Cloud poetry: training and hyperparameter tuning custom text models on Cloud ML Engine
Lak Lakshmanan
Director, Analytics & AI Solutions
Lukasz Kaiser
Research Scientist, Google Brain
Machine learning models for interpreting and processing natural language have made tremendous advances in recent years thanks to deep learning methods. Recurrent models continue to be a common choice for textual data, but newer models based on fully convolutional architectures like ByteNet, and even more recently models based on attention like the Transformer have yielded impressive results. All this complexity—added to the fast pace of research—have made it hard to keep current and apply the latest methods to your own problems.
This is why the open-sourcing of Tensor2Tensor (T2T), a library of best-in-class machine learning models by the Google Brain team, was so exciting—you now have at your disposal a standard interface that ties together all the pieces needed in a deep learning system: datasets, model architectures, optimizers, and hyperparameters in a coherent and standardized way that enables you to try many models on the same dataset, or apply the same model to many datasets.
Now that we’ve established that the software tools exist, how should you go about setting up a training environment to launch many experiments? In this blog post, we provide a tutorial on how to use T2T and Google Cloud ML Engine, Google Cloud Platform’s fully managed ML service, to train a text-to-text model on your own data. With T2T and ML Engine, you won’t have to manage any infrastructure for training or hyperparameter tuning. You will be able to train a sophisticated, custom natural language model from just a Jupyter notebook.
Throughout this blog post, we will examine code blocks from this Jupyter notebook—we strongly encourage you to fire up Cloud Datalab (you don’t need an instance with a GPU because we’ll submit jobs to Cloud ML Engine) and try out the notebook on Google Cloud Platform.
A model to write poetry
Let’s say we want to train a machine learning model to complete poems. Given one line of verse, the model should generate the next line. This is a hard problem—poetry is a sophisticated form of composition and wordplay. It seems harder than translation because there is no one-to-one relationship between the input (first line of a poem) and the output (the second line of the poem). It is somewhat similar to a model that provides answers to questions, except that we’re asking the model to be a lot more creative.Creating a dataset
In order to train our model, we’ll need a dataset consisting of poems. The input “feature” will be a line of verse and the output “label” will be the following line of verse. We can create such a dataset by downloading poetry anthologies from Project Gutenberg and doing a little bit of text wrangling:Please see the notebook on GitHub for the full code and context. Because this is a demonstration, we are creating our dataset from just two anthologies: in general, the more data you can train on, the better your model will be.
Having downloaded and wrangled the data, we can create a pair of files where one file will consist of input lines (the first line of poetry in our case), and the second file will consist of the output lines (the following line of poetry):
Thus, given that a poem in the anthology contains these two lines:
spring the sweet spring is the year's pleasant king
then blooms each thing then maids dance in a ring
The input.txt file would contain the first line and the output.txt file would contain the second line.
Defining a Problem
A key concept in the T2T library is that of a Problem, which ties together all the pieces needed to train a machine learning model. It is easiest to inherit from the appropriate base class in the T2T library and then change only the pieces that are different for your model.There are essentially three types of text sequence models:
- Models that use a sequence as an input, but are essentially classifiers or regressors—a spam filter or sentiment identifier are canonical examples of such a model.
- Models that take a single entity as input but produce a text sequence as output—image captioning is an example of such a model, since given an image, the model needs to produce a sequence of words that describes the image.
- Models that take sequences as input and produce sequences as outputs. Language translation, question-answering, and text summarization are all examples of this third type.
The first part of our Problem consists of specifications for the embed part of the embed-encode-attend-predict pipeline. The “embed” step defines how we break up the text and represent them as numbers. We specify 4096 as the approximate vocabulary size, which means that all text will be represented by 4096 numbers, and the prediction step will return one of these values, representing a word. The smaller our vocabulary, the longer the encoded representations are and the more the model has to learn to put small pieces together (for example, in the limit, we would have a vocabulary that was only the size of the alphabet and the model would have to learn to combine characters into words).
Generating data
The final part of the Problem is that we have to define how to generate the actual tf.train.Example files consisting of tokens. This is done in thegenerate_samples method which simply yields a dictionary of input-target pairs:Note that instead of starting from the input and output files that we created earlier, we have started from the raw data and generated the input and output data on demand. Putting such data generation from the raw data directly in the Problem makes this workflow much easier to streamline and deploy. Training a ML model often requires us to split the data into training and evaluation datasets. This is also quite easy to achieve within Problem:
Once the Problem has been defined, we will put it into a Python package (we’ve called it poetry.trainer: note the t2t_usr_dir below) and then invoke a utility called t2t-datagen that is bundled with T2T:
This generates the actual training and evaluation files that will be used for training the language model.
