Google Cloud Memorystore for Redis Best Practices - Tips for a highly performant and worry-free deployment
Winston Douglas
Data Management Engineer, Google Cloud
Jason Massie
Customer Engineer, Data Management
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialPractices
Tips for a Highly Performant and Worry-free Deployment
Memorystore is a fully managed implementation of the open source in-memory databases Redis and Memcached. Memorystore makes it easy to build applications on Google Cloud to leverage in-memory stores based on open source Redis and Memcached.
Many applications deployed in the cloud today use an in-memory data store. Some example use cases include caching, real-time analytics, session store, leaderboard, queues, and for fast data ingestion. Redis and Memcached are popular choices by developers for these applications in cases where sub-millisecond latencies are required. We will focus on Memorystore for Redis in this blog.
Although Memorystore for Redis is a managed service, there are still best practices to follow depending on your application behavior and use case. The following best practices recommendations will help ensure the best possible experience for your use case.
Configuration settings and metrics to optimize memory settings
One of the most important settings in Memorystore for Redis is maxmemory-gb. This setting configures the maxmemory setting in Redis which dictates how much memory is reserved for key storage. The eviction policy is used when the maximum amount of memory specified is reached. Eviction policy is set in Memorystore for Redis by a maxmemory policy. The default policy is volatile-lru which evicts the least-frequently-used keys that are set with time to live (TTL) expirations.
Best practice:
As you tune maxmemory-gb, you should monitor system memory usage ratio (SMUR) with a target ratio below 80%. If the system memory usage ratio metric exceeds 80%, this indicates that the instance is under memory pressure. If you do not act and your memory usage continues to grow, you risk an instance crash due to insufficient memory. To prevent OOM errors, you may consider turning on activedefrag, lowering maxmemory-gb to provide more overhead for system usage, or scaling up the instance. Further details can be found here.
Use Redis 6 or higher for improved performance due to multithreading
One of the new features introduced with Redis 6 is the implementation of multi-threaded I/O. Previous versions of Redis have been single threaded which, in some cases, could lead to bottlenecks as I/O and the Redis engine shared a single vCPU. Because of this, the benefits of multiple vCPU configurations would be unrealized. Memorystore for Redis has enabled I/O multithreading for all instances running version 6 and higher which allows the use of multiple vCPUs to process I/Os simultaneously and increases instance throughput. Keep in mind that because of multi-threading, it is possible that the CPU seconds metric can burst to over 1 second suggesting over 100% utilization as it is an aggregated metric.
Memorystore for Redis provides different capacity tiers. The capacity tier size determines the single node performance and the number of I/O threads for Redis 6.
The table below describes the different capacity tiers and I/O threads for each in relation to the Redis version. Multi-threading for Redis 6 and higher requires the M3 capacity tier and higher.
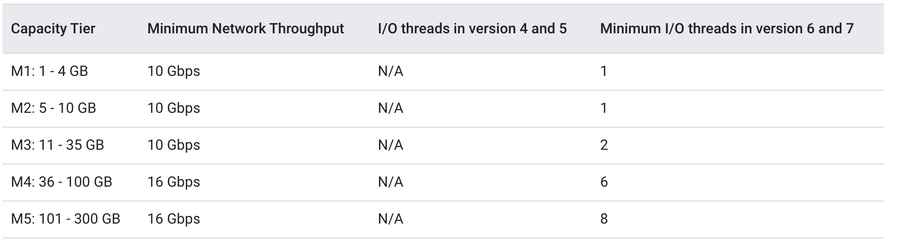
Note: with Redis 6 multithreading, CPU utilization may be observed bursting over 100% . This indicates that the instance is using multiple cores. For example, for an M4 instance with 6 threads, CPU utilization may burst to as high as 600% indicating utilization of all 6 cores.
Best practice:
We recommend deploying all newly created instances with Redis 6 and higher to leverage the benefits of multi-threading. If performance and throughput are critical for your instance, we recommend deploying with an M3 tier or higher instance. We also recommend upgrading existing Memorystore for Redis instances. It is usually trivial and safe as Redis aims to make the API backwards compatible, but we always suggest proper testing before any upgrades are attempted.
In addition to Redis 6’s multi-threading, you can also achieve significant performance gains by adding Read Replicas to your instance. Each additional read replica linearly scales total read throughput with up to 5 read replicas supported.
You can learn more about Memorystore for Redis Read Replicas and Redis version 6 here.
