topic to push messages to and a subscription to pull from those messages can be completed in minutes.
- Integration with GCP Identity And Access Management ensures fine-grain control access to the topics.
- Data is retained for up to 7 days or until a consumer has acknowledged receipt, ensuring at-least-once delivery guarantees.
- Each topic can accommodate millions of updates per second, so there's no need to plan for any market shocks. There's no need to segment or partition the load, nor is there a requirement for warming the system up.
- Many subscriptions can be attached to a single topic, allowing for multiple environments to draw from the same data.



