High availability with Memorystore for Redis Cluster, Part 1: Four nines
Dumanshu Goyal
Software Engineer, Google Cloud Databases
Kyle Meggs
Sr. Product Manager, AI Infrastructure
Memorystore for Redis Cluster is a fully managed, highly scalable low-latency Redis Cluster service that provides high availability and a 99.99% (four nines) SLA. In this blog, we explore how the Memorystore for Redis Cluster architecture helps achieve that 99.99% availability, enhancements made with the Redis Engine and Google-engineered control plane, and the challenges with ensuring high availability for self-managed Redis Cluster deployments.
Defining service availability
Before we jump in, let’s define our terms.
When utilizing Redis Cluster for critical workloads (e.g., caching, leaderboards, analytics, session store, or even for the purpose of staging data with rapid ingestion), the risk tolerance for failures is very low. The risk tolerance can be defined as availability, which is measured as the proportion of Redis Cluster uptime:
Availability = [ uptime / (uptime + downtime) ] x 100%
We can calculate downtime to achieve desired availability using this formula. For example, for a 99.99% availability target, — Memorystore for Redis Cluster’s target — a system can be down for only 4.38 minutes per month. Compare that with other services with 99.9% (three nines) availability target, which allow for 43.8 downtime minutes per month.
Further, when designing or examining services for their availability, it is useful to consider two key metrics:
- Mean time to recovery (MTTR): Total downtime / # of failures. This is the average time taken to detect and recover from a failure.
- Mean time between failures (MTBF): Total uptime / # of failures. This is the average time between failures.
Availability can be also expressed in terms of MTBF and MTTR.
Availability = (MTBF / (MTBF + MTTR)) x 100%
Given an MTBF of 30 days and MTTR of 20 minutes, the allowed downtime for a service is 22 minutes per month, or 99.95% availability (30 days / (30 days + 20 minutes)) * 100%). To achieve 4.38 minutes of downtime for 99.99% availability, one must increase MTBF (e.g., to every 6 months) or decrease MTTR (e.g., to ~4 minutes), or both.
In the next sections, we will examine challenges faced with self-managed Redis deployments and how Memorystore for Redis Cluster ensures high availability by both increasing MTBF and reducing MTTR.
Problem 1: Handling correlated infrastructure failures
A system suffers a correlated failure when multiple independent components fail due to a shared failure domain. A failure domain is a resource (e.g., a Compute Engine VM) or a group of resources (e.g. a Google Cloud zone) that can fail independently without affecting other resources. Google designs zones to minimize the risk of correlated failures caused by physical infrastructure outages such as power, cooling, or networking.
Overlooking failure domains when deploying a Redis Cluster often results in multiple nodes on the same physical server or zone, increasing the risk of data loss and unavailability. This happens often — here are a few common examples:
- The OSS Redis Cluster lacks failure domain awareness. Self-managed Redis users using redis-cli packaged scripts don’t always distribute Redis nodes across failure domains. Additionally, users need to be aware of the trade-offs of the OSS Redis replica migration feature, which improves Redis Cluster availability but doesn’t consider failure domains.
- Google Kubernetes Engine’s (GKE) assignment of pods (Redis nodes) to GKE nodes (VMs) lacks failure-domain awareness by default. Users who deploy OSS Redis to GKE need to provision pod affinity and anti-affinity rules and use topology spread constraints to ensure failure domain awareness. The Redis Cluster provisioning process for GKE relies on redis-cli, which lacks failure domain awareness (see #1 above).
- The scope of the impact of an infrastructure failure on bin-packed architectures is often quite large. Other Redis providers with proprietary architectures use multiple Redis processes on a single VM to reduce internal costs by sharing resources. This approach is risky since a single VM failure can affect many Redis processes.
Problem 1 solution: Automate failover across failure domains
Like they say, failing to plan is planning to fail. When configuring a Redis Cluster for high availability, administrators need to pay special attention to how they configure their failover environments, specifically, ensuring redundancy across failure domains and automating the failover process, using three steps:
Step one: Pre-provision replicas
The first step in addressing infrastructure failures is to automatically fail over to a replica node when the primary node goes down.
We recommend provisioning replicas for each shard in advance. This approach is also adopted by many experienced Redis users. For users interested in achieving high availability, the cost of pre-provisioning replica capacity is justified because:
- It makes Redis Cluster resilient to single node failures within a shard. It allows failover to an existing replica node in seconds if a node fails, avoiding lengthy provisioning times. Without replicas, while waiting to provision replacement capacity, your diminished Redis Cluster can get overloaded, potentially leading to a total loss of availability.
