At Box, a game plan for migrating critical storage services from HBase to Cloud Bigtable

Mindy Yang
Senior Software Engineer, Box
Yamini Allu
Senior Staff SWE, Google Cloud
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialIntroduction
When it comes to cloud-based content management, collaboration, and file sharing tools for businesses and individuals, Box, Inc. is a recognized leader. Recently, we decided to migrate from Apache HBase, a distributed, scalable, big data store deployed on-premises, to Cloud Bigtable, Google Cloud’s HBase-compatible NoSQL database. By doing so, we achieved the many benefits of a cloud-managed database: reduced operational maintenance work on HBase, flexible scaling, decreased costs and an 85% smaller storage footprint. At the same time, the move allowed us to enable BigQuery, Google Cloud’s enterprise data warehouse, and run our database across multiple geographical regions.
But how? Adopting Cloud Bigtable meant migrating one of Box's most critical services, whose secure file upload and download functionality is core to its content cloud. It also meant migrating over 600 TB of data with zero downtime. Read on to learn how we did it, and the benefits we’re ultimately enjoying.
Background
Historically, Box has used HBase to store customer file metadata with the schema in the table below. This provides us a mapping from a file to a file’s physical storage locations. This metadata is managed by a service called Storage Service, which runs on Kubernetes; this metadata is used on every upload and download at Box. For some context on our scale: at the start of the migration we had multiple HBase clusters that each stored over 600 billion rows and 200 terabytes of data. Additionally, these clusters received around 15,000 writes per second and 20,000 reads per second, but could scale to serve millions of requests for analytical jobs or higher loads.
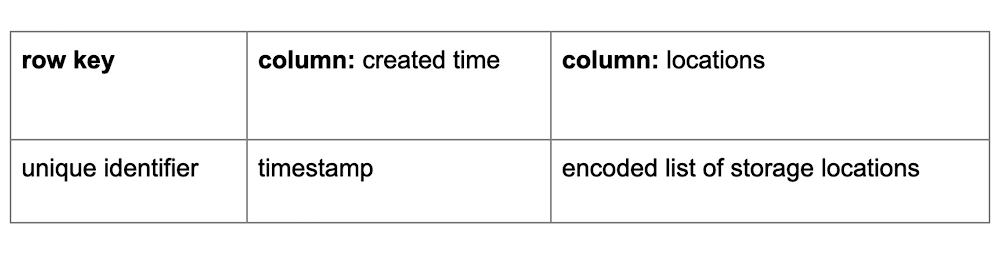
Our HBase architecture consisted of three fully replicated clusters spread across different geographical regions: Two active clusters for high availability, and another to handle routine maintenance. Each regional Storage Service wrote to its local HBase cluster and those modifications were replicated out to other regions. On reads, Storage Service first fetched from the local HBase cluster and fell back onto other clusters if there was a replication delay.
