Announcing Spanner Graph algorithms: Google-grade intelligence for connected data
Bei Li
Sr. Staff Software Engineer
Vahab Mirrokni
VP, Google Fellow, Graph Mining, Google Research
At Google Cloud Next, we announced the preview of graph algorithms with Spanner Graph, bringing Google Research’s state-of-the-art graph mining capabilities natively to your database. These graph intelligence capabilities can help you derive valuable insights from graph data faster, cheaper, and at scale.
Enterprises are increasingly leveraging graph technologies to uncover complex relationships in data for use cases such as fraud detection, social network analysis, entity resolution, and healthcare research. Graph algorithms, such as node centrality and community detection, are the computational methods used to analyze these structures, and work by quantifying the patterns and strength of connections between entities. However, running graph algorithms at scale has historically been challenging and resource-intensive, often requiring complex ETL pipelines to dedicated analytic solutions or risking the transactional performance of the graph database.
We designed Spanner Graph algorithms to tackle demanding enterprise workloads without compromising on the performance of your operational database. This architecture provides several distinct advantages:
-
Tight integration with GQL: Directly invoke algorithms using ISO Graph Query Language (GQL) to run structural analytics across your data. By sequentially weaving algorithms and standard queries together, Spanner Graph minimizes complex data movement to external engines, simplifying your architecture and accelerating time-to-insight.
-
Near-zero transactional impact and lower TCO: Algorithm execution happens on dedicated compute resources, so as not to impact live production traffic. Spanner automatically provisions resources and securely routes data via Data Boost without having to create a custom ETL pipeline. Pay only for what you use, avoiding expensive licensing and operational overhead of legacy solutions.
-
Global insights on billion-edge graphs in minutes: Built for scale and speed, our engine can run algorithms on graphs with tens of billions of edges within minutes. Encoding topologies in a dense format that’s optimized for random access enables high-performance structural analytics on massive datasets.
While Google Research has published several research papers, held workshops, and released open-source projects based on its graph mining tools (e.g., for multi-core clustering), this is the first time that they are widely available to Google Cloud customers. Let’s take a deeper look at graph algorithms, and how you can use them with Spanner Graph.
Algorithms: Deeper insights for connected data
When we first launched Spanner Graph, our goal was to reimagine graph data management with a native graph database experience within Spanner, Google’s highly scalable, distributed database. Spanner Graph unifies relational and graph models, allowing developers to query connected data using the ISO GQL, while also interoperating with Spanner's existing tabular, search, and vector capabilities. This allows you to build intelligent applications without creating complex data pipelines, duplicating data, or increasing security and governance risk.
Building on this foundation, Spanner Graph algorithms help you to extract even deeper insights from your connected data. Graph algorithms analyze the relationships and connections within data, revealing hidden patterns and insights that might be missed with traditional analytical methods. With this launch, you can analyze connectedness to, for example, detect fraud rings, conduct clustering for entity resolution, identify points of failure in complex networks, or recommend products based on the preferences of connected users.
We use graphs extensively at Google. In fact, many popular algorithms like PageRank, the foundational technology that powers Google Search, were invented here. With native algorithm support in Spanner Graph, we are bringing some of Google’s leading graph intelligence capabilities directly to Google Cloud customers, with a set of essential graph algorithms that help you easily uncover the hidden structures within your data:
-
Centrality: Pinpoint the most influential and central nodes within your network using betweenness centrality, closeness centrality, and PageRank.
-
Community detection: Automatically group highly connected entities to uncover hidden segments with label propagation, correlation clustering, modularity clustering, weakly connected components, and clique aggregator.
-
Similarity and path finding: Find optimal routes using set-to-set shortest paths, or measure node similarities using Jaccard, cosine, common neighbors, and total neighbors.
An integrated developer experience
You can invoke graph algorithms directly using GQL on the entire graph, subgraphs, or a select set of nodes and edges. Spanner offers an integrated workflow: results from graph algorithm runs can be written directly back to Spanner Graph. This lets you invoke algorithms and standard queries sequentially, using the output of one operation as input to the next. Additionally, you can also store results in Cloud Storage buckets.
Example: Uncovering the ringleader of a fraudulent network
Consider a scenario where you are analyzing financial transactions to combat money laundering. Fraudsters usually manipulate a set of “mule” accounts (intermediary accounts for money laundering) that interact with one another to collectively commit fraud. To capture the teamwork between detected and hidden mule accounts, anti-fraud experts usually resort to link analysis and community detection graph algorithms. Here’s how you can use algorithms and queries together in Spanner Graph to catch them.