Configure maintenance windows for smooth operations
Memorystore automatically updates your instances. These updates are essential to maintain security, performance, and high availability of your instances and is one of the many benefits of it being a fully managed service.
Memorystore for Redis offers you the ability to define maintenance windows which are 1 hour time slots on a specific day of the week during which maintenance should be performed. Configuring a maintenance window gives you predictability of when maintenance may occur. If maintenance windows are not configured for an instance, maintenance may be performed at any time and on any day. This means maintenance could possibly occur during peak usage hours for your application.
Best practice:
We recommend the following as best practices for maintenance window on Memorystore for Redis to reduce and minimize the impact of maintenance and have the best maintenance experience:
You should set a maintenance window for your instances so that maintenance will not occur during peak activity and will only occur during low usage hours (eg: Early Sunday morning).
You should opt-in to maintenance notifications to be alerted by email at least seven days before a maintenance update is scheduled for your instance.
Ensure that the System Memory Usage Ratio metric is below 50% when maintenance starts. You can do this by scheduling for a time when instance traffic is low, or by temporarily scaling up your instance size during the maintenance window.
Consider Standard Tier for the lowest impact. Basic tier instances are unavailable during maintenance which may last up to 5 minutes.
Details on setting Maintenance Windows and more information can be found in the documentation here.
Configure Memorystore high availability when cache data is critical
Memorystore is available in two tiers, Basic tier and Standard tier. Basic tier consists of a single node with an ephemeral cache and no replication. A basic tier failure can cause a loss of cache date as there is no backup or replication. Standard tier provides high availability (HA) and 99.9% availability SLA with replication and will automatically failover to a replica if the primary node fails. This HA feature will provide your applications with more reliable and consistent access to critical cache data even in the event of a failure. The instance will be temporarily unavailable for a few seconds while the failover takes place and connections are established to the replica now turned primary.
Memorystore for Redis Standard Tier can have as many as five read replicas for High Availability and scale. Read replicas are not enabled by default . Once enabled, in addition to providing High Availability, they allow you to scale your read workload and provide a single read endpoint that distributes queries across all replica nodes.
Best practice:
For applications which cannot tolerate a full cache flush, Standard Tier is the recommended deployment tier. Additional data durability can be achieved by leveraging RDB snapshots.
Details can be found in the documentation on Memorystore high availability and tiers.
Avoid these Redis Commands and anti-patterns
Avoid these Redis Commands and anti-patterns to get the best performance and security for your instance and to optimize cost.
Using the KEYS command - Using the KEYS command may significantly impact the performance of your instance when used on a large database.
Best practice is to exercise caution and avoid using the KEYS command in a production environment. Alternative to using the KEYS command is to use the SCAN command instead.
Avoid commands that return unbounded results - Certain commands like LRANGE, HGETALL, ZRANGE can return very large amounts of keys and data which will adversely affect the performance of your server.
Best practice is to check the sizes of data structures with supporting commands to ensure that sizes are not too large
Redis as a persistence tier without High Availability or RDB Snapshots - Memorystore Redis data will be lost in the event of an instance failure if it is not configured with High Availability or regularly scheduled RDB Snapshots.
Best practice is that you use high availability with the Standard Tier and RDB Snapshots for data that is critical or in cases where the application depends on some level of persistence in Memorystore for Redis.
Implement exponential backoff in client connection logic
Exponential backoff is a standard error handling strategy. It works by retrying failed requests with increasing yet randomized delay. This can help mitigate scenarios where a transient increase in latency results in a high volume of requests due to users hitting refresh or a high backlog of incoming requests.
Randomization is a key component of the retry strategy. Each retry increases in time but there also needs to be some random variation so there will not be large waves of simultaneous retries. The random variability can typically range between 1-1000 milliseconds.
The retry strategy should include a maximum backoff so retries do not wait more than 32 or 64 seconds and eventually fail so retries are not infinite.
Best practice:
The best practice is to develop retry logic with a slightly random but increasing backoff. It should eventually time out and notify the application team by an alerting mechanism. Note that some form of this may already be implemented in some redis clients.
Configuring Alerting / Monitoring
Monitoring and alerting are important features of Google Cloud. Monitoring allows us to watch specific metrics over time to evaluate the health of our architecture. They are also useful in troubleshooting specific issues in realtime and historically. Alerting can notify you when an issue occurs based on thresholds you set.