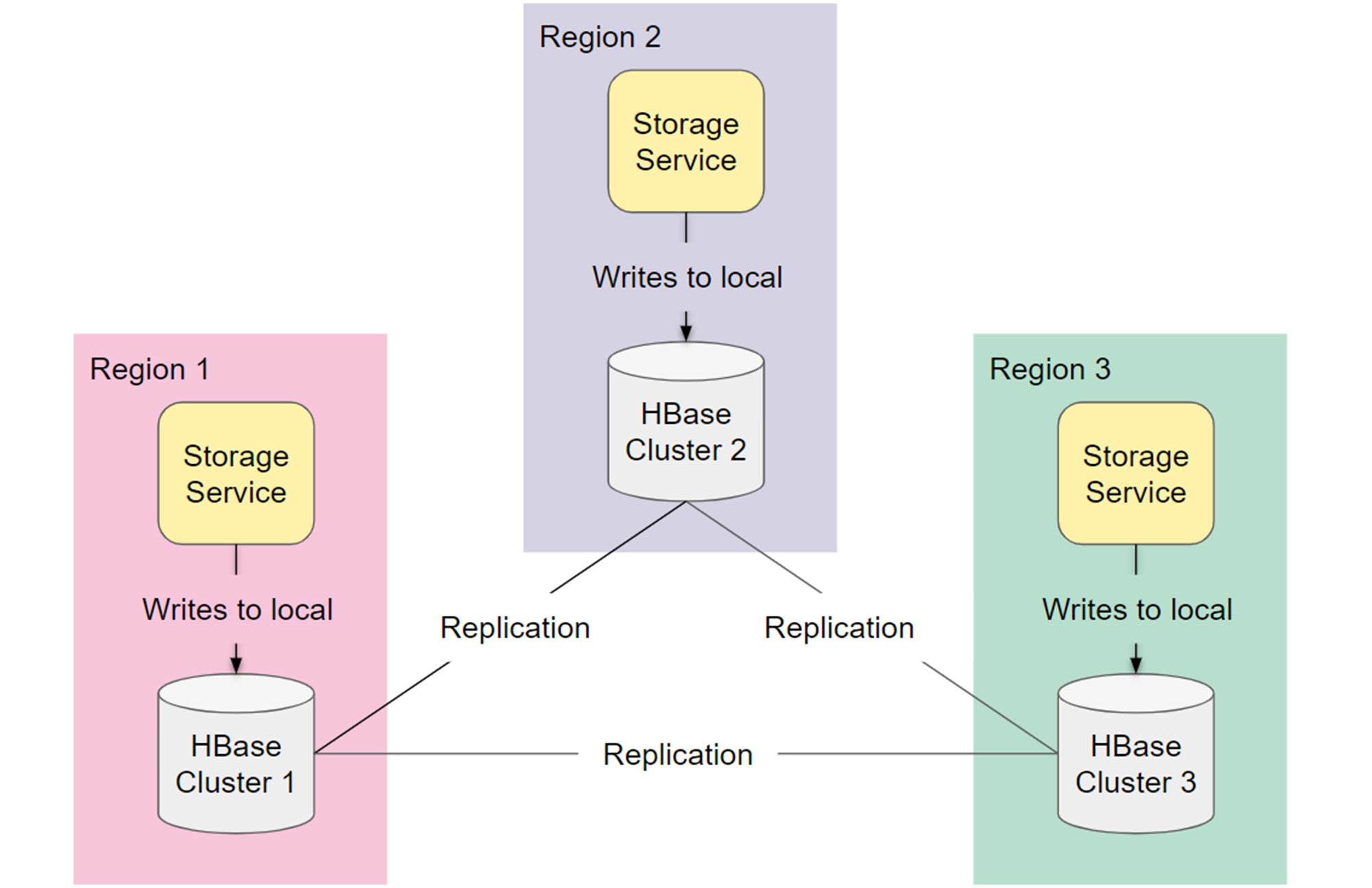
Preparing to migrate
To choose the best Bigtable cluster configuration for our use case, we ran performance tests and asynchronous reads and writes before the migration. You can learn more about this on the Box blog here.
Since Bigtable requires no maintenance downtime, we decided to merge our three HBase clusters down to just two Bigtable clusters in separate regions for disaster recovery. That was a big benefit, but now we needed to figure out the best way to merge three replicas into two replicas!
Theoretically, the metadata in all three of our HBase clusters should have been the same because of partitioned writes and guaranteed replication. However, in practice, metadata across all the clusters had drifted, and Box’s Storage Service handled these inconsistencies upon read. Thus, during the backfill phase of the migration, we decided to take snapshots of each HBase cluster and import them into Bigtable. But we were unsure about whether to overlay the snapshots or to import the snapshots to separate clusters.
