Migrating from Cassandra to Bigtable at Latin America’s largest streaming service
Michel Henrique Aquino Santos
Software Engineer, Globo
Editor’s note: Today we hear from Grupo Globo, the largest media group in Latin America, which operates the Globoplay streaming service. This post outlines their migration from Apache Cassandra to Bigtable and learnings along the way.
Grupo Globo, Latin America’s largest media group, owns and operates Globoplay — a streaming service where users can access live TV broadcasts in addition to on-demand video and audio content. Since most of our users don’t consume content in one sitting, and switch between multiple devices, the ability for them to resume watching a title where they left off is a key capability for our service.
Our Continue Watching API (CWAPI) is an application written in Go that processes audio and video watched timestamps, a workload which consists of 85% write and 15% read requests. To handle such write traffic in a performant way, we historically relied on Apache Cassandra, which is known for its high write-throughput and low write latencies.
Initially, Cassandra was installed on physical machines in Globo's proprietary data center. Given the straightforward compatibility with their existing on-premises setup, a lift-and-shift approach to Compute Engine made the most sense at the time. Although the application functioned well in this setup, accommodating variations in user traffic required adding and removing nodes, a time-consuming practice, which ultimately resulted in over-provisioned clusters and drove up our infrastructure costs. Working with Cassandra also meant patching the software regularly, an often overlooked, but significant operational overhead.
We began the process of evaluating possible alternatives to replace Cassandra. We had read about how Bigtable was being used at YouTube, and we were encouraged to see that other streaming services like Spotify, had made the switch from Cassandra to Bigtable, realizing savings of up to 75%. That said, to be sure, we wanted to conduct our own evaluation using our own specific workloads and serving traffic.
We initially looked at "Cassandra as a Service" solutions on Google Cloud, which offered the convenience of lift-and-shift with no code changes. However, after benchmarking with our own data and running our load tests, we found that Bigtable was the best option for us. It had a lower cost of ownership and additional capabilities, even though it required more migration work than managed Cassandra in the cloud.
Why we chose Bigtable
Bigtable proved to be a strong alternative, mainly due to its characteristics of low latency at high read/write throughput, scalability to large volumes of data, resilience, built-in Google Cloud integrations, and having been validated by Google products with billions of users. Being a managed service, it also simplifies operation compared to self-managed databases. Capabilities such as high availability, data durability and security are guaranteed out-of-the-box.
Furthermore, multi-primary replication between globally distributed regions increases availability and guarantees faster access by automatically routing requests to the nearest region, which also helped us deliver read-your-writes consistency for our use case with ease. Bigtable provides native tools such as usage metrics dashboards and Key Visualizer, which helps find points for performance improvements by analyzing the pattern of access to keys. Data in Bigtable can also be queried from BigQuery without having to copy the data to the data warehouse.
Implementation, data migration and rollout
After deciding that Bigtable would be the best alternative to replace Cassandra, the team planned the migration in the following steps.
Porting Cassandra code to Bigtable
Bigtable provides a wide variety of client libraries, including Go. We focused on the code paths that write to the database first, which would allow us to migrate data between databases. Once writing was finished, we implemented the reading features and converted all Cassandra code to Bigtable without any issues. Tests were created to verify that each feature integrated properly with the rest of the system.
Enabling duplicate writing in both databases
To ensure that no new data would be lost during the migration, we enabled duplicate writing on both databases. We began by writing 1% of the data to each database, then gradually increased the percentage as we confirmed that there were no issues. This allowed us to validate how the database and application behaved without impacting the user, since Cassandra remained the primary database throughout the transition.
Data migration
We decided to create a pipeline using Dataflow to perform batch migration. Using Bigtable’s Dataflow template as our starting point, we found the approach easy to implement and very performant.
The script read a static file from the Cassandra dump, which was stored in a bucket on Cloud Storage. Each line of the file represented a line from the Cassandra table. The script then transformed the data for Bigtable and inserted it into the table. At the same time, CWAPI was writing new traffic to Bigtable.
After validating the script in the development environment, we prepared it for execution in production. Due to the large volume of data, we split the dump file into multiple files, each approximately 190 GB in size. This strategy reduced the likelihood of having to reprocess data in the event of an unexpected error during the execution of the Dataflow script.