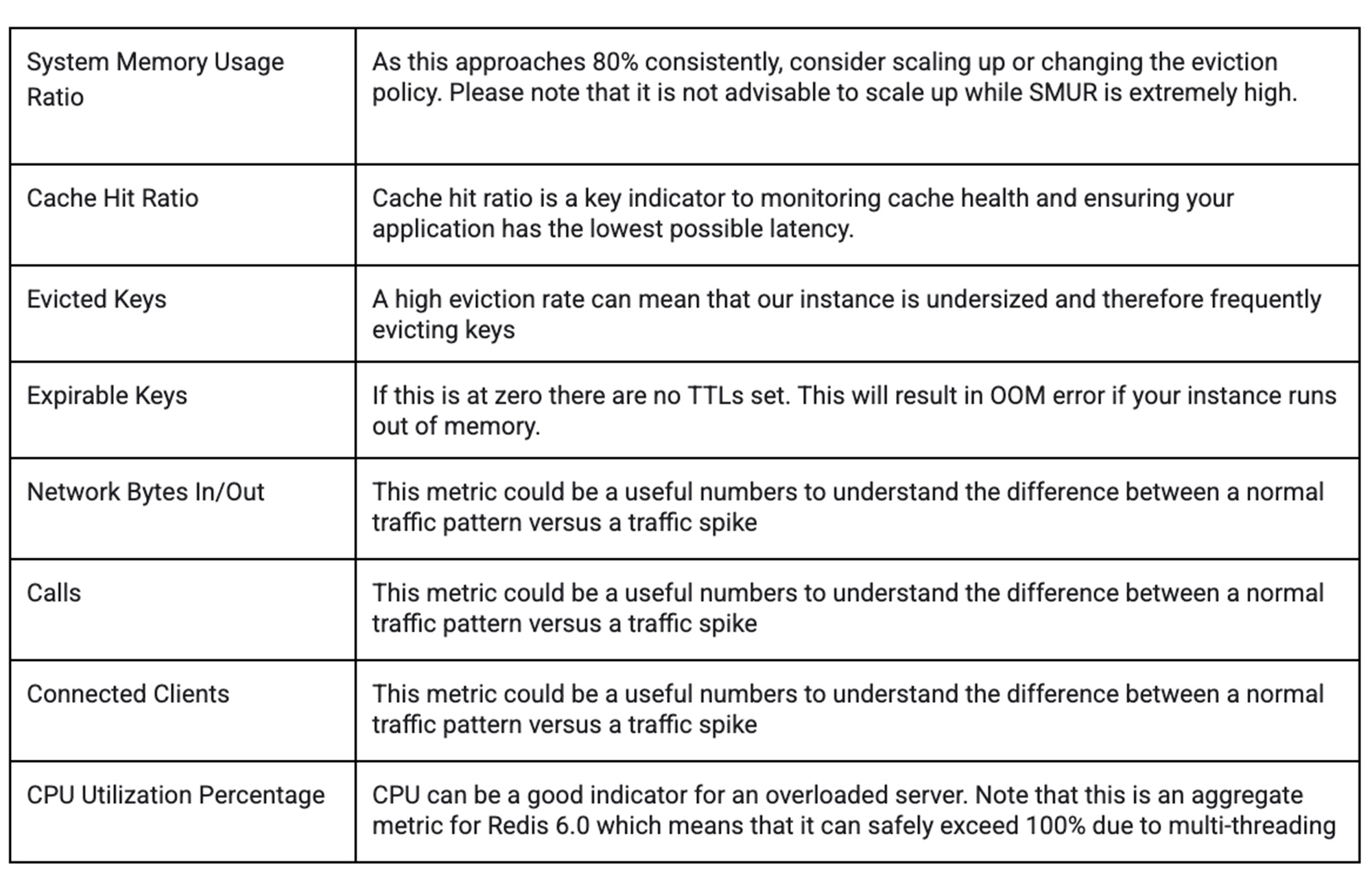
We recommend setting alerts on some key metrics below like SMUR and uptime. These should be customized by your application patterns to catch problems but minimize false alerts.
Common metrics to monitor
Deploy your applications on Memorystore for Redis with confidence today
Memorystore is a fully managed, highly available, highly performing, scalable and secure service for Redis. With Memorystore for Redis you are not burdened by the complexity of managing Redis software. This document highlights the best practices and features that will accelerate your deployment and run your applications on Memorystore for Redis with confidence. With these recommendations your applications and users will experience the highest level of performance and reliability.
Get started with Memorystore for Redis and learn more about Read Replicas, High Availability, and Maintenance.