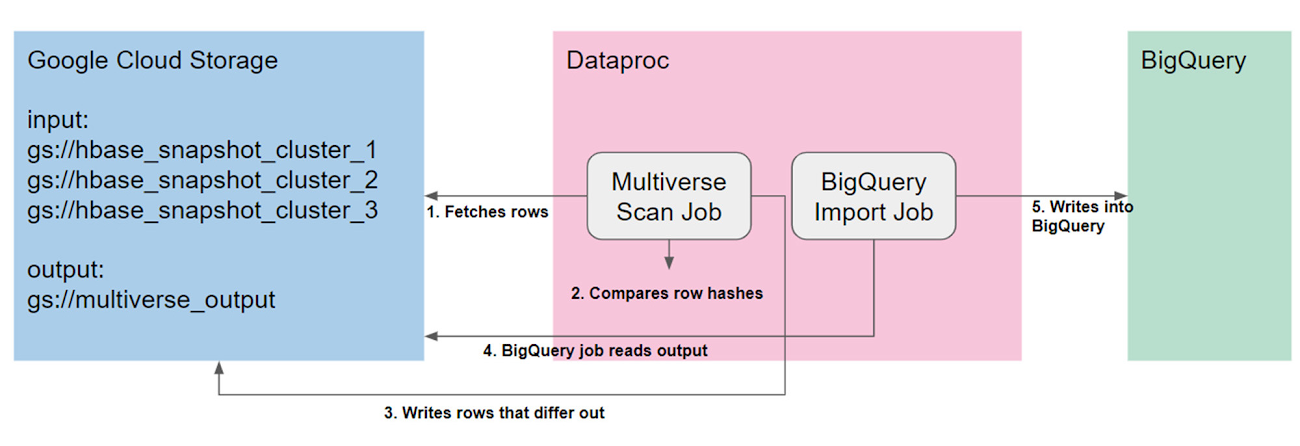
To decide on how to merge three clusters to two, we ran the Google-provided Multiverse Scan Job, a customized MapReduce job that sequentially scans HBase table snapshots in parallel. This allowed us to effectively perform a sort-merge-join of the three tables and compare rows and cells for differences between the three HBase clusters. While the job scanned the entire table, a random 10% of critical rows were compared. This job took 160 Dataproc worker nodes and ran for four days. Then, we imported the differences into BigQuery for analysis.
We found that inconsistencies fell into three categories:
Missing rows in an HBase cluster
A row existed, but was missing columns in an HBase cluster
A row existed, but had differing non-critical columns in an HBase cluster
This exercise helped us decide that consolidating all three snapshots into one would provide us with the most consistent copy, and to have Bigtable replication handle importing the data into the secondary Bigtable cluster. This would resolve any issues with missing columns or rows.
Migration plan
So, how do you migrate trillions of rows into a live database? Based on our previous experience migrating a smaller database into Bigtable, we decided to implement synchronous modifications. In other words, every successful HBase modification would result in the same Bigtable modification. If either step failed, the overall request would be considered a failure, guaranteeing atomicity. For example, when a write to HBase succeeded, we would issue a write to Bigtable, serializing the operations. This increased the total latency of writes to the sum of a write to HBase and Bigtable. However, we determined that was an acceptable tradeoff, as doing parallel writes to both these databases would have introduced complex logic in Box’s Storage Service.