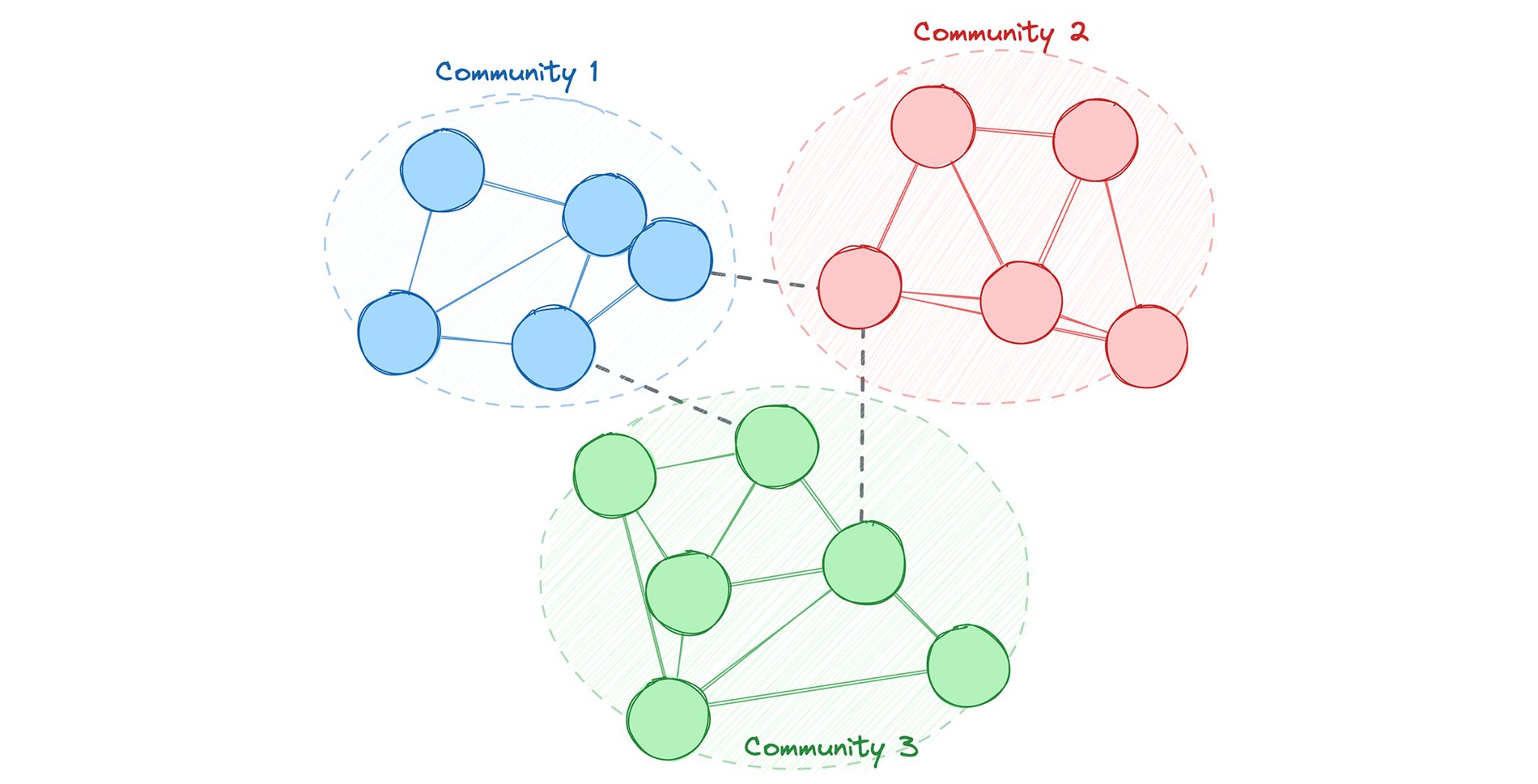
Step 1: Identify communities of accounts (algorithm)
First, we apply a modularity clustering algorithm to cluster accounts into communities. We then write the resulting community_id directly back to the Account in Spanner Graph.
Step 2: Pinpoint the suspicious community (query)
Now that every account belongs to a community, we can use a GQL query to perform analytical queries on each community to uncover anomalous behaviors. For example, we can check the total number of known fraud accounts within each community.
Step 3: Calculate influence to find the "ringleader" (algorithm on a subgraph)
Let's assume the query above reveals that Community 2 has seen a massive spike in fraudulent activity. In this step, we filter the graph to isolate only the accounts in that specific community and run the PageRank algorithm to find the central ringleader within that exact group.