Customizing the model
Because our Problem inherited Text2TextProblem and overrode only the embed step, we can reuse its encode-attend-predict pipeline with no change. The default settings, though, are meant for datasets of 400m records and won’t work well for our much smaller (22k records) dataset. So let’s customize the model to make it smaller (fewer layers, fewer nodes) and add more regularization via dropout (regularization helps reduce overfitting, something that’s of greater concern in smaller datasets). To do so, we register a set of hyperparameters:Training locally
Now, we’re ready to train the model. We could train the model locally, which is what you would do if you were running on-prem, on a Cloud Datalab instance with a GPU, or on a Compute Engine instance with an attached GPU or Cloud TPU:Here, though, we are running on a n1-standard virtual machine (the default machine when you create Datalab without specifying a machine type or adding a GPU). So, we’ll send the job off to Cloud ML Engine. There are three reasons we might want to use Cloud ML Engine, rather than the bare-metal that Google Compute Engine or Google Kubernetes Engine provides:
- As a fully managed service, Cloud ML Engine can acquire expensive GPU or TPU resources for just the duration of the job.
- Integration with Google Cloud Platform’s logging and monitoring capabilities are better. For example, details about the job run will be available in Stackdriver even after the job is finished.
- Hyperparameter tuning is available only on Cloud ML Engine.
Training on Cloud ML Engine
To send the t2t-trainer job to Cloud ML Engine, all that we have to do is to add --cloud_mlengine to the parameters of t2t-trainer:Note that we specify the number of GPUs; currently, we can specify 1, 4 or 8. As the list of accelerators supported by Cloud ML Engine expands, expect to see more options here.
Incidentally, how does this magic work? Normally, you submit jobs to Cloud ML Engine using gcloud as in:
gcloud ml-engine jobs submit training $JOBNAME …
Here, though, T2T is taking advantage of the Python API mentioned in the Cloud ML Engine documentation (switch to the Python view) to directly hit the REST endpoint. If you write trainable machine learning models, this is a neat trick: just running your module can submit it for training!
When we ran the training and monitored it on TensorBoard, we noticed clear signs of overfitting:
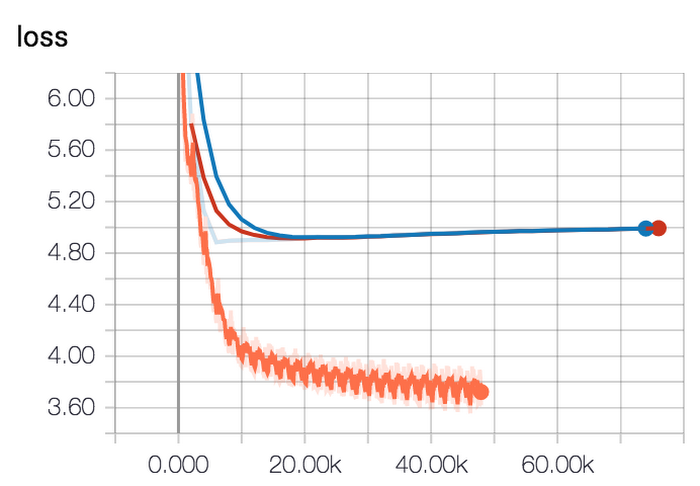
The training loss (orange curve) kept decreasing but the evaluation loss (blue curve) started to go in the wrong direction (slight increase).
Our initial choice of hyperparameters was a wild guess. So, our next step is to tune those hyperparameters to hopefully obtain better accuracy.
Hyperparameter tuning
To carry out hyperparameter tuning, we register a hyperparameter range:Here, we would like to tune four parameters: the learning rate, the number of hidden layers, the number of nodes in each of the hidden layers, and the dropout probability for the attention mechanism.
Having defined these ranges, we add a few more flags to t2t-trainer to submit a hyperparameter tuning job to Cloud ML Engine:
We have specified the hyperparameter ranges that we registered and clarify that we wish to maximize the accuracy per sequence. There are other metrics, such as perplexity that are reported by T2T, but accuracy per sequence is a better fit for this problem.