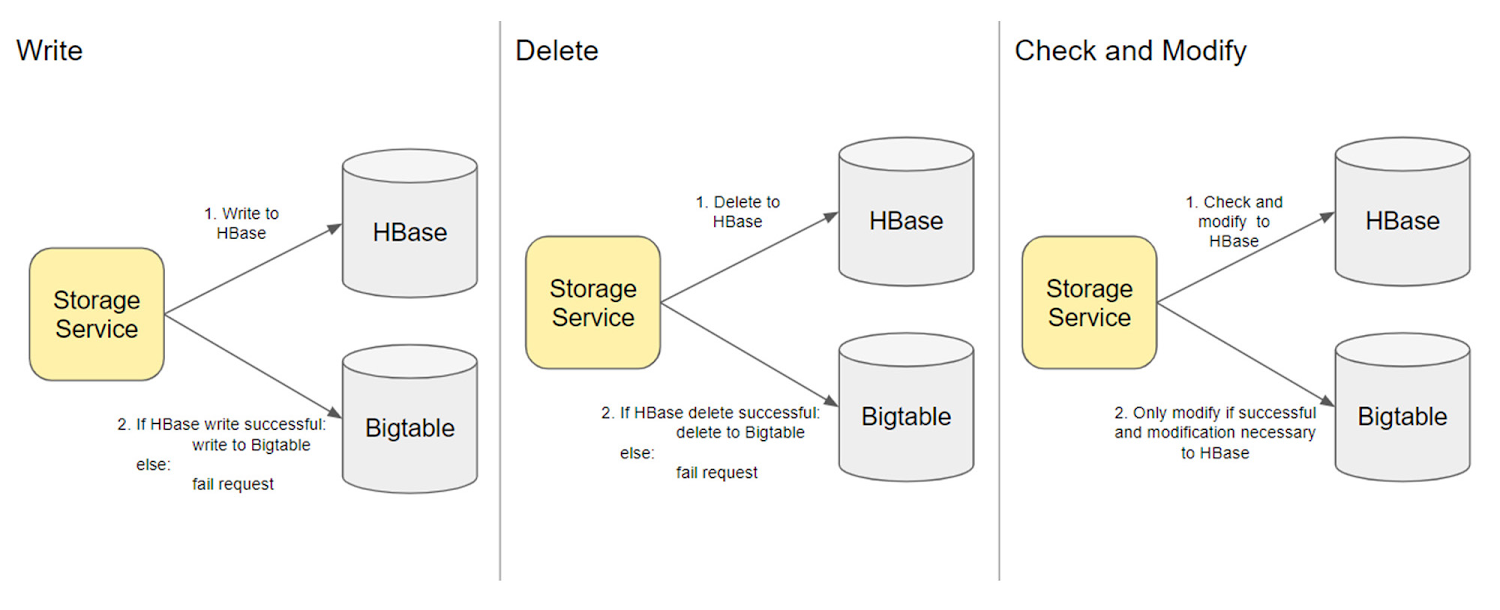
One complexity was that Box’s Storage Service performed many check-and-modify operations. These couldn’t be mirrored in Bigtable for the duration of migration where Bigtable had not been backfilled, and consequently check-and-modify operations would differ from the HBase check-and-modifies. For this reason, we decided to rely on the result of the HBase check-and-modify, and would only perform the modification if the HBase check-and-modify succeeded.
Rollout plan
To roll out synchronous modifications safely, we needed to control it by both percentage and region. For example, our rollout plan for a region looked like the following:
- 1% region 1
- 5% region 1
- 25% region 1
- 50% region 1
- 100% region 1
Synchronous modifications ensured that Bigtable had all new data written to it. However, we still needed to backfill the old data. After running synchronous modifications for a week and observing no instabilities, we were ready to take the three HBase snapshots and move onto the import phase.
Bigtable import: Backfilling data
We had three HBase snapshots of 200TB each. We needed to import these into Bigtable using the Google-provided Dataproc Import Job. This job had to be run carefully since we were fully dependent on the performance of the Bigtable cluster. If we overloaded our Bigtable cluster, we would immediately see adverse customer impact — an increase in user traffic latency. In fact, our snapshots were so large that we scaled up our Bigtable cluster to 500 nodes to avoid any performance issues. We then began to import each snapshot sequentially. An import of this size was completely unknown to us so we controlled the rate of import by slowly increasing the size of the Dataproc cluster and monitoring Bigtable user traffic latencies.
