BigQuery lazy data loading: SQL data languages (DDL and DML), partitions, and half a trillion Wikipedia pageviews
Felipe Hoffa
Developer Advocate, Google Cloud Platform
What's the simplest way to analyze a 4 terabyte dataset of Wikipedia pageviews made publicly available by the Wikimedia Foundation? (We see this dataset as a public treasure: it’s not perfectly structured, but BigQuery proved an excellent tool to extract the insights we present below.)
In this post, I'll show you how to take on this challenge using only BigQuery, while showcasing a few of its newest features. As a lazy programmer, these new features help reduce the amount of work I have to do!
Step 0: Download all the data
Our first step is to transfer all the pageview records from an arbitrary web server to Google Cloud Storage. I ran this transfer with a Cloud Dataflow script written in Python, but we'll leave the discussion of this and other methods for a later post.For now, all we need to know is:
Step 1: Feeling lazy? Just read from Google Cloud Storage
BigQuery can easily analyze files living in Cloud Storage. We don't even need to decompress them, as these specific files are natively supported by BigQuery (gzip). To tell BigQuery to read these files straight from Cloud Storage, we can create a federated table with the following script:Notes on the above:
- As I'm feeling lazy, I didn't even try to parse each line into columns. I can do that later within a query. This is an easy way to deal with harder-to-parse files, like malformed JSON or CSV files.
- To avoid BigQuery parsing this file into columns, I specified the weirdest ASCII character I could find as the field delimiter, in this case: u'\u00ff'
- I could have completed this step with the web UI instead of Python (that would have been a lazier approach), but currently the web UI doesn't allow me to specify a weird character as a field delimiter.
- Some lines appear to be corrupted in the original source. We'll ignore them by allowing 10000000 errors, as specified by setting
max_bad_records.
Once I've set up my files in Cloud Storage as a federated table, I can start playing with it. Let's see:
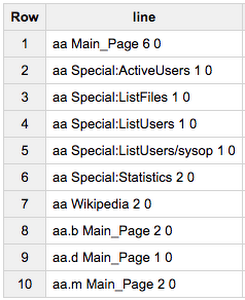
Note: BigQuery experts know that SELECT * LIMIT 10 is usually a bad idea with BigQuery, because you'll get billed for the full size of the table. But you won’t encounter this issue while running queries on federated tables! BigQuery stops opening files as soon as it has all the data it needs to answer a query, and in this case it charged us 0 bytes to show us the first 10 lines of one these files.
Which file did it open? Well, there's a pseudo column for this:
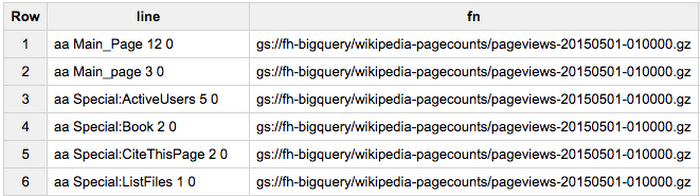
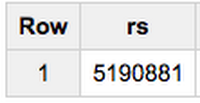
Happily, we can see what files these lines are coming from. We can use this pseudo column when querying too. Let's count the number of rows in a file:
Query complete (21.7s elapsed, 152 MB processed)
Notes on the above:
- We can see this file (one hour of data) encompasses more than 5 million rows, and 152 MB of data.
- Even though our table definition encompasses terabytes of data, BigQuery was smart enough to only open and charge us for the files we filtered for.
- Warning: Don't run the same query without a file filter! You could end up with a bill for terabytes of data, instead of a mere 152 MB. Remember to set up your cost controls to avoid these charges.
What if we want to parse each line in a clever way, and save the effort of writing these queries to the rest of our team? We can define a view:
Notes on the above:
- BigQuery now supports DDL. We can create a view within a query!
- I can use the
_FILE_NAMEmeta column as data for my own columns. - The
WHEREstatements in this view take care of badly defined rows in the source files.

Query complete (7.8s elapsed, 0 B processed)
Notes on the above:
- We are now parsing the underlying files on the fly, and now we can work with well-typed columns.
- Since this view is loading a federated table from Cloud Storage, the same rules apply to only opening as many tables as needed.

75.8s elapsed, 159 MB processed
Notes on the above:
- This file with one hour of pageviews has more than 5 million rows, representing more than18 million views.