- You don't have to rely on a control-plane system to provision replacement capacity when something breaks. Provisioning replacement capacity is complicated and involves many different services working with one another. Relying on complex processes to quickly finish during times of crisis is risky and increases the likelihood of further issues because of the increased stack-depth.
- You can leverage the read replica to increase read capacity. Read replicas help with not just failovers for high availability but also serve read throughput and reduce the load on the primary node. If the read replica fails, you can either fallback to the primary node for reads until the read replica is repaired or provision additional replicas upfront.
Think of it this way: If you get a flat tire while driving, having a spare tire lets you get back up and running relatively quickly. Without the spare, there is the long MTTR of calling someone and waiting to get your car towed for repairs, or an even higher risk if you don’t have cellular service, and thus can’t call for help.

Memorystore for Redis Cluster makes managing replicas easy. With the click of a button or a simple gcloud command, it provisions the replicas, and then keeps them synced with the primary, readily available for automatic promotion in case the primary node fails. Memorystore for Redis Cluster uses the OSS Redis Cluster failover mechanism to execute primary failovers within tens of seconds of an outage to restore shard availability.
Step two: Place Redis shards across failure domains
The second step in addressing correlated failures is to ensure placement of the Redis primary and replica nodes across failure domains.
Automated failovers with replicas in the same failure domain is not a highly available configuration: A single failure can take down both primary and replica nodes of a shard (or multiple shards), negatively impacting application availability.
Here is how Memorystore for Redis Cluster improves the situation for automatic failovers:
- Memorystore for Redis Cluster uses a placement algorithm to automatically distribute the primary and replica nodes of each shard across multiple zones (failure domains) using a regional deployment archetype.
- Even within a single zone, Redis nodes are distributed across multiple physical servers using Compute Engine’s spread placement policy.
The image (b) below shows Memorystore for Redis Cluster distribution of primary and replica nodes in a three-shard Redis cluster across multiple zones.
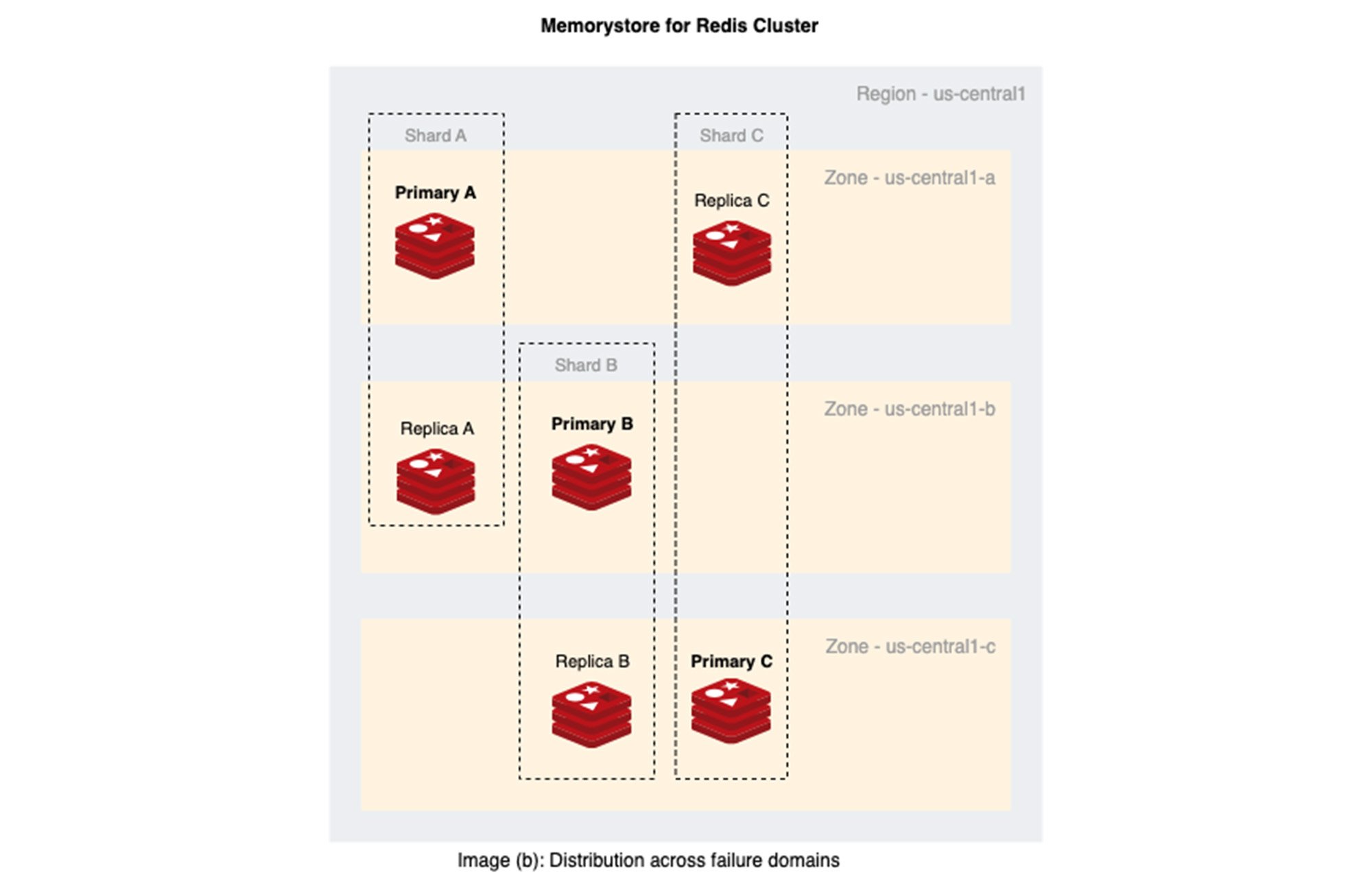
At its core, this is why Memorystore for Redis Cluster can achieve 99.99% (i.e. four nines) uptime, rather than the three nines provided by a VM or zone: The probability of multiple zones failing simultaneously is much lower than a single zone failure, effectively increasing the MTBF.
The image (c) below demonstrates the Memorystore for Redis Cluster automatic failover of a primary during a zone outage.