Validation
Before we could start relying on reads from Bigtable, there was a sequence of validations that had to happen. If any row was incorrect, this could lead to negative customer impact. The size of our clusters made it impossible to do validation on every single row. Instead we took three separate approaches to validation to gain confidence on the migration:
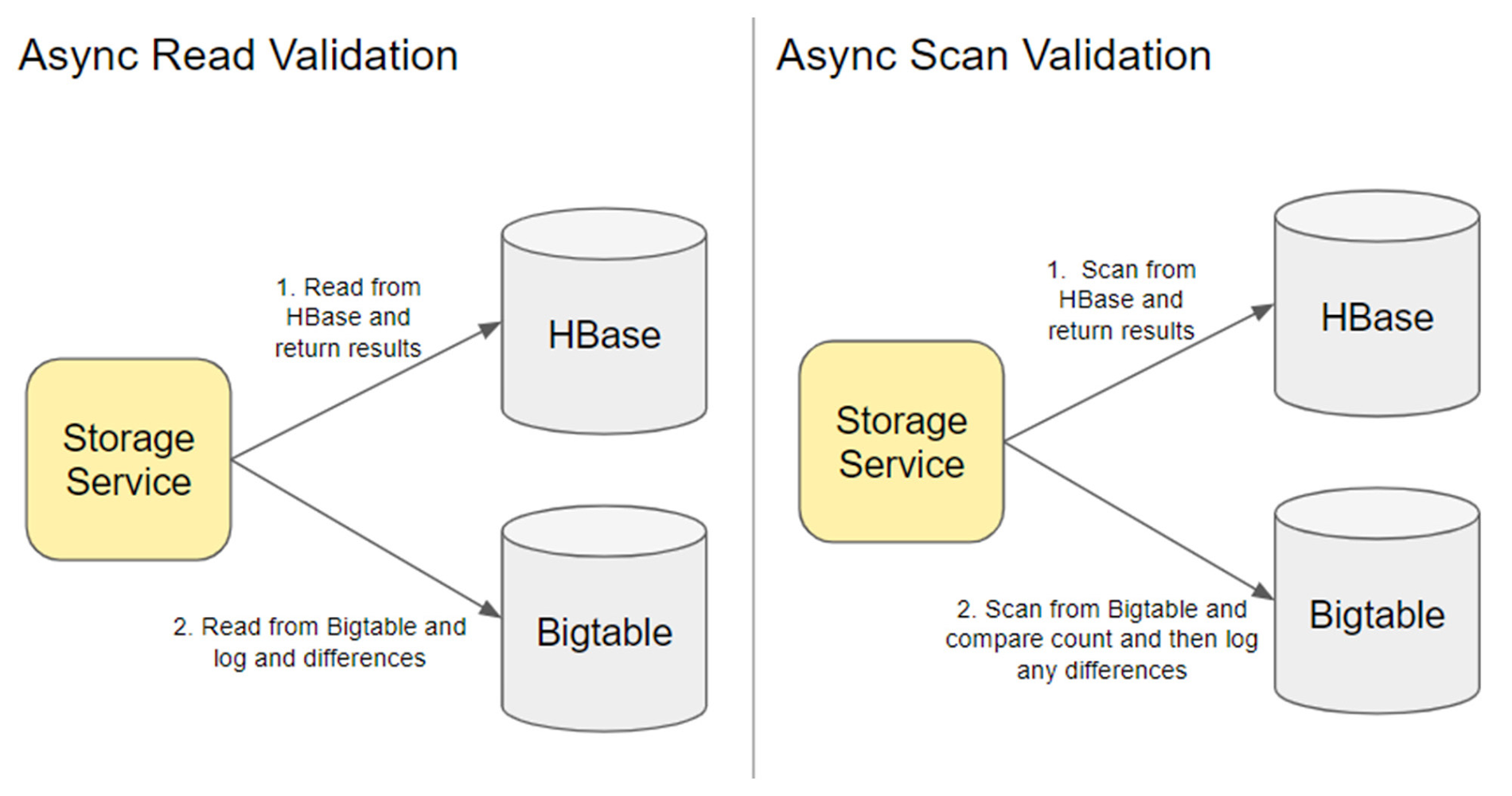
1. Async read validation: Optimistic customer-download-driven validation
On every read, we asynchronously read from Bigtable and added logging and metrics to notify us of any differences. The one caveat with this approach was that we have a lot of reads that are immediately followed by an update. This approach created a lot of noise, since all of the differences we surfaced were from modifications that happened in between the HBase read and the Bigtable read.