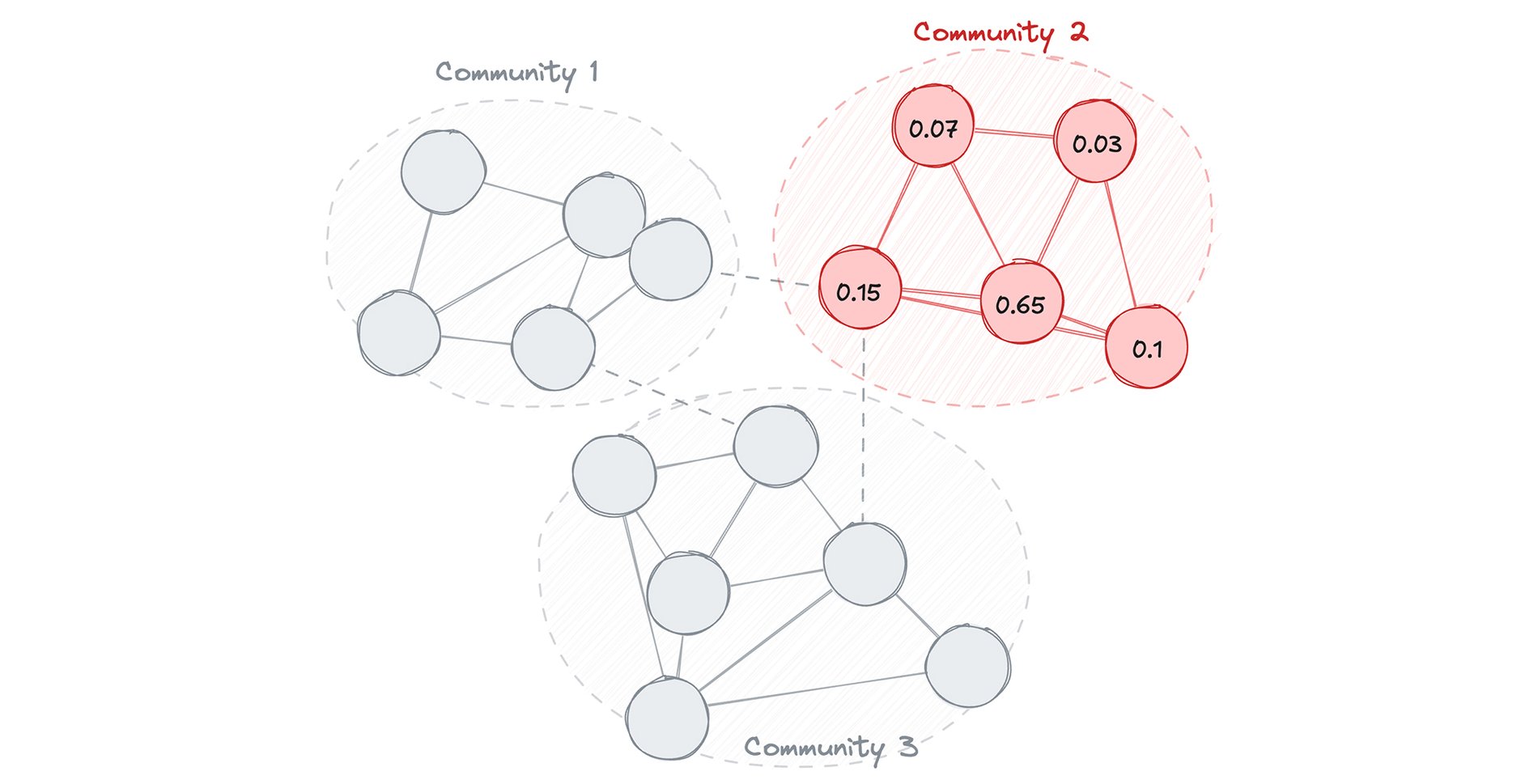
Step 4: Investigate the target (query)
Now that the accounts in Community 2 have a pagerank_score, we can write a query that isolates the most central account and that immediately traces where that specific ringleader moved their funds recently.
By allowing you to weave high-performance algorithms with standard GQL queries, Spanner Graph eliminates the need to move data back and forth between operational databases and external analytics engines. This unified approach dramatically simplifies your data architecture and accelerates your time to insight.
Trusted by industry leaders
Customers like DaVita, Yahoo!, SoundCloud, and WPP are already leveraging Spanner Graph algorithms to solve some of their most complex data challenges.