- BigQuery was smart enough to pass our column filters down to Cloud Storage. Only one file was loaded and analyzed.
- Warning: Don't run the same query without a file filter! Instead of 159 MB, you could end up being charged for terabytes of data. Remember to set up your cost controls to avoid these pitfalls.
545690866734 24795 153479054298
Query complete (1540.0s elapsed, 4.24 TB processed)
Step 2: Make BigQuery shine by lazily materializing this view
So far we have been able to read and analyze compressed files straight from Cloud Storage, plus a practical view to simplify our queries, but BigQuery really shines once data is loaded into it. Can we do this lazily?2.1: Create a partitioned destination table with DDL
Some notes on the above:
- BigQuery now supports DDL and partitioned tables by an arbitrary timestamp column!
- With the previous query we created a partitioned table on an arbitrary column.
- I chose to create yearly tables, to avoid running into the maximum limit on the number of supported partitions.
- Using
require_partition_filter, we are forcing users of this table to always specify a date range when querying. This filter requirement can be a great cost saver when you use partitions.
1082.2s elapsed, 1.46 TB processed
Some notes on the above:
- BigQuery now supports DML, and loading data from a view into a table just by using SQL.
- This operation took more than half an hour, but it seems fair given that we moved more than 1 terabyte of data from compressed files into a native BigQuery table.
- Usually loading data into BigQuery is free, but in this case we were charged the cost of the query over the view.
WHERE EXTRACT(YEAR FROM datehour)=2016allowed this query to only go over the 2016 files. BigQuery was smart about it.AND datehour NOT IN (...)makes sure that we load new files into this table, but only if we haven't loaded these files already.WHERE datehour > '2000-01-01'doesn't do much - but as we asked BigQuery to force us to add a date filter when querying this partitioned table, this filter does it.
Step 3: Stay curious
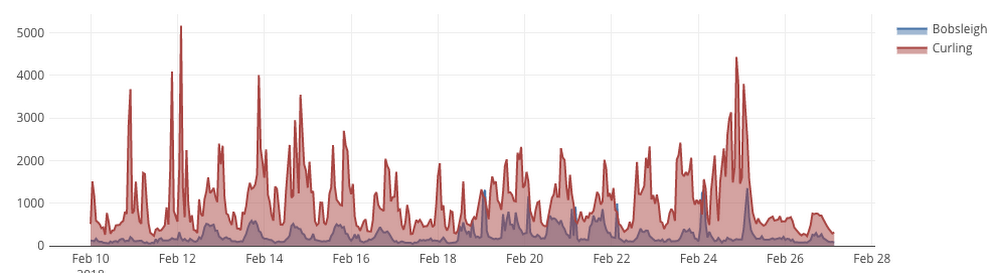
I'm making the partitioned table public, so that now you can write queries over the latest and historic Wikipedia pageviews. For example what's the number of views of Bobsleigh versus Curling? And pageviews from desktop clients versus mobile ones? Check out the results in this query:23.2s elapsed, 109 GB processed
22.2s elapsed, 110 GB processed
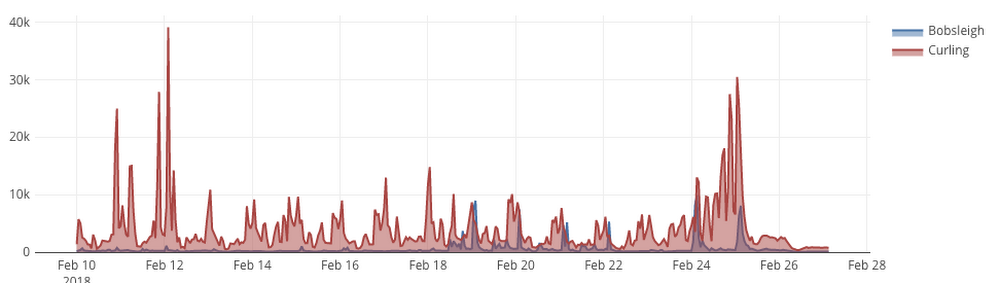
What's the difference between these 2 queries? Turns out people used mobile browsers ~10x over desktop ones. Can we optimize that 109 GB query? We'll try that in a future post.
Remember to set up your cost controls to avoid surprises as you experiment with your own queries, and also remember that you have 1 terabyte of free queries every month. Find me @felipehoffa for more data stories.