During this read validation we discovered that Bigtable regex scans were different from HBase regex scans. For one, Bigtable only supports “equals” regex comparators. Also, the Bigtable Regex uses RE2 which treats “.” (any character, which unless specified excludes newline) differently than HBase. Thus, we had to roll out a specific regex for Bigtable scans and validate that they were returning the expected results.
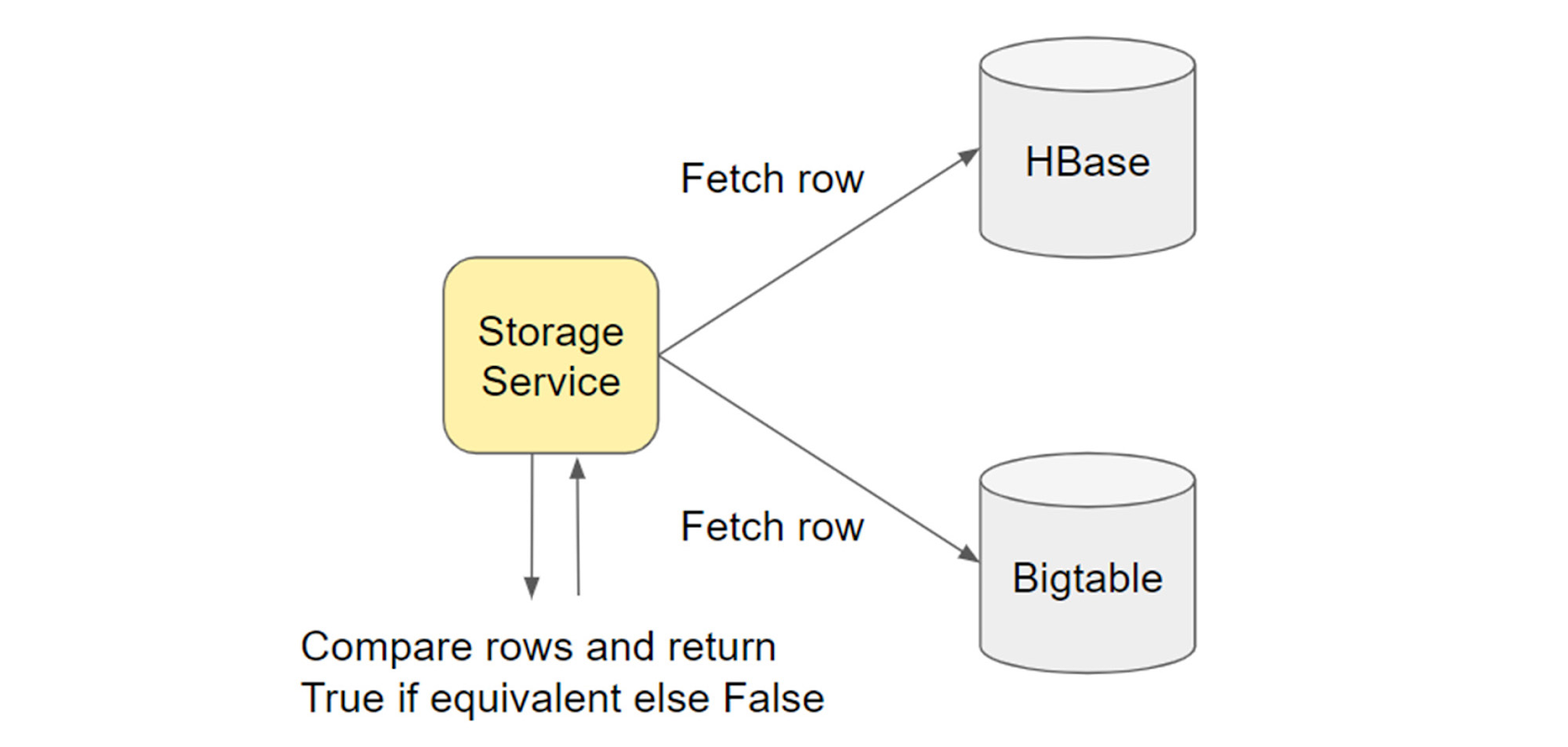
2. Sync validation: Run a Dataproc job with hash comparison between Bigtable and HBase
This validation job, similar to the one found here, performed a comparison of hashes across Bigtable and HBase rows. We ran it on a sample of 3% of the rows and uncovered a 0.1% mismatch. We printed these mismatches and analyzed them. Most of these mismatches were from optimistic modifications to certain columns and found that no re-import or correction was needed.