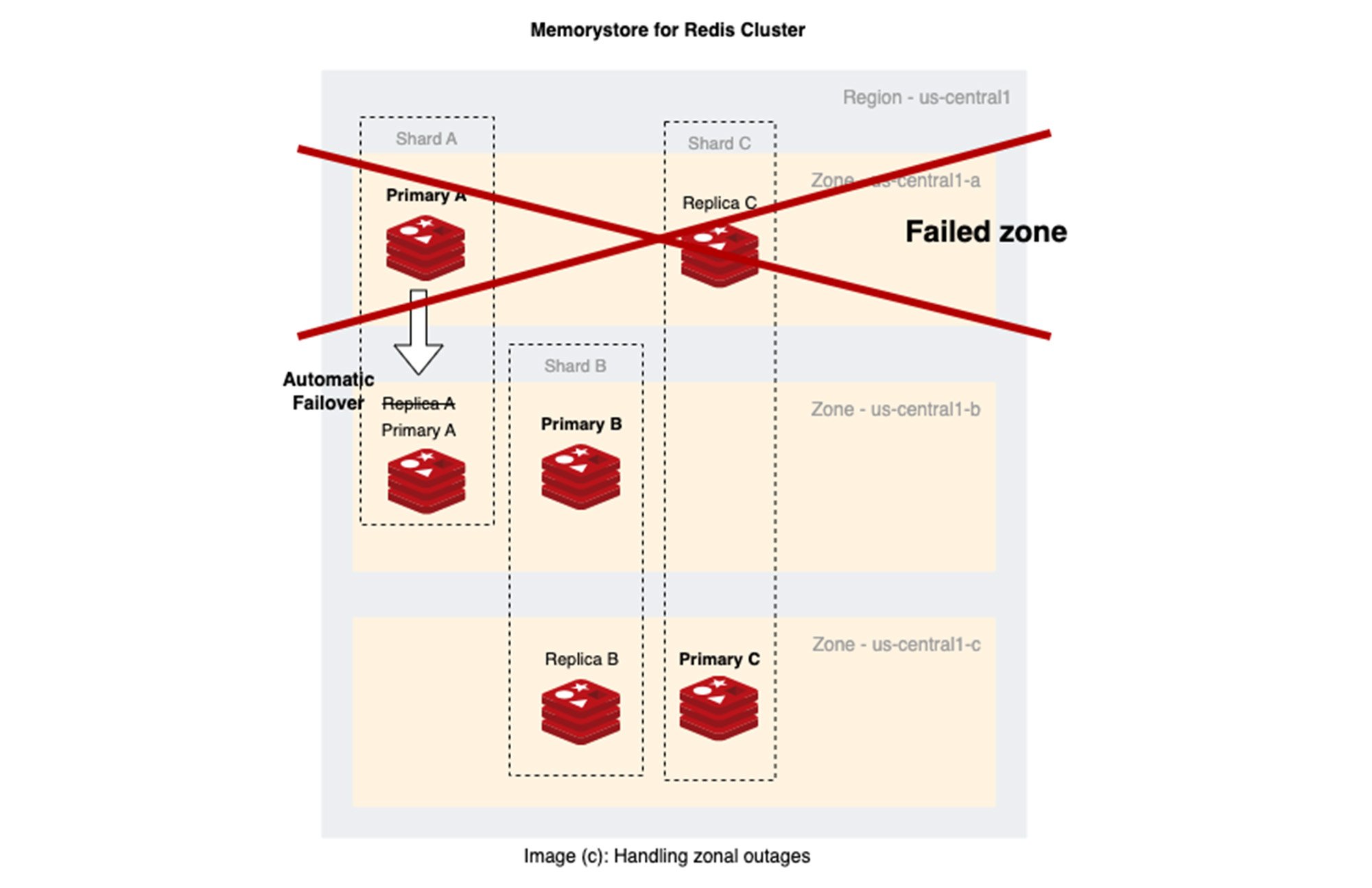
Of course, teams with specialized use cases that can afford longer downtime may want to consider single-zone deployments to avoid cross-zone networking costs and cross-zone latencies. However, be aware of the implicit availability risks of this design.
Step three: Ensure high availability of the failover mechanism
The third and final step in addressing correlated failures is to ensure that the primary failover mechanism works during a large-scale outage such as a zone going down.
Here’s how OSS Redis Cluster’s failure detection and replica election and promotion works:
- Redis nodes communicate using a "gossip protocol” for health checks.
- If a node is unreachable by the majority of primary nodes, Redis Cluster declares the node to have failed.
- Redis Cluster promotes a replica to the primary role for an impacted shard based on the majority of primaries voting for it.
Memorystore for Redis Cluster uses the OSS Redis Cluster failover mechanism because it eliminates external dependencies, such as a control plane, and relies on the Redis nodes themselves to detect failures and elect primaries, improving overall resilience. The data plane composed of Redis Cluster nodes serves client requests, while the control plane manages Redis. The control plane is complex due to its workflows and state management, making failures more likely. Eliminating reliance on the control plane to handle failovers increases MTBF, as Redis nodes can still serve requests if the control plane is down.