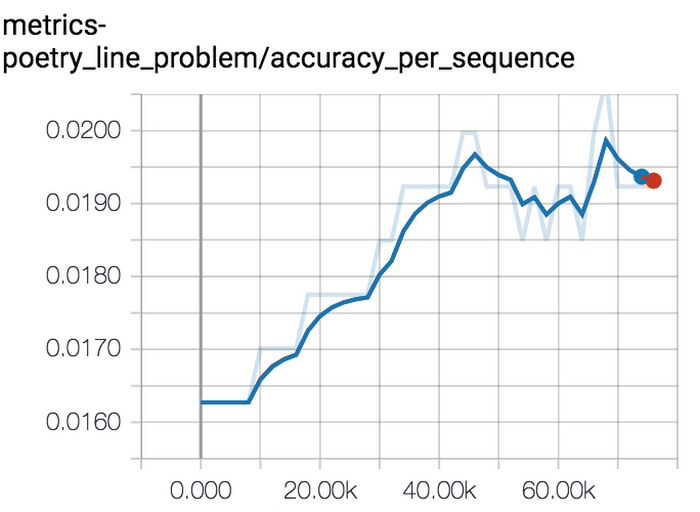
And that’s it! Launch it off, and fifteen hours later (a lot fewer on a TPU, but we are using GPUs), we get a set of hyperparameters that results in a 40% improvement in accuracy. The numbers are great, but what do the generated poems look like?
Decoding
We trained the model on English anthologies consisting primarily of American poetry. Let’s see what the model does when faced with Rumi’s couplets. We will provide the model a line from Rumi and see how it completes the couplet. Is the generated sequence poetic? Does it make sense?To invoke our model, we run a tool called t2t-decoder pointing it at the trial that gave us the highest accuracy and ask it to decode a file consisting of odd-numbered lines from Rumi:
When predicting using a sequence-to-sequence model, one does not simply pick the most likely output as we would in a classification model. If we did that, we would get a sequence that consists purely of the most frequent words. As you would expect, t2t-decoder implements a best-in-class technique to get around this problem, by letting you do a beam search probabilistically. In addition to specifying the beam search parameters, we also inform the decoder that the model being used has four layers of 512 nodes each—these were the hyperparameters corresponding to the trial which had the highest accuracy per sequence.
What does the generated poetry look like? I’m providing the first line of Rumi’s verse, how the model completes it, and what Rumi’s next line actually was:
The couplets as completed are quite impressive considering:
- We trained the model on American poetry, so feeding it Rumi is a bit out of left field.
- We trained our model on just 22,000 lines of poetry, an extremely small data set.
- Rumi can maintain a thread running through his lines while the AI (since it was fed only a single line) cannot.
Deploying the model
Once we have the trained TensorFlow model, we need to export it, so that we can deploy it on Cloud ML Engine or on Kubeflow:Once the model was deployed, we set up a front-end for it: an App Engine Flex application (see GitHub for details) and made it publicly accessible at https://mlpoetry-dot-cloud-training-demos.appspot.com/. Type in the first line of your poem, and the prediction model will complete it for you!
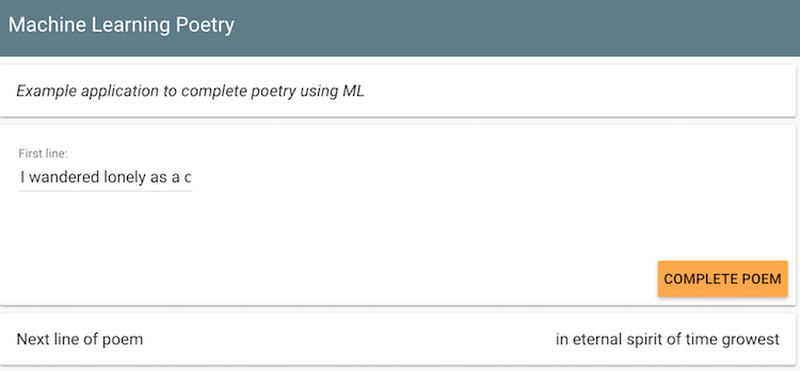
We’ll leave the model running till mid-March. Tweet any clever ML-generated poetry that the model concocts at @googlecloud and @lak_gcp with the hashtag #mlpoetry! Happy coding.
Next steps:
- Try out the ML Poetry service by visiting https://mlpoetry-dot-cloud-training-demos.appspot.com/ and typing in a line of poetry.
- Launch Cloud Datalab and try out the steps in this Jupyter notebook to carry out the machine learning model training and hyperparameter tuning described in this blog post.
- Take this Coursera course or try out this Qwiklab to learn more about machine learning on GCP