3. Customer perspective validation
We wanted to perform an application-level validation to see what customers would be seeing instead of a database-level validation.
We wrote a job to scan the whole filesystem that would queue up objects where we would call an endpoint in Storage Service that would compare the entry in Bigtable and HBase. For more information, check out this Box blog.
This validation supported the output of the Sync Validation job. We didn’t find any differences that weren’t explained above.
Flipping to Bigtable
All these validations gave us the confidence to return reads from Bigtable instead of HBase. We kept synchronous dual modifications to HBase on as a backup, in case we needed to roll anything back. After returning only Bigtable data, we were finally ready to turn off modifications to HBase. At this point Bigtable became our source of truth.
Thumbs up to Bigtable
Since completing the migration to Bigtable, here are some benefits we’ve observed.
Speed of development
We now have full control of scaling up and down Bigtable clusters. We turned on Bigtable autoscaling, which automatically increases or decreases our clusters given CPU and storage utilization parameters. We were never able to do this before with physical hardware. This has allowed our team to develop quickly without impacting our customers.
Our team now has much less overhead related to managing our database. In the past, we would constantly have to move around HBase traffic to perform security patches. Now, we don’t need to worry about managing that at all.
Finally, MapReduce jobs that would take days in the past now finish under 24 hours.
Cost savings
Before Bigtable, we were running three fully replicated clusters. With Bigtable, we are able to run one primary cluster that takes in all the requests, and one replicated secondary cluster that we could use if there were any issues with the primary cluster. Besides, for disaster recovery, the secondary cluster is extremely useful to our team to run data analysis jobs.
Then, with autoscaling, we can run our secondary cluster much more lightly until we need to run a job, at which point it self-scales. The secondary cluster runs with 25% less nodes than the primary cluster. When we used HBase, all three of our clusters were sized evenly.
New analysis tools
We ported all our HBase MapReduce jobs over to Bigtable, and found that Bigtable has provided us with parity in functionality with minor configuration changes to our existing jobs.
Bigtable has also enabled us to use the Google Cloud ecosystem:
We were able to add Bigtable as an external BigQuery source. This allowed us to query our tables in real time, which was never possible in HBase. This application was best suited to our small tables. Care should be taken with running queries on a production Bigtable cluster due to impact on CPU utilization. App profiles may be used to isolate traffic to secondary clusters.
For our larger tables we decided to import them into BigQuery through a Dataproc job. This enabled us to pull ad hoc analytics data without running any extra jobs. Further, querying BigQuery is also much faster than running MapReduce jobs.
Long story short, migrating to Bigtable was a big job, but with all the benefits we’ve gained, we’re very glad we did!
Considering a move to Bigtable? Find more information about migrations and Google Cloud supported tools:
Learn about our live migration tools such as HBase Replication and the HBase mirroring client
Walk through the migration guide for step-by-step instructions
Watch Box’s presentation, How Box modernized their NoSQL databases with minimal effort and downtime