"Leveraging Spanner Graph for our Patient 360 initiative has allowed us to consolidate complex healthcare data into a single, unified view. The addition of native graph algorithms like community detection and centrality is a major step forward, enabling us to uncover deep insights within our patient networks faster and at scale. These fully managed capabilities allow our team to focus on driving innovation in patient care without the operational burden of managing complex data pipelines." - Sam Ghosh, Chief Enterprise Architect at DaVita Kidney Care
"Operating at global scale across Yahoo’s iconic consumer properties requires us to unify billions of user profiles into a single, real-time view. With Spanner Graph, we’ve modeled our Unified User Profile (UUP) as a graph, bringing together previously distributed systems into a centralized source of truth. The addition of fully managed graph algorithms on Spanner further accelerates our ability to deliver personalization at scale. By leveraging algorithms such as community detection and PageRank, we can drive deeper audience segmentation and power more relevant, engaging user experiences across our platform." - Chris James, Director of Engineering, Yahoo
"With 500+ million tracks from 40+ million artists across 190+ countries, SoundCloud is where emerging artists find their sound, hidden gems are discovered, and music culture is shaped in real time. We have been running graph algorithms in batch mode for years, with processes often taking multiple hours on custom clusters to analyze our massive, multi-billion-edge music graph. The launch of Spanner Graph algorithms is a true game-changer: It not only provides the massive scalability we need, but also allows us to move away from complex custom Python workflows to a fully managed service. Most importantly, it unlocks the ability to run graph algorithms on our most up-to-date data for use cases like identifying creator hubs and improving recommendations, without requiring complex ETL pipelines or impacting the low-latency transactional workloads running on Spanner today." - Sergey Chekanskiy, VP of Engineering - Data Foundation, SoundCloud
“We've been eager to leverage advanced graph algorithms for Open Intelligence, our foundational intelligence layer that securely connects trillions of live data points from clients, partners and WPP in a privacy-first way and that is now integrated and powers WPP’s agentic marketing platform, WPP Open. In order to have instant, exploratory access to complex relationships across billions of entities – driving planning, modelling, and experimentation — we need native support for deep graph traversal, structural pattern recognition, and advanced algorithms. Algorithm support on Spanner Graph provides the performance and scalability to tackle our most challenging graph analytics problems without operational overhead or expensive licensing." - Rob Marshall, Head of Strategy, Data & Intelligence, WPP
Build more intelligent applications
Now with native support for algorithms in Spanner Graph you can move beyond basic relationship traversals and run deep structural analytics directly on your freshest transaction data. By applying these classic graph algorithms at scale, you can unlock new capabilities for your enterprise applications:
-
Proactive fraud detection and anti-money laundering: Expose coordinated fraud rings by automatically grouping connected mule accounts with Community Detection (like modularity clustering), then apply centrality (like PageRank) to pinpoint the ringleader who controls the illegal fund flow.
-
Customer 360 and entity resolution: Unify fragmented, cross-channel data into a single canonical profile using similarity functions like Jaccard and community detection like label propagation. These profiles can be further enriched for downstream ML training by generating topological features, such as PageRank, for each node.
-
Autonomous network operations and digital twins: Model your IT or telecom infrastructure as a digital twin, using similarity and path finding (like set-to-set shortest path) to proactively identify critical vulnerabilities and predict cascading failures.
-
Hyper-personalized product recommendations: Move beyond basic purchase histories by analyzing broader user behaviors. Use similarity algorithms (like common neighbors) to find overlapping preferences between entities, and centrality (like personalized PageRank) to surface the most relevant recommendations for those peer groups.
-
Resilient supply chain and logistics: Protect your supply chain from hidden bottlenecks using centrality (like betweenness centrality) to pinpoint over-relied-upon distribution hubs, and path finding to instantly calculate efficient alternative routes during disruptions.
-
Cybersecurity threat hunting and blast-radius analysis: Accelerate threat hunting by applying community detection (like correlation clustering) to isolate anomalous machine communications, and path finding to trace the attacker's exact lateral movement and blast radius.
-
Predictive customer churn analysis: Stop contagious customer churn by mapping out tight-knit subscriber groups with community detection, then apply centrality to identify and target core influencers with retention promotions before the churn spreads.
Get started today
Spanner Graph algorithms are supported with the Enterprise and Enterprise+ editions of Spanner. To learn more, view the documentation or try out this codelab. You can also watch this video for a summary of graph algorithm support with Spanner Graph.