However, automated failovers alone do not ensure high availability. As described above, OSS Redis Cluster needs a majority of primary nodes for failure detection and replica promotion. Without a quorum, failover is impossible across any shard. We’ll go over some problematic scenarios next.
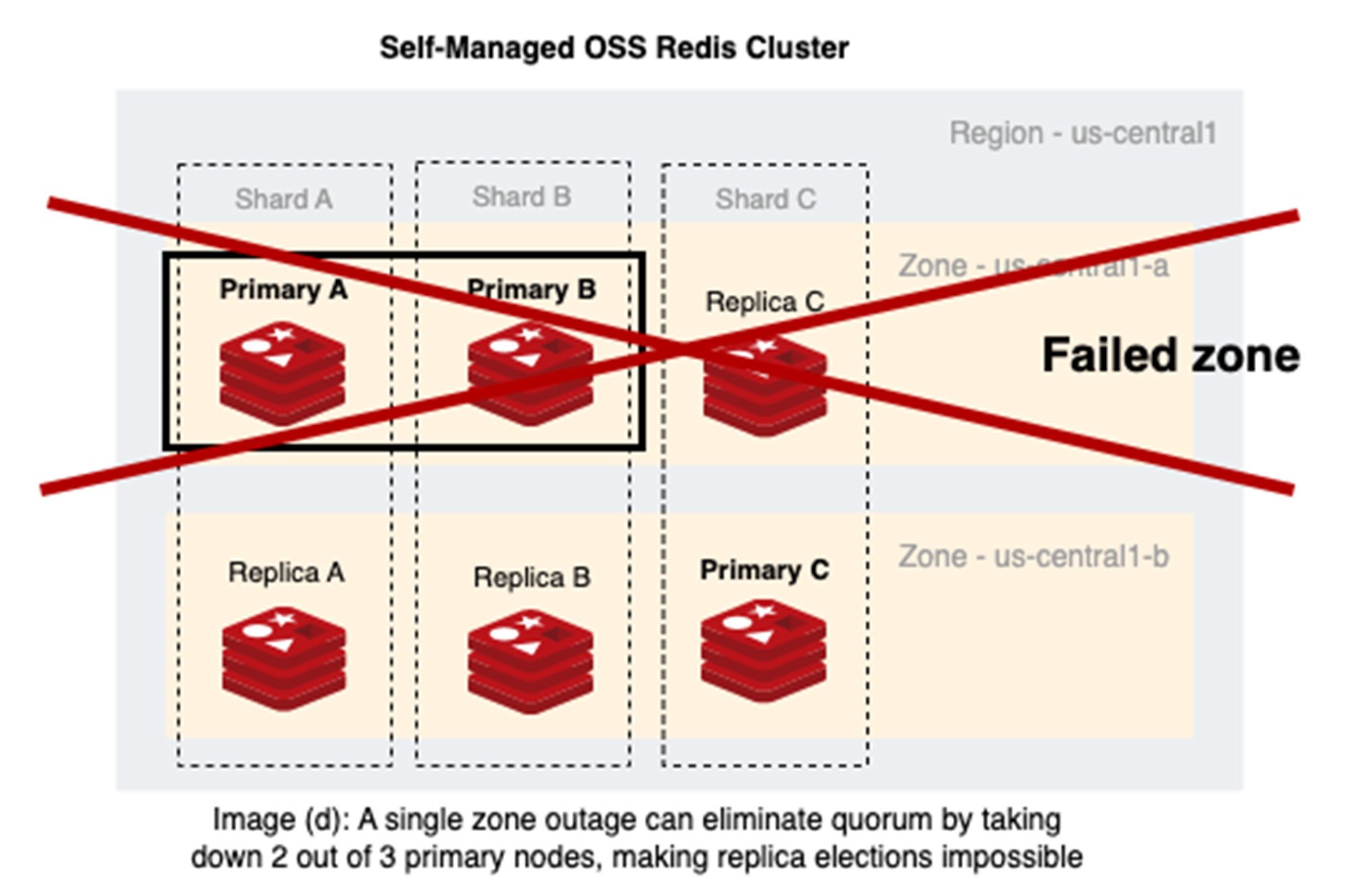
Scenario 1: Three Redis shards in a single Redis Cluster with nodes distributed across two zones: us-central1-a and us-central1-b
Image (d) observation: Two zone deployments of Redis Cluster are not resilient to a single-zone outage because a majority of primaries can fail during a single zone outage. Primary nodes in both zones us-central1-a and us-central1-b would be required (but unable) to make failover decisions.
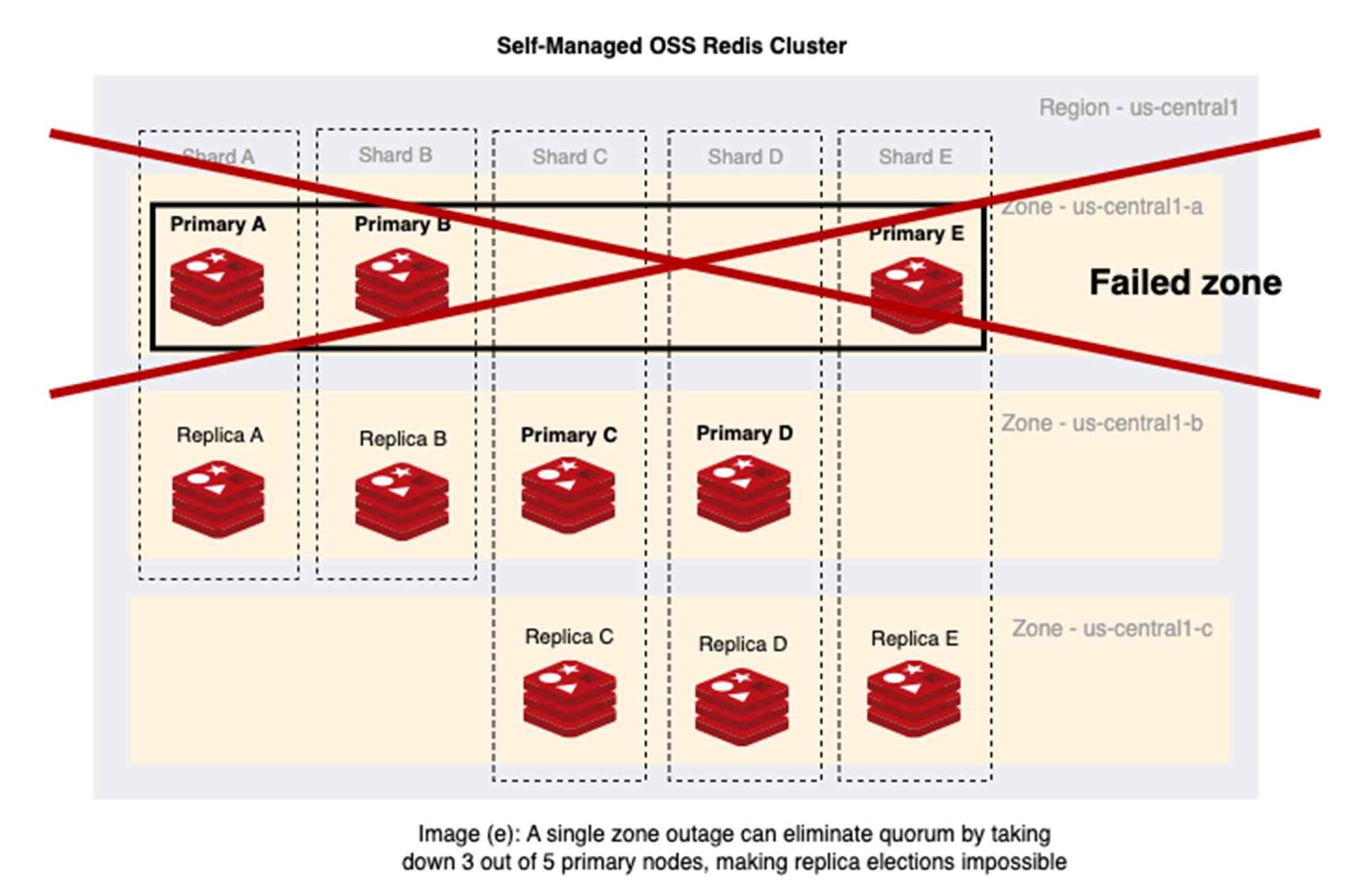
Scenario 2: Five Redis shards in a single Redis Cluster, nodes distributed across three zones: us-central1-a, us-central1-b, and us-central1-c
Image (e) observation: Allocating Redis nodes across three zones isn't enough protection if primaries and replicas are not distributed with a resilient design. Redis failovers can cause the OSS Redis Cluster to be unusable if a single zone outage takes down a majority of primary nodes.
- Zone us-central1-a has three out of the five primary nodes, for a 3:2:0 primary node distribution across three zones — three primary nodes in us-central1-a, two in us-central1-b, and none in us-central1-c.
- Even if Shard E primary role was bootstrapped in us-central1-c to balance nodes as 2:2:1, a single failover in Shard E would move the primary role to us-central1-a, skewing the distribution back to 3:2:0.
Self-managed deployments struggle with these scenarios since platform solutions like Compute Engine and GKE lack a construct for managing dynamic cluster topology. This can result in a majority of the primary nodes being affected by a single zone outage.
In contrast, Memorystore for Redis Cluster ensures that the quorum of primary nodes stays resilient to large scale outages using:
- A placement algorithm that distributes Redis shards across three zones, protecting quorum during a zonal outage
- A primary rebalancing algorithm that monitors and corrects primary node distribution, preventing concentration in a single zone, for enhanced resilience
Problem 2: Repairing failed infrastructure for Redis Clusters is error-prone
When a Redis Cluster’s underlying infrastructure fails, the challenges are twofold: recoverability of the cluster, and restartability of the Redis process.
Recoverability
To keep MTTR low, sustain capacity, and be prepared for the next failure, failed nodes must be quickly repaired. Restoring nodes is difficult and error-prone due to several factors:
- A self-managed OSS Redis Cluster needs an admin to manage node failures - maintain shard and slot assignments during the failure and restore them after recovery.