Validating the migration
To validate the migration, we created a simple API that was deployed internally. This API exposed two ports, each with an endpoint that was equivalent in terms of parameters and response, but seeking data from its respective database: Cassandra and Bigtable.
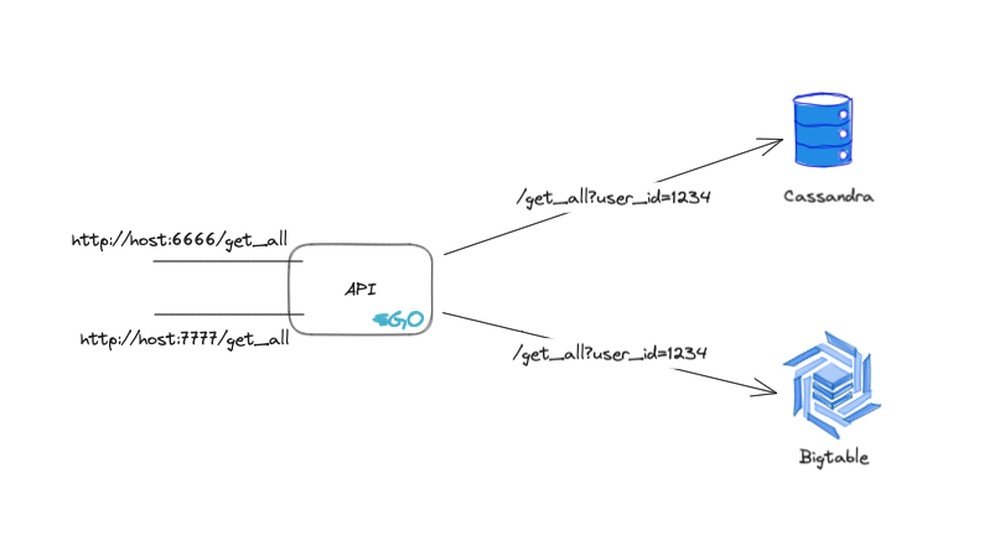
High-level architecture of the migration validation API
It is essential to emphasize that this API leveraged the code used in the integration of the two databases, eliminating the need for a new implementation that could differ from the production implementation.
This API was later used as a data source for Diffy, a tool that was initially built by Twitter and is now open source. We relied on Diffy to validate the migration. It finds potential bugs in your service by using instances of your new code and your old code side-by-side. Diffy behaves like a proxy and multicasts all the requests it receives to each of the running instances. It compares the responses and reports of any regressions that may arise from these comparisons.
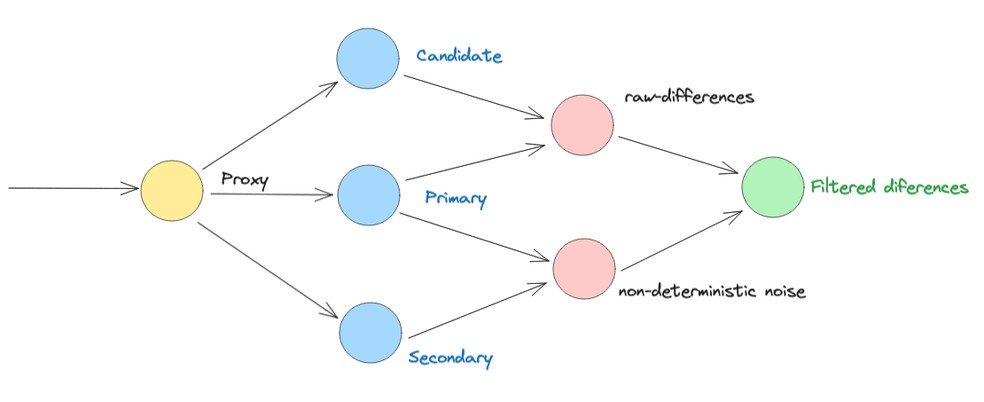
Diffy topology
We configured an instance of Diffy so that the two "primary" and "candidate" applications would be configured with the same validation application described above. The only difference is that the primary application uses the port for Cassandra, while the candidate application uses the port for Bigtable. This way, we can compare whether the migration was successful by comparing the same query in both databases.