- Redis endpoints (IP addresses) can change after replacing infrastructure or rebooting Kubernetes Pod, which can both introduce inconsistencies in the Redis Cluster topology, as well as impact client applications (even when using Kubernetes StatefulSets).
- In a Kubernetes cluster, Redis nodes need permanent DNS names to handle IP changes. DNS dependencies increase MTTR due to delays in reconfiguring DNS, which can result in client outages. An advanced integration of Kubernetes with Redis' announce-ip feature is an alternative, but it adds complexity and manageability overhead.
- Furthermore, without an automated system, the Redis system administrator can easily become a single point of failure and/or face scaling challenges in Redis Clusters that have tens to hundreds of nodes, increasing the MTTR of the whole system.
Restartability
As described in the OSS guide, self-managed Redis Clusters are prone to cascading failures. A cascading failure is a failure that grows over time across failure domains as a result of positive feedback. This is in contrast to a correlated failure mode, where impact is limited to a failure domain defined by the underlying cause.
A primary node can unexpectedly restart as empty (data flushed) after a crash (perhaps due to an out-of-memory issue), which ends up wiping out its replicas due to the replication property. Cascading failure worsens the scope of impact of a Redis process crash and reduces the MTBF of the overall service.
Problem 2 solutions: Automated and reliable repairs
The main goal in repairing failed infrastructure at scale is to build a robust Redis-aware automated repair service, using three steps:
Step one: Smart restarts
To prevent a cascading failure scenario, Memorystore for Redis Cluster promotes an existing replica before initiating a restart on the primary node. Subsequently, the crashed primary assumes the role of an empty replica node and replicates the entire dataset from the new primary.
Step two: Repair automation
Memorystore for Redis Cluster provides a control-plane service to replace the OSS Redis system administrator requirements and bridge the reliability gaps in a robust and fully automated manner:
- The Memorystore for Redis Cluster control plane automatically repairs failed nodes at any scale, whether a single VM or an entire zone.
- The control plane reloads the required state of keyspace mappings and nodes to restore the service with the same endpoint (IP address), avoiding Redis Cluster topology churn.
Step three: High availability of the control plane
The Latin phrase "Quis custodiet ipsos custodes" asks "Who will guard the guards themselves?" In this case, we should ask, "What ensures the control plane's availability if it's in place to ensure cluster availability?" Automation brings the challenge of ensuring high availability not just to Redis Clusters, but also for the automated control plane used to manage Redis. The Memorystore for Redis Cluster control plane provides a robust workflow and state management with the following characteristics:
- Redundantly deployed across multiple cloud zones for high availability during large-scale outages
- Regional service with no single point of failure for other regions
- Isolated and provisioned separately from Redis data plane to scale independently for management operations
- Modularized provisioning and repair workflows improve reliability by isolating faults
Take-aways
In this blog, we highlighted the challenges of configuring highly available self-managed Redis Clusters. OSS Redis Cluster data partitioning (aka “sharding”) increases the burden of managing multiple nodes and ensuring that the nodes are provisioned correctly to withstand failures and maximize service availability. Specifically, some of the key availability challenges of OSS Redis Cluster are:
- Lack of failure-domain awareness
- Users running OSS Redis on GKE need to provision sophisticated pod affinity rules and ensure topology spread constraints. Even still, that doesn’t guarantee that the Redis primary nodes quorum will be able to withstand a single zone outage.
- Manual and error-prone repair processes for failed infrastructure, increasing MTTR
Memorystore for Redis Cluster employs a highly reliable and low-MTTR approach to high availability: pre-provisioning replicas. The key availability benefits of Memorystore for Redis Cluster are:
- Replication and distribution of Redis nodes across three failure domains (Google Cloud zones) to handle correlated infrastructure failures to achieve 99.99% availability
- Automatic failovers during Redis node failures or zonal outages
- A highly available control plane, reducing Redis system administration overhead and automatically repairing failed nodes at scale
Next steps
With Memorystore for Redis Cluster, you’re unlocking the true potential of a fully managed and highly available Redis Cluster that also provides zero-downtime scaling and microsecond latency. You can easily get started today by heading over to the Google Cloud console and creating a highly available Redis Cluster with just a few clicks. If you want to learn more about migrating to Memorystore for Redis Cluster, take a look at this step-by-step migration blog. Stay tuned for our next blog in this series of deep dives and let us know if you have any feedback by reaching out to us at cloud-memorystore-pm@google.com.