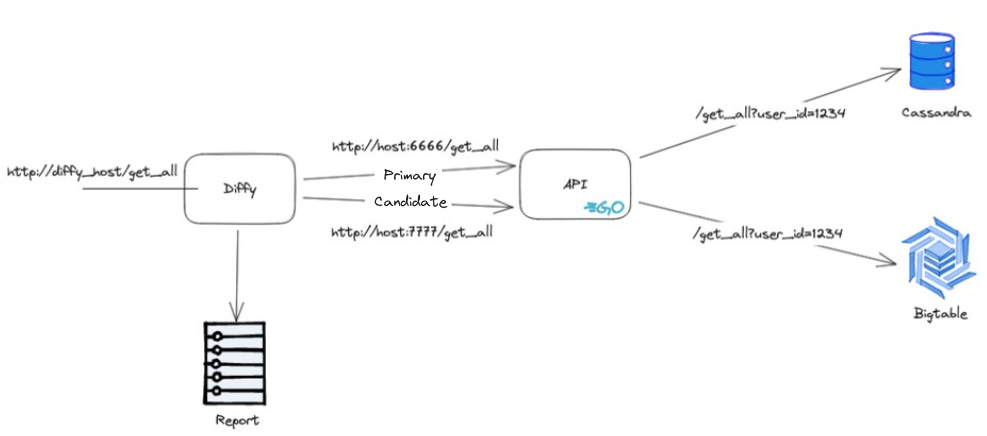
Diffy with validation API
With Cassandra data migrated to Bigtable and CWAPI saving 100% of the data in both databases, we needed to ensure the migration was done successfully to begin the Bigtable integration rollout.
The strategy was to duplicate a small percentage of GET requests to Diffy, which would consequently call the created validation application and generate a report with the differences. In order not to burden the Cassandra base that was serving requests in production, we decided to use a sampling of 1% of requests.
In the CWAPI architecture there is an instance of Nginx that acts as a reverse proxy, and we take advantage of this instance to duplicate GET requests. Two modules were essential for this to be achieved: split_clients and mirror. The split_clients module was used to control the percentage of requests that would be duplicated and the mirror used to duplicate the request.
Rollout
After validating that the migration was correct based on sampling and correcting some inconsistencies, the team was very confident in starting the rollout, as we were already using Bigtable extensively with 100% of the writing without any problems and with consistent data.
We then used the same deployment strategy for the serving path, starting with 1% and gradually increasing until we reached 100% of GET requests being served by Bigtable.
After a short "quarantine" period of approximately 15 days, we decommissioned our Cassandra servers.
Conclusion
The strategy used for this migration was of great importance in order to ensure there was no impact on the user. Writing into both databases allowed us to continue the integration and easily correct any problems. Diffy, together with the migration validation API, was essential to ensure that the migration was executed successfully and that user data was intact. The rollout of read requests after validation was done very smoothly as Bigtable was already under high server traffic and the data was validated. The well-abstracted CWAPI code, which is covered with unit, integration, and end-to-end tests, simplified implementation and gave us the necessary confidence that everything was correct.
Bigtable has proven to be a fantastic alternative to Cassandra, bringing forth several notable advantages. High availability and performance combined with autoscaling, allow us to operate reliably and at a lower cost compared to the Cassandra cluster. We have already achieved savings of approximately 60% without sacrificing performance or features. Additionally, we also migrated our Redis Stream-based queue solution to Pub/Sub. This transition not only enhanced the background processing capability of the application, boosting scalability and performance, but also contributed to more efficient maintenance and a notable reduction in operational costs.
Google Cloud has been a strategic choice in helping us deliver robust technological solutions and optimizing our financial resources. By migrating to Bigtable, we have decreased maintenance needs, guaranteed database scalability, acquired better observability tools and leveraged strong integrations with other Google Cloud products. We are excited to continue this partnership in simplifying database management in order to meet our business’ ever-evolving demands.
Learn more
Read more on how others are reducing cloud spend while improving service performance, scalability and reliability by moving to Bigtable:
- Wunderkind migrates from DynamoDB to Bigtable for improved performance stability
- Airship moves from Cassandra and HBase to Bigtable to reduce management overhead and improve performance reliability
- Reltio modernizes Cassandra workloads with Bigtable
- How Box migrated from HBase to Bigtable
- Choreograph scales advertising solutions by moving from Couchbase to Bigtable
Get started with a Bigtable free trial today.


